
Click the “blue text” above to follow for more exciting content.
This article contains a total of 900 words, and it takes about 2 minutes to read.
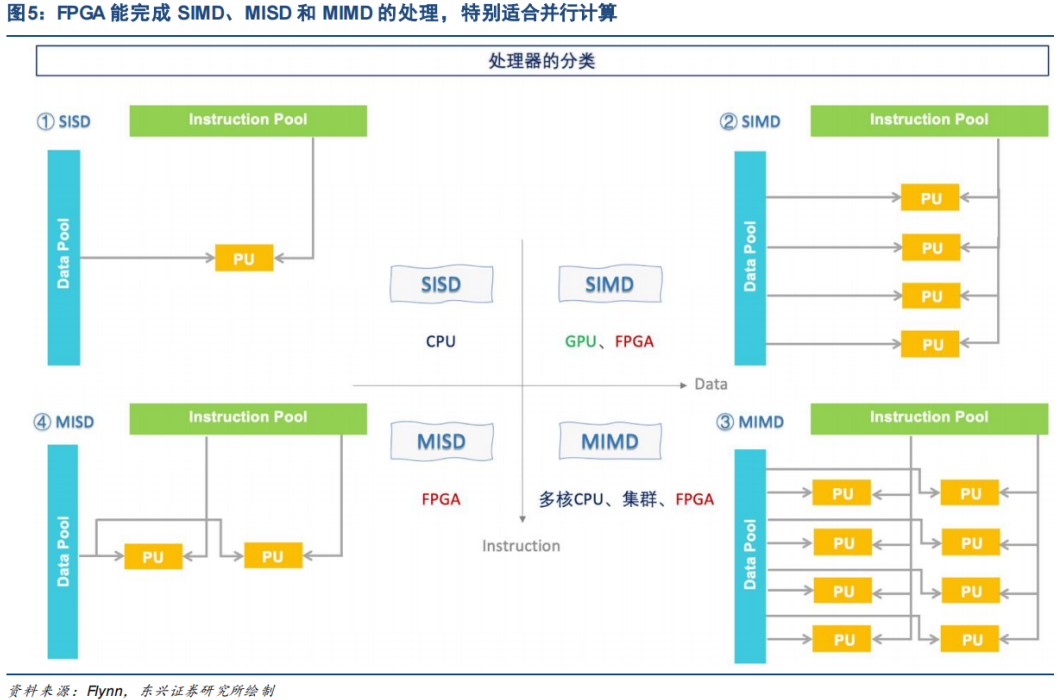
The processor is responsible for processing external input data, and the differences between processors such as CPU, GPU, and FPGA lie in their processing flows. The processing flow of the CPU makes it adept at serial computation, characterized by complex control, while GPUs and FPGAs excel in large-scale parallel computation:
● The CPU is a processor based on the Von Neumann architecture, following the processing flow of “Fetch – Decode – Execute – Memory Access – Write Back”. Data must first be fetched from RAM by the control unit, then decoded to determine what operations the user needs to perform on the data, after which the data is sent to the ALU for processing. Once the computation is complete, the results are written back to RAM, and the next instruction is fetched. This processing flow, known as SISD (Single Instruction Single Data), determines that the CPU excels at decision-making and control but is less efficient in handling multiple data processing tasks. Modern CPUs can perform both SISD and SIMD processing simultaneously, but still do not match the parallel scale of GPUs and FPGAs.
● The GPU follows the SIMD (Single Instruction Multiple Data) processing method, achieving high parallel processing of data sent from the CPU by running a unified processing method, known as a Kernel, across multiple threads. By eliminating modules such as branch prediction, out-of-order execution, and memory prefetching found in modern CPUs, and reducing cache space, the simplified “cores” in GPUs can perform very large-scale parallel computations while saving most of the time that CPUs spend on branch prediction and reordering. However, the downside is that data must conform to the GPU’s processing framework, such as requiring data to be batch-aligned, which still limits real-time performance.
● The FPGA allows users to customize the processing flow, directly determining how the CLBs on the chip are connected. Hundreds of thousands of CLBs can operate independently, enabling SIMD, MISD (Multiple Instruction Single Data), and MIMD (Multiple Instruction Multiple Data) processing to be implemented on the FPGA. Since the processing flow is mapped to hardware, there is no need to spend additional time fetching and compiling instructions, nor is there a need to spend time on out-of-order execution like in CPUs, which gives FPGAs very high real-time performance in data processing.
Therefore, both GPUs and FPGAs serve as task offloading units for CPUs, with both being more efficient in parallel computing than CPUs. In high-performance computing scenarios in data centers, GPUs and FPGAs often exist as discrete accelerator cards, where the CPU “offloads” some compute-intensive tasks to the GPU or FPGA. These “devices” interconnect with the CPU via PCIe to achieve high-parallel computation acceleration.


Risk Warning:This content only represents the analysis, speculation, and judgment of the Breaking Research team, and is published here solely for the purpose of conveying information, not as a basis for specific investment targets. Investment carries risks; please proceed with caution!Copyright Statement:This content is copyrighted by the original party or author. If reproduced, please indicate the source and author, retain the original title and ensure the integrity of the article content, and bear legal responsibility for copyright and other issues.
END
