Hello everyone! Today, we are going to discuss an increasingly popular topic—edge AI and the microchips designed for it. With the proliferation of applications such as smart homes, wearable devices, and smart security, there is a growing need to run AI models locally on devices (rather than in the cloud). The benefits are numerous: faster response times, enhanced privacy, independence from network connectivity, and potentially lower costs!
μNPU Architecture
To meet this demand, a new type of chip called μNPU (Micro Neural Processing Unit) has emerged. They are like the “little ants” of the AI world, designed to operate at extremely low power (in the milliwatt or even sub-milliwatt range!) while quickly completing AI inference tasks. Their core advantage lies in utilizing specialized hardware architectures, such as systolic arrays composed of processing elements (PE), and each PE is equipped with independent memory to maximize parallel computation and avoid memory access bottlenecks.
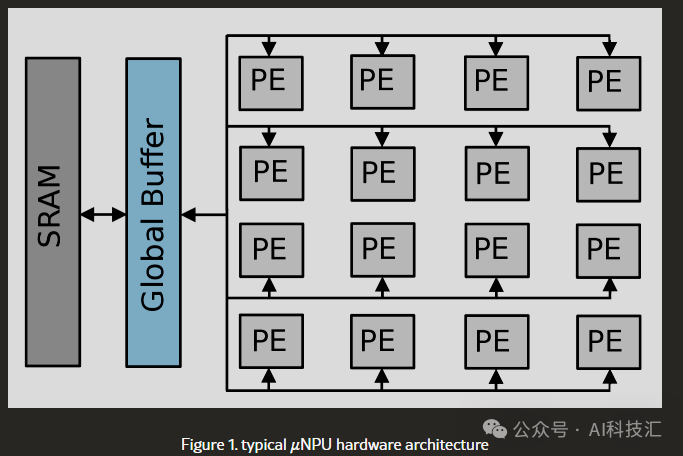
Sounds great, right? But here’s the problem: there are more and more μNPUs on the market, and the parameters advertised (like GOPs – Giga Operations per second) are getting higher, but how do they actually perform? How should we choose?
Researchers Step In: Comprehensive Benchmarking of μNPUs for the First Time
Researchers from Imperial College London and the University of Cambridge have also noticed this issue. They found that there is currently a lack of standardized, independent horizontal evaluations of these μNPUs. The promotional claims from manufacturers have left developers “in the fog” when it comes to selecting chips.
To address this, they conducted a groundbreaking study, performing side-by-side, fine-grained benchmarking of multiple commercial μNPUs for the first time. Their goal was to reveal the end-to-end performance of these chips in real-world applications, not just their paper specifications.
Even better, they developed and open-sourced a model compilation framework that allows everyone to easily conduct consistency tests across different μNPUs. Based on the test results, they provided valuable selection advice for developers.
Participants and Testing Projects
The research team carefully selected a representative group of “participants”:
- μNPU Representatives:
- Analog Devices MAX78000 (known for its unique memory structure and low bit-width support)
- Himax HX6538 WE2 (a “performance monster” with up to 512 GOPs)
- NXP MCXN947 (focusing on low power consumption and security features)
- GreenWaves GAP8 (with large memory, suitable for complex models)
- MILK-V Duo (a RISC-V SoC running Linux, representing higher-performance edge devices)
- Traditional MCU Control Group:
- STM32H7A3ZI (high-performance general-purpose MCU)
- ESP32s3 (popular MCU with vector instruction acceleration)
The testing projects were not singular but covered various common AI task models:
- Image Classification (CIFAR10-NAS, ResidualNet, SimpleNet)
- Object Detection (YoloV1)
- Signal Reconstruction (Autoencoder)
To ensure fairness, all models were uniformly quantized to INT8 precision (although this may not be the optimal choice for every chip), and the researchers carefully addressed the inconsistencies in AI operator support across different chips, focusing the comparison on the hardware architecture itself.
Not Just Looking at “Scores”, But Also the “Overall Experience”
The core aspect of this evaluation is that it does not only focus on the theoretical computational capability of the chip (GOPs) or pure inference speed, but examines the end-to-end complete process:
- NPU Initialization: How long does it take for the chip to “boot up”?
- Memory I/O: How long does it take to move model data and input data in/out of the NPU? (This will be found to be crucial later!)
- Inference Execution: How long does it actually take to run the model?
- CPU Post-Processing: What additional work does the CPU need to do after the model output? (e.g., calculating Softmax or Yolo’s NMS)
- Power Consumption and Efficiency: How much power is consumed at each stage? How much power is consumed when idle? How many inferences can be completed per millijoule of energy consumed (ImJ)?
- Memory Usage: How much Flash and RAM is used?
This meticulous measurement helped the researchers uncover many “unexpected” truths.
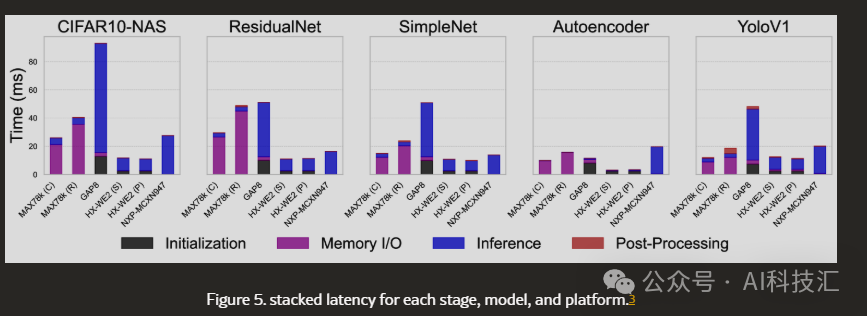
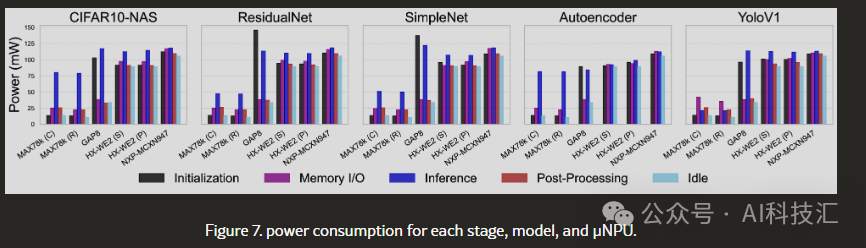
Astonishing Findings: GOPs Are Not Everything, Memory Is the Bottleneck!
With the test results in, there are several points worth noting:
1. Theoretical GOPs ≠ Actual Performance!Stop focusing solely on GOPs! The research found that while MAX78000 (30 GOPs) has theoretical computing power far below that of HX-WE2 (512 GOPs), it is actually faster in the pure inference phase for certain models! This indicates that the internal data flow and architectural design of the chip are equally important.
2. Memory I/O Is a Huge Bottleneck!This is one of the most important findings of this study. For example, with MAX78000, although its NPU computation is fast, the time taken to move data in and out of the NPU (memory I/O) accounts for as much as **90%** of the total time! This means that the chip spends most of its time “waiting for the rice to cook” rather than “cooking”. This could be fatal for scenarios that require frequent model switching or processing large amounts of data. In contrast, the NXP MCXN947 has very low memory I/O overhead.
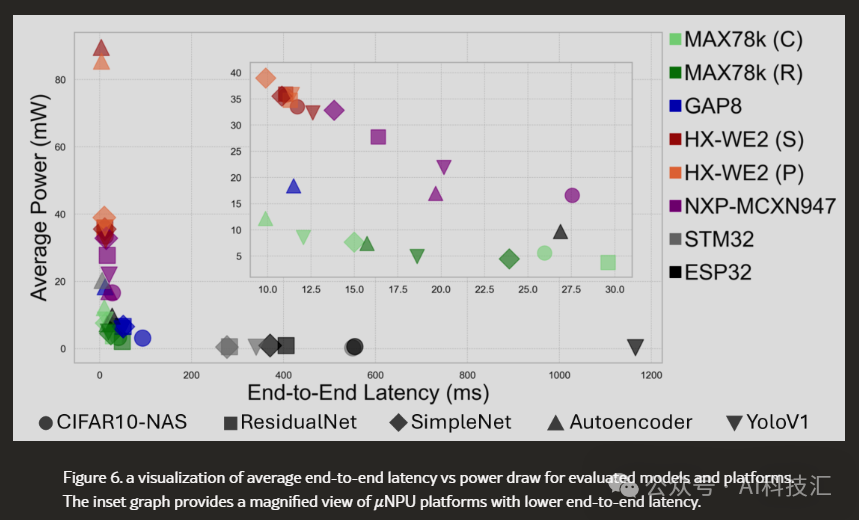
3. Efficiency Champion vs. Speed Champion (Each Has Trade-offs)
- Efficiency King (considering startup): If we include the NPU initialization time, MAX78000 (when using the Cortex-M4 core) has the highest overall efficiency, making it very suitable for battery-powered devices that require frequent startup and sleep.
- Speed King (not considering startup): If running continuously without frequent initialization, then the RISC-V architecture MILK-V Duo, with its extremely fast inference speed (though slow to start and high idle power), can achieve the highest efficiency.
- End-to-End Speed: Although HX-WE2 has higher power consumption, thanks to its fast memory I/O and initialization, it performs excellently in terms of end-to-end latency.
4. NPUs Are Strong, But MCUs Still Have Their PlaceThe comparative tests clearly show that for complex AI models, chips with NPUs are indeed several orders of magnitude more efficient than traditional MCUs (like STM32H7, ESP32s3). However, for very simple models (like the Autoencoder), high-performance MCUs (like STM32H7) can also achieve good efficiency, and it is not always necessary to use an NPU.
5. Don’t Underestimate “Startup Time” and “Idle Power Consumption”While GAP8 has a large memory, its long initialization time makes it unsuitable for tasks that require quick responses. Meanwhile, HX-WE2 and NXP chips, although performing well, have high idle power consumption, which could lead to significant energy waste if the device spends most of its time in standby. MAX78000, on the other hand, has very low standby power consumption.
Selection Guide for Developers
So, based on these findings, how should we choose a μNPU? The researchers provided very practical advice:
- If you value energy efficiency the most (e.g., long battery life):
- MAX78000 is the first choice, especially suitable for applications that require frequent startup/sleep.
- If you value low latency (need quick responses):
- HX-WE2 offers fast initialization, memory I/O, and inference, making it suitable for scenarios with high real-time requirements.
- If the application is running continuously and power consumption is not a concern, MILK-V Duo with its ultra-fast inference speed is also worth considering.
- If you need to run large, complex models:
- GAP8 has a huge memory space, making it an ideal choice for deploying large models (but be aware of its longer initialization and inference times).
- Similarly, if the power budget allows, MILK-V Duo with its large memory and SD card support is also an option.
- If you need to balance performance and security:
- NXP MCXN947 is based on the Arm architecture, supports TrustZone security technology, and has fast initialization and memory I/O speeds, with acceptable inference latency, making it suitable for applications that require a balance of security.
- If your model is very simple:
- Perhaps a high-performance general-purpose MCU (like STM32H7) would suffice, avoiding the complexity of using a dedicated NPU.
Future Outlook: μNPU Has a Long Way to Go
This research also points out the challenges currently facing the μNPU field and future development directions:
- Hardware: There is a need for larger on-chip caches and faster memory interfaces to address I/O bottlenecks.
- Software: There is a need for smarter model loading strategies, more flexible quantization support (not just INT8), and even support for on-device training!
- Ecology: There is a need for unified model formats and more accurate performance simulators to simplify the development process.
- Functionality: There is a need to support a wider variety of AI operators, not just limited to CNNs.
Conclusion
This comprehensive benchmarking of μNPUs tells us:
- Don’t Trust GOPs Blindly: Theoretical computing power does not represent everything; actual performance is influenced by architecture, memory, and other factors.
- Pay Attention to Memory I/O: This is a performance bottleneck for many μNPUs and must be considered during selection.
- End-to-End Evaluation: Look at the performance of the complete process, including initialization, post-processing, and power consumption.
- Select According to Needs: There is no perfect chip, only the chip that is most suitable for your application.
We hope this research helps everyone gain a deeper understanding of these powerful micro AI chips and make more informed choices in future project development!
Want to learn more? You can read the original paper: Benchmarking Ultra-Low-Power μNPUs (arXiv:2503.22567v1)
What are your thoughts on μNPUs? Feel free to leave your comments and discuss!