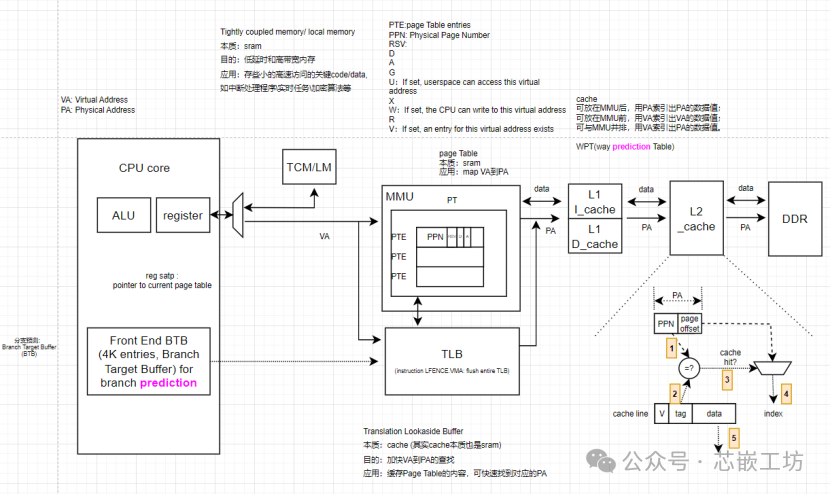
 A brief block diagram of a certain RISC-V Level 1
A brief block diagram of a certain RISC-V Level 1
The storage architecture of RISC-V (from inside to outside):
1)Reg
2)TCM (Tightly Coupled Memory, divided into I/D) / LM (Local Memory, divided into I/D)
3)TLB lookup (Translation Lookaside Buffer, a fast cache of recent address mappings)
– TLB hit: avoids Page Table Lookup
– TLB miss: perform Page Table Lookup, cache result for later
4)MMU (Memory Management Unit, includes Page Table Lookup)
5)L1 cache (I-cache, D-cache)
6)L2 cache (Way Prediction Table, WPT)
7)DDR
 Traditional pipeline
Traditional pipeline
Predict: Prediction (not detailed yet)
Fetch: Request instruction fetch from memory
Decode: Instruction decode & register read
Execute: Execute operation or calculate address
Memory: Request memory read or write
Writeback: Write result (either from execute or memory) back to register
In practice, RISC-V may slightly adjust based on the traditional pipeline, such as adding instruction prefetching before the fetch stage or splitting a stage into multiple stages to increase frequency and achieve better performance.
 A certain RISC-V actual pipeline
A certain RISC-V actual pipeline
Differences with ARM in pipeline:
There are significant differences in design philosophy and implementation flexibility. The following is a detailed comparison:
1. Typical pipeline stages and functions of RISC-V
As an open-source instruction set architecture (ISA), the pipeline design of RISC-V varies by implementation, but common stages include:
—Basic pipeline (5-stage classic RISC)
1.1Fetch (IF, Instruction Fetch)
Read instruction from instruction memory and update the program counter (PC).
1.2Decode (ID, Instruction Decode)
Parse instruction, read from register file, identify operation type (e.g., arithmetic, branch, etc.).
RISC-V’s instruction format is regular, and the decoding complexity is low.
1.3Execute (EX, Execute)
Execute arithmetic logic operations (ALU), address calculation, or branch judgment.
1.4Memory Access (MEM)
Access data memory (Load/Store operations), or bypass (for non-memory instructions).
1.5Write Back (WB)
Write results back to the register file.
—Advanced pipeline extensions
Multi-issue: Supports superscalar (e.g., dual-issue, out-of-order execution).
Branch prediction: Dynamic or static prediction to reduce pipeline stalls.
Pipeline depth: Can be up to 10+ stages (e.g., high-performance implementations) or simplified to 3 stages (embedded scenarios).
—Characteristics
Modular design: Supports optional extensions (e.g., multiplication, division, vector instructions), and the pipeline can be adjusted accordingly.
No microcode: Directly executes instructions without a complex decoding layer.
2. ARM microarchitecture pipeline design
As a commercial architecture, ARM’s pipeline design is highly optimized and diverse, with typical representatives:
—Classic pipeline (e.g., Cortex-A7/A53)
8-15 stage pipelines: Deeper pipelines to increase frequency (e.g., Cortex-A15).
Complex branch prediction: Multi-level predictors (e.g., TAGE, Loop Buffer).
Register renaming: Supports out-of-order execution (e.g., Cortex-A7x series).
Microcode support: Complex instructions (e.g., NEON/SVE) may be decomposed into micro-operations.
—Modern ARM designs (e.g., Cortex-X/A7xx)
Superscalar + out-of-order execution: Typically 4-6 issue width.
Memory prefetch: Aggressive data prefetch logic.
Adaptive clock gating: Dynamically adjusts pipeline power consumption.
3. Key differences between RISC-V and ARM microarchitectures
|
Feature |
RISC-V |
ARM |
|
Flexibility |
Open-source, customizable pipeline (e.g., 3-stage/10+ stage) |
Closed-source, fixed microarchitecture (e.g., Cortex-A78) |
|
Instruction Decoding |
Fixed-length instructions, simple decoding |
Supports Thumb-2 (variable-length instructions), more complex decoding |
|
Microcode Layer |
None, directly executes instructions |
Complex instructions may use microcode (e.g., SVE2) |
|
Branch Prediction |
Implementation dependent (can be simple or complex) |
Highly optimized predictors (hardware patented) |
|
Memory Model |
Loose, implementation dependent |
Strict consistency (e.g., ARMv8 MMU specification) |
|
Toolchain Ecosystem |
Basic, community dependent |
Mature (e.g., DS-5, Keil) |
|
Typical Applications |
From embedded to high-performance (custom) |
Mobile/server (standardized IP cores) |
4. Conclusion
RISC-V: The advantage lies in flexibility, suitable for customized scenarios (e.g., IoT, dedicated accelerators), with pipeline designs ranging from minimal to high performance.
ARM: The advantage lies in proven efficient designs (e.g., branch prediction, memory systems), suitable for commercial scenarios with strict performance and power requirements (e.g., smartphones).
Example comparison:
A RISC-V open-source implementation (e.g., BOOM) may adopt a 6-stage out-of-order pipeline, while a similarly performing ARM Cortex-A55 uses an 8-stage pipeline + out-of-order execution, but the latter may be more thoroughly optimized at the same process.