RISC-V is an instruction set architecture (ISA) for microprocessors, and people’s opinions about it are polarized. This is especially true given the apparent competition between the ARM and RISC-V camps.
This makes sense. RISC-V and ARM represent fundamentally different philosophies on how to design RISC chips. RISC-V has a long-term view that emphasizes simplicity, avoiding solutions that may yield short-term benefits but could lead to long-term issues. RISC-V truly embraces the philosophy of RISC, making things very simple, with not only a minimal instruction set but also a focus on simple instructions.
ARM, on the other hand, is more of a ruthless pragmatic design choice. The decisions we make regarding hardware capabilities today are based on what makes sense in the near future. If certain instructions are believed to enhance overall performance, ARM designs do not shy away from adding quite complex instructions.
As a result, ARM has many instructions, each of which does a lot of work. ARM includes instructions with complex addressing modes and conditional execution instructions (for 32-bit ARM only). These instructions execute only if the condition is true, thus avoiding branching.
Both approaches have their merits. It is helpful to clarify the facts when criticizing one design over another. Regarding RISC-V, I want to clarify many misconceptions. I will attempt to introduce some of the more notable misconceptions I have encountered.
Misunderstanding 1: RISC-V Instruction Set Bloats Programs
RISC-V instructions are generally much fewer than ARM instructions. ARM has an instruction LDR for loading data from memory into registers. It is designed to handle typical C/C++ code like this:
// C/C++ codeint a = xs[i];
We want to extract the data at index i from the array xs. We can convert it to ARM code where register x1 holds the starting address of the array xs and register x2 holds the index i. We must calculate the byte offset from the base address x1. For a 32-bit integer array, this means multiplying the index i by 4 to get the byte offset. On ARM, we achieve the same effect by left-shifting register x2 twice.
mem refers to the main memory. We use x1, x2, and shifts like 2, 4, or 8 to construct the source address. The actual instruction would be written like this:
LDR x1, [x1, x2, lsl #2] ; x1 ← mem[x1 + x2<<2]
In RISC-V, the equivalent instruction requires 3 different instructions (the # indicates comments):
SLLI x2, x2, 2 # x2 ← x2 << 2ADD x1, x1, x2 # x1 ← x1 + x2LW x1, x1, 0 # x1 ← mem[x1 + 0]
This seems like a huge gain for ARM with 3 times denser code. You have less pressure on the cache and greater throughput in the instruction pipeline.
-
Compressed Instructions to the Rescue
RISC-V supports compressed instructions simply by adding 400 logic gates (AND, OR, NAND) to the chip. This allows two more common instructions to fit into a single 32-bit word. Most importantly, compression does not add latency. It is not like zip decompression. Decompression is part of the regular instruction decoding, so it is instantaneous.
# RISC-V codeC.SLLI x2, 2 # x2 ← x2 << 2C.ADD x1, x2 # x1 ← x1 + x2C.LW x1, x1, 0 # x1 ← mem[x1 + 0]
Compressed instructions follow the80/20 rule: 80% of the time, 20% of the instructions are used.
Do not take this statement literally. It is just a saying; a small portion of RISC-V instructions are used extensively. RISC-V designers carefully assessed which instructions and included many of them as part of the compressed instruction set.
With this trick, we can easily surpass ARM in code density.
In fact, modern ARM chips can run in two modes, one for backward-compatible 32-bit mode (AArch32) and another for 64-bit mode (AArch64). In 32-bit mode, ARM chips support compressed instructions called Thumb.
To clarify: do not confuse 64-bit mode with instruction length. Instructions in 64-bit mode on ARM are still 32 bits wide. The emphasis of 64-bit ARM is the ability to use 64-bit general-purpose registers. For 64-bit mode, ARM completely redesigned the instruction set, which is why we must often be clear about which instruction set we are discussing.
For the nearly identical 32-bit instruction set (RV32I) and 64-bit instruction set (RV64I) RISC-V, this distinction is less significant. This is because RISC-V designers considered 32-bit, 64-bit, and even 128-bit architectures when designing the RISC-V ISA.
Anyway, back to RISC-V compressed instructions.
While consuming less memory for instructions is good for the cache, it does not solve all problems. We still have more instructions to decode, execute, and write back results. This issue can be addressed through macro-op fusion.
-
Reducing Instruction Count with Macro-op Fusion
Macro-op fusion can combine multiple instructions into one. RISC-V designers aredetermining the code patterns that the compiler should emit to help RISC-V hardware designers implement macro fusion. One of the rules is that the destination register for each operation is the same. Because ADD and LW both store their results in register x1, we can fuse them into one operation in the instruction decoder.
This rule also avoids one common objection to macro-op fusion that I have read: maintaining multiple register writes in a fused instruction can become messy. No, it does not, because each instruction must overwrite the same destination register to be allowed to fuse. Therefore, fused instructions do not need to write to multiple registers.
-
Considerations for Macro-op Fusion
Macro-op fusion is not a free lunch. You need to add more transistors in the decoder to make it work. You also have to work with compiler writers to ensure they generate code patterns that help create fusable instruction patterns.
The people behind RISC-V are currently actively doing this. And of course, sometimes it simply does not work at all due to boundaries like cache lines. However, this is also an issue for x86 instructions, which can be of arbitrary length.
Misunderstanding 2: Variable-Length Instructions Complicate Parallel Instruction Decoding
In the x86 world, an instruction can, in principle, be of unlimited length, although for practical purposes, the upper limit is 15 bytes. This complicates the design of superscalar processors that decode multiple instructions in parallel. Why? Because when you get a 32-byte code, you do not know where each individual instruction starts. Solving this problem requires complex techniques that often take more cycles to decode.
Some people describe the techniques used by Intel and AMD as a trial-and-error brute-force method, where you simply make a lot of guesses at the start and end positions of the instructions.
However, in contrast, the complexity added by RISC-V compressed instructions is trivial. Let me explain: the fetched instructions will always be 16-bit aligned. This means that each 16-bit block is either the start of a 16/32-bit instruction or the end of a 32-bit instruction.
People can use this simple fact to design different methods for parallel decoding RISC-V instructions.
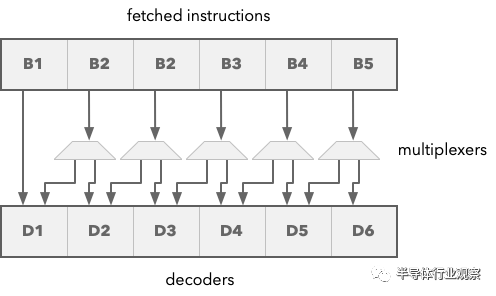
Now, I am not a chip designer, but I can think of some scheme to achieve this. For example, I could associate a decoder with each 16-bit block, as shown in the diagram below.
Then each decoder would take its first input from its associated 16-bit block. So the first part of instruction D2 would come from instruction block B2. If we have a 32-bit instruction, the second part would come from B3.
When you decode an instruction, the decoder can decide whether it is processing a 16-bit or 32-bit instruction and whether to use the second input stream from the next block. The important observation here is that each decoder can independently decide to use the second 16-bit instruction data block or not, independent of all other decoders. This means you can perform this operation in parallel.
In contrast, I do not know how to decode x86 instructions, which can be 1-15 bytes long. This makes me feel like it is a very difficult problem to think about.
In any case, the designers of RISC-V themselves say this is not a hard problem to solve. What I am doing here is just trying to illustrate why it is not difficult to explain in layman’s terms. Do not be too strict with the solution I propose. It obviously lacks a lot of details. For example, you would need some logic to switch multiplexers.
Misunderstanding 3: Lack of Conditional Execution is a Mistake
32-bit ARM (ARMv7 and earlier architectures) has what we call conditional instructions. Take a normal instruction like LDR to load a register or ADD and append a condition like EQ (equal) or NE (not equal), and you get conditional instructions like LDREQ and ADDNE.
; ARM 32-bit codeCMP r6, #42 LDREQ r3, #33 ; r3 ← 33 if r6 = 42LDRNE r3, #12 ; r3 ← 12 if r6 ≠ 42CMP r3, #8SUBS r3, r6, #42ADDEQ r3, #33 ; r3 ← r3 + 33 if r6 – 42 = 0ADDNE r3, #12
Instructions like CMP set condition flags, which are read when executing conditional instructions. They only execute if the condition is satisfied. This is a very quick explanation.
In previous articles, I also explained why RISC-V proponents oppose conditional execution. It complicates out-of-order execution (OoOE), which is significant for achieving high-performance chips. In fact, for the same reasons, modern 64-bit ARM processors (ARMv8 and later) also lack conditional execution. It only has conditional select instructions (CSEL, CSINC), but these instructions are unconditionally executed.
Objections from the ARM camp are that without conditional instructions, you would reduce performance on simpler in-order microprocessors (which would use 32-bit ARM). The assumption here is that on CPUs with fewer transistors, you will not have a sufficiently complex branch predictor to avoid performance losses caused by branch mispredictions.
RISC-V participants again have the answer. If you look at theSiFive 7 series cores, they have actually implemented macro-op fusion to handle this issue. A short branch with only one instruction can be fused into a conditional instruction similar to ARM. Consider this code:
BEQ x2, x3, done # jump to done if x2 == x3ADD x4, x5, x6 # x4 ← x5 + x6done:SUB x1, x3, x2
Because the jump to done is only one instruction, SiFive 7 series chips can recognize this pattern and fuse it into a single instruction. In pseudocode, this ultimately conceptually means:
# RISC-V code # if x2 != x3 then x4 ← x5 + x6 ADDNE x2, x3, x4, x5, x6 SUB x1, x3, x2
This feature is calledshort forward branch optimization. Let me emphasize that there is no ADDNE instruction. This is just a way of illustrating what is happening. The benefit of this macro-op fusion is that we eliminate one branch. This means we eliminate the potential cost ofbranch misprediction (flushing the instruction pipeline). SiFive discusses this in theirpatent application:
For example, a conditional branch can be fusedon one or more instructions. In some implementations, the conditional branch is fused with subsequent instructions, allowing thegroup to execute as a single non-branch instruction.
Fusedmicro-operations can be executed asnon-branch instructions, thus avoiding pipeline flushing, and additionally,avoiding polluting the branch predictor state. The sequence of macro-operations to be fused can include multiple instructions following control flow instructions.
ARM camp can argue that relying on macro-op fusion is bad because it increases complexity and transistor count. However, ARM often uses macro-op fusion to merge CMP branch instructions like BEQ or BNE. On RISC-V, conditional jumps are done with a single instruction, and about 15% of normal code consists of branch instructions. Therefore, RISC-V actually has a significant advantage in this regard. ARM can offset this advantage by using macro-op fusion. But if macro-op fusion is fair game for ARM, then it must be fair game for RISC-V as well.
Misunderstanding 4: RISC-V Uses Outdated Vector Processing Instead of Modern SIMD Instructions
Some in the ARM camp want to give the impression that RISC-V designers are stuck in the past and have not kept up with the latest advances in microprocessor architecture. RISC-V designers chose to adopt vector processing instead of SIMD. The former was once popular in old Cray supercomputers before falling out of favor. SIMD instructions were later added to x86 processors to help multimedia applications.
This gives the impression that SIMD is a newer technology, but that is not the case. SIMD instructions first appeared on theLincoln TX-2 computer, which was used to implement the first GUI calledSketchpad created by Ivan Sutherland.
Vector processing performed by Cray supercomputers is a more advanced method of processing multiple data elements. The reason these types of machines fell out of favor is simply that the shipment volumes of supercomputers were smaller, allowing regular PCs to surpass them due to larger shipment volumes.
SIMD instructions were simply added to x86 processors in a fairly casual manner, without much planning to gain some simple speedup in processing multimedia.
SIMD instruction sets are simpler than instruction sets used for true vector processing. However, as the capabilities of SIMD instruction sets have expanded, and their lengths have increased, we ultimately ended up with something far more complex than vector processing. Not to mention some very messy and inflexible things.
Thus, the fact that Cray used vector processing in the 1980s does not mean that vector processing is an outdated technology. This is like saying that wheels are an outdated technology just because they have been around for a long time.
On the contrary, vector processing has become more important as machine learning, advanced graphics, and image processing can benefit from it. These are the areas where we demand the highest performance. The people behind RISC-V are not the only ones who realize this. ARM has added their own vector processing inspired instruction SVE2. If this is a bad idea, then no one would be adding such instructions to their CPUs.
Misunderstanding 5: Vector Processing is Unnecessary, Just Use GPUs
Another argument I see against vector processing is that for longer vectors, you simply do not need the CPU to handle it. Just send them to modern GPUs.
However, this approach has several issues:
1. Not all RISC-V code can run on high-end workstations equipped with powerful GPUs.
2. Sending data back and forth between CPU memory and GPU memory incurs latency.
3. GPUs are not truly designed for general-purpose vector processing, even if they outperform general CPUs in vector processing.
We are starting to see small microcontrollers with AI accelerators used for executing AI tasks on devices. For such small, inexpensive systems, you cannot plug in some large Nvidia GPU to handle vector data.
Managing the data transfer with graphics cards for processing adds extra overhead and more planning requirements. Unless you have enough data to send over, it is generally better to process data locally on the CPU.
GPUs were originally designed to handle graphics data like vertices and fragments (pixels) using vertex and fragment shaders. GPUs have gradually become more general-purpose, but this tradition still exists.
Many startups are looking to challenge Nvidia in the AI market by manufacturing their own dedicated AI acceleration cards, and this is not without reason. They see a clear competitive opportunity to create hardware specifically designed for machine learning computations rather than graphics computations.
Esperanto Technologies, with their SOC-1 chip, is an example. They built a solution around RISC-V processor cores to compete with theNvidia A100 GPU, which is specifically designed to accelerate machine learning computations. However, the A100 has over 100 cores (streaming multiprocessors SM).
In contrast, Esperanto Technologies has placed 1092 cores on a chip that consumes only 20 watts of power. In comparison, the A100 consumes 250–300 watts.
This allows you to place six SOC-1 chips on a single board while still consuming only 120 watts. For a relevant comparison, consider that the power consumption of a typical rack server should not exceed 250 watts.
Thus, you can create a motherboard with over 6000 RISC-V cores and install them in regular server racks to perform AI workloads.
All of this is achieved by creating small, simple RISC-V cores with vector processing capabilities. Esperanto is pursuing this strategy rather than manufacturing multi-processor cores like Nvidia GPUs.
In other words, the idea that you should only use GPUs for vector processing has not taken hold in the mainstream. Well-designed RISC-V cores with vector processing capabilities will allow you to outperform GPUs in vector processing with less power consumption.
Where does this misunderstanding come from? It stems from the idea that CPUs are just large x86-style cores. Adding vector processing to some large x86 cores does not necessarily make sense. But who says you need to make large cores? With RISC-V, you can create any type of core. The SOC-1 chip has both large out-of-order superscalar cores and tiny in-order cores with vector processing capabilities.
Misunderstanding 6: Modern ISAs Must Handle Integer Overflow
When integer arithmetic instructions overflow, RISC-V is often criticized for not causing traps (hardware exceptions) or setting any flags. This fact seems to come up in almost any discussion about RISC-V. It is used as an argument that RISC-V designers are stuck in the 1980s when no one checked for integer overflow.
There is a lot to unpack here, so let’s start with the simple. Most widely used language compilers do not cause overflow in release mode or by default. Examples include:
Some of these do not even do so in debug mode by default. For example, in Java, if you want overflow exceptions, you need to call methods like addExact. In C#, you need to place the code in what is called a checked context:
try {checked {int y = 1000000000;short x = (short)y;}}catch (OverflowException ex) {MessageBox.Show(“Overflow”);}
In Go, you need to use functions from theoverflow library, such as overflow.Add, overflow.Sub, or variants that cause panic (similar to exceptions), such as overflow.Addp and overflow.Subp.
The only mainstream compiled language I can find that throws exceptions on integer overflow is Swift, and if you Google it, you will find many people are dissatisfied with this. Therefore, the idea that this is a significant failure of RISC-V for lacking built-in support seems strange.
Many dynamically typed languages (like Python) are known for immediately upgrading to larger types when integers overflow. However, these languages are so slow that the extra instructions required by RISC-V make little difference.
Misunderstanding 7: Integer Overflow Handling is Too Bulky
When discussing integer overflow, it is often claimed that RISC-V requires four times the code as other instruction set architectures. However, this is the worst-case scenario. You can simply add branch instructions to handle many common cases.
Adding overflow checks for unsigned integers:
add t0, t1, t2 # t0 ← t1 + t2bltu t0, t1, overflow # goto overflow if t0 < t1
For signed integers when the sign of one operand is known:
addi t0, t1, 42 # t0 ← t1 + 42blt t0, t1, overflow # goto overflow if t0 < t1
General case with two operands whose signs are unknown:
add t0, t1, t2 # t0 ← t1 + t2slti t3, t2, 0 # t3 ← t2 < 0slt t4, t0, t1 # t4 ← t0 < t1bne t3, t4, overflow # goto overflow if t3 ≠ t4
Misunderstanding 8: Implementing Integer Overflow is Cheap
In a vacuum, getting and storing overflow bits does not cost much. But this is like saying that the cost of mutation functions in programming in terms of memory or CPU cycles is negligible. This is a side issue.
One of the reasons for advocating pure functions (non-mutating) in regular programming is that they are easier to run in parallel than those that modify shared state. The same goes for out-of-order superscalar processors. Superscalar processors parallelize many instructions. If instructions do not share any state, it is easier to run them in parallel.
State registers introduce shared state, which introduces dependencies between instructions. This is why RISC-V was designed without any state registers. For example, branch instructions in RISC-V directly compare two registers instead of reading from a state register.
To support state registers for out-of-order execution of instructions in superscalar processors, you need more complex bookkeeping. It is not just a matter of adding a fewflip-flops to store bits.
Many criticisms of RISC-V are based on misunderstandings of the technology and a lack of vision for the bigger picture. How RISC-V enables the creation of heterogeneous computing environments, where its cores are optimized for different types of computations that work in concert, is something that people are not accustomed to.
Regardless of what they should do, this is not a novel idea. The Playstation 3 had a similar architecture calledCell, which had a general-purpose core called the Power Processor Element (PPE) and specialized vector processors called Synergistic Processing Elements (SPE).
However, PPE and SPE had different instruction sets, making the Cell architecture complex to work with. With modern RISC-V systems, you benefit from every core having the same basic instruction set and registers. You can use the same tools for debugging and testing across all cores.

Welcome angel round,Around companies to join the group (Friendly connection includes 500 automotive investment institutions, including top institutions; several companies have been completed); There are communication groups for science and technology innovation companies, automotive complete vehicles, automotive semiconductors, key parts, new energy vehicles, intelligent connected vehicles, aftermarket, automotive investment, autonomous driving, vehicle networking, and dozens of other groups. To join the group, please scan the administrator’s WeChat (Please indicate your company name)