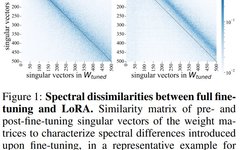
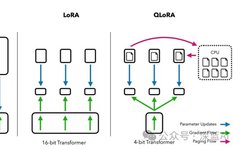
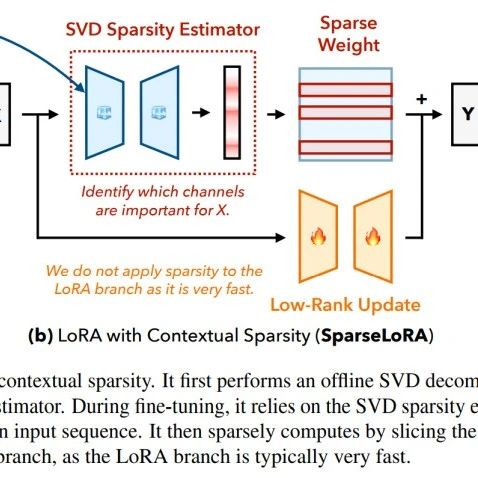
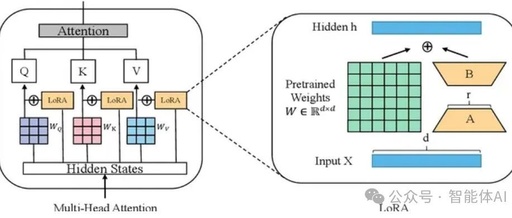
LoRA Fine-Tuning: Adding New Knowledge Without Harming LLM

Click 👇🏻 to follow, article from 🙋♂️ Friends who want to join the community can see the method at the end of the article for group communication. “Hello everyone, I am Si Ling Qi. Today I want to talk to you about an interesting study regarding Large Language Models (LLM) — how much new knowledge … Read more