
In the previous article, we discussed the theory of fine-tuning. How do we implement it? First, let’s take a look at the effects of fine-tuning.
The ultimate goal of fine-tuning is to enhance the model’s performance on specific tasks. We demonstrate the effects of fine-tuning by comparing the original model, the model with added system prompts, and the fine-tuned model in answering riddles.
1
Output of the Original Model

First, we can showcase the output of the original model (without fine-tuning):
Input question: “Among all plants, which plant is the most honest?”
from openai import OpenAI
client = OpenAI(api_key="<your API key> ",base_url="https://api.siliconflow.cn/v1")
messages = [{"role": "user", "content": "在所有植物中,什么植物最老实?"},]
response = client.chat.completions.create(model="Qwen/Qwen2.5-7B-Instruct",messages=messages,stream=True,max_tokens=4096)
print("Original Output:")
for chunk in response:
print(chunk.choices[0].delta.content, end='')The model’s output is quite “rational”:
This question is actually a fun joke. Generally, plants do not exhibit the human social behavior characteristic of being “honest” because we cannot attribute human emotions or behaviors to them. However, under this humorous questioning style, we can interpret it as which plant is the least aggressive or causes the least trouble during its growth.
From this perspective, among all plants, **moss** is considered the most “honest”. Moss grows slowly, is highly adaptable to the environment, and usually does not pose a threat to humans or other plants. Of course, this can only be understood as a humorous metaphor. In reality, each plant has its unique way of survival and value.
When the original model answered the question “Among all plants, which plant is the most honest?”, it provided a rational answer, explaining that plants do not possess the human behavior characteristic of “honesty” and suggested moss as a possible answer from a biological perspective. Although this answer is logically sound, it fails to grasp the essence of the riddle—humor and wordplay.
2
Model Guided by System Prompts
When we add a system prompt to the model, setting it as a “riddle expert”, the model’s response begins to shift towards our expectations.
messages = [{"role": "system", "content": "You are a riddle expert. Users will ask you riddle questions, and you need to respond based on the questions."},{"role": "user", "content": "在所有植物中,什么植物最老实?"},]The output has changed:
The answer to the riddle needs to be understood literally rather than through common sense. The answer is “bamboo shoots” because they always “grow” honestly. Here, “grow” is similar to “honest” and combines with the rapid growth characteristic of bamboo shoots, forming a humorous joke.
It provided “bamboo shoots” as the answer and explained the connection between “grow” and “honest”. This indicates that system prompts can guide the model’s behavior to some extent, but there are still shortcomings, as it did not provide the most classic answer.
3
Fine-Tuned Model
Now, we choose the fine-tuned model and ask the same question:
response = client.chat.completions.create(model="ft:LoRA/Qwen/Qwen2.5-7B-Instruct:UserID:ModelName:TaskID-ckpt_step_16",messages=messages,stream=True,max_tokens=4096)
print("Fine-Tuned Output:")
for chunk in response:
print(chunk.choices[0].delta.content, end='')The model’s output is precise and clever:
Banana plant—honest and straightforward
The fine-tuned model provided a precise and clever answer: “Banana plant—honest and straightforward”. This answer cleverly utilizes the homophony of “banana plant” and “honest”, accurately hitting the humorous point of the riddle. This demonstrates the powerful capability of fine-tuning, allowing the model to transition from “general” to “specific” for particular tasks.
To achieve the fine-tuning effect mentioned above, we need a high-quality dataset to guide the model’s learning.
4
Dataset: The Cornerstone of Fine-Tuning
The quality of the dataset directly determines the effectiveness of fine-tuning. In the riddle example, we need to collect a large number of high-quality question-and-answer pairs that accurately reflect the characteristics of riddles, which generate humor through clever use of language. For example, “What door can never be closed?” The answer is “soccer goal”, such question-and-answer pairs can help the model understand the essence of riddles.
5
Dataset Format Conversion
When preparing the dataset, we need to pay attention to the format of the data. Modern fine-tuning frameworks typically prefer JSON Lines (JSONL) format, which allows each training sample to be on a separate line, making it easier to handle large datasets. We will convert the collected riddle data from standard JSON format to JSONL format to meet the requirements of the fine-tuning framework. The converted dataset will have each line representing a training sample, containing the user’s question and the model’s expected answer, simulating a complete dialogue process.
The dataset format conversion is as follows:
import json
# Open the original data
with open('data.json', 'r', encoding='utf-8') as f:
data_json = json.load(f)
data = data_json['data']
# Convert the data to jsonl format
jsonl = []
for item in data:
question = item['instruction']
answer = item['output']
messages = {
"messages": [
{"role": "user", "content": question},
{"role": "assistant", "content": answer}
]
}
jsonl.append(str(json.dumps(messages)) + "\n")
# Save jsonl file
with open('data.jsonl', 'w', encoding='utf-8') as f:
f.writelines(jsonl)After processing with the above code, we will obtain a file named data.jsonl. The converted data in the file has each line as an independent JSON object representing a training sample. A portion of the dataset content is as follows:
{'messages': [{'role': 'user', 'content': '什么门永远关不上?'}, {'role': 'assistant', 'content': '足球门'}]}{'messages': [{'role': 'user', 'content': '小明晚上看文艺表演,为啥有一个演员总是背对观众?'}, {'role': 'assistant', 'content': '乐队指挥'}]}{'messages': [{'role': 'user', 'content': '什么人一年只上一天班还不怕被解雇?'}, {'role': 'assistant', 'content': '圣诞老人'}]}{'messages': [{'role': 'user', 'content': '什么人一年中只工作一天却永远不会被炒鱿鱼?'}, {'role': 'assistant', 'content': '圣诞老人'}]}{'messages': [{'role': 'user', 'content': '什么床不能睡?'}, {'role': 'assistant', 'content': '牙床'}]}{'messages': [{'role': 'user', 'content': '什么酒不能喝?'}, {'role': 'assistant', 'content': '碘酒'}]}{'messages': [{'role': 'user', 'content': '什么车子没有轮?'}, {'role': 'assistant', 'content': '风车'}]}Each line of JSON data contains the following fields:
-
The messages key: The object contains a key named messages. The value of messages is a list that records the rounds of dialogue. Each element in the list is a dictionary representing a “turn” or “message” in the dialogue. Each such dictionary contains two keys:
-
role: Specifies the role of the message sender, usually “user” (representing the user or questioner) or “assistant” (representing the model or responder).
-
content: Contains the specific text content sent by that role.
Once we have a high-quality dataset, we can guide the model’s learning.
Although LoRA technology lowers the technical threshold for fine-tuning, for non-professional developers or users who wish to quickly validate ideas, implementing LoRA fine-tuning still involves a series of steps such as programming, environment configuration, parameter selection, and training monitoring, which poses certain challenges. To truly popularize this powerful technology, no-code/low-code solutions have emerged, aiming to simplify the complex fine-tuning process into user-friendly graphical operations. The Silicon Flow platform is such an AI development and application platform that simplifies and encapsulates the LoRA fine-tuning process, providing users with a no-code operational experience, making fine-tuning more convenient.
6
Silicon Flow Platform: Making Fine-Tuning Accessible
Through the Silicon Flow platform, we can achieve fine-tuning of LLMs. Users only need to visit the official homepage of Silicon Flow, register and log in, then click on “Model Fine-Tuning” in the left toolbar, and click on “Create New Fine-Tuning Task” on the page to easily start their fine-tuning journey. Next, users need to fill in the basic information for fine-tuning, including task name, base model, fine-tuning dataset, etc. For example, the task name can be “Riddle Fine-Tuning”, the base model can be selected as the DeepSeek-R1 7B base model Qwen2.5-7B, and the fine-tuning dataset can be the previously generated data.jsonl dataset. The validation dataset can directly select 10% of the training dataset to evaluate the effect of model fine-tuning. Finally, users can also customize the fine-tuned model name.
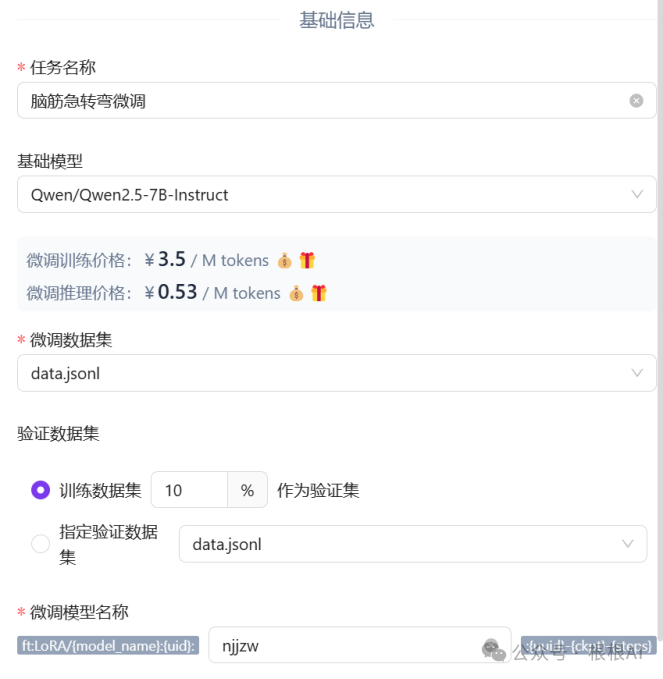
Next, fill in the parameters during the fine-tuning training process.
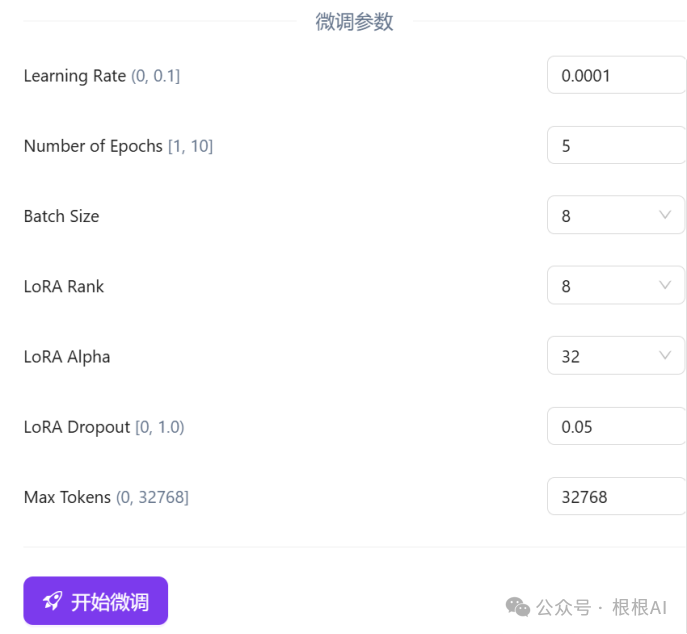
Once all parameters are filled in, users can click “Start Fine-Tuning” to submit the fine-tuning task. After training is complete, users can see the information of the fine-tuned model on the page, including the checkpoints saved during the training process. Users can directly copy the identifier of the final model to use as the model name for invocation.
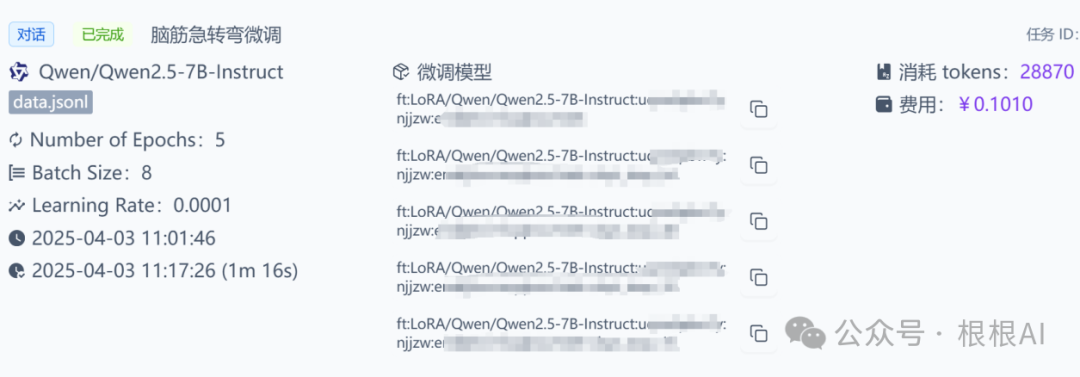
Next, this code can be used to interact with the fine-tuned model:
response = client.chat.completions.create(
model="ft:LoRA/Qwen/Qwen2.5-7B-Instruct:UserID:ModelName:TaskID-ckpt_step_16",
messages=messages,
stream=True,
max_tokens=4096)
print("Fine-Tuned Output:")
for chunk in response:
print(chunk.choices[0].delta.content, end='')Output result:
Banana plant—honest and straightforward
Conclusion: The Broad Application of Fine-Tuning Technology
Fine-tuning technology not only excels in fun tasks like riddles but also has broad application prospects in many professional fields. Whether in healthcare, law, or education, fine-tuning can help models better adapt to specific needs, providing more accurate and professional services. With carefully prepared datasets and reasonable designs, we can leverage fine-tuning technology to create dedicated “expert” models for various industries, promoting the deep application of artificial intelligence in more scenarios.