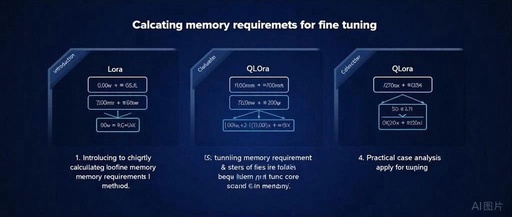
Efficient Fine-Tuning Methods for Quantized Large Models: QLoRA
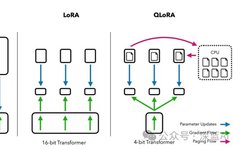
Paper Title: QLoRA: Efficient Finetuning of Quantized LLMs Authors: Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer Project Address: https://github.com/artidoro/qlora Author: Jay Chou from Manchester Reviewer: Los Abstract: QLoRA is a model quantization algorithm proposed by Tim Dettmers from the University of Washington, applied in LLM training to reduce memory requirements. It is sufficient to … Read more