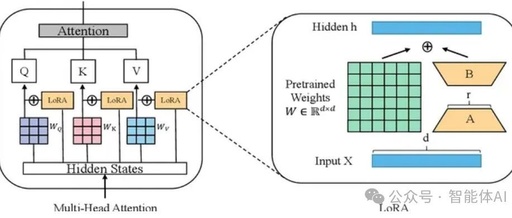
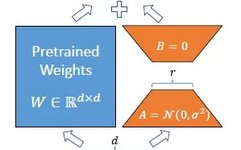
Principles and Differences of Full Parameter Tuning, LoRA, and QLoRA

🗼 In interviews related to large model fine-tuning, the question “What are the differences between full parameter tuning, LoRA, and QLoRA?” is a frequently asked topic. The standard answer generally unfolds from five dimensions: principles, resource requirements, effects, advantages and disadvantages, and applicable scenarios. Below is a high-quality template answer for interviews. 1. Full Parameter … Read more