As mentioned in previous articles, LoRA fine-tuning primarily targets the weight matrices of linear layers, such as the Q, K, and V projection matrices in the attention mechanism, as well as the weight matrices in the feedforward network (FFN). So, when fine-tuning a model with a Transformer architecture using LoRA, which weight matrices should we prioritize for fine-tuning?
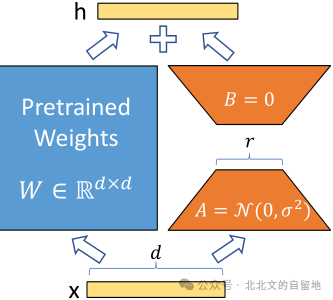
In fact, when using the LoRA method to fine-tune large language models, the most common practice is to choose the Query (Q) and Value (V) matrices in the attention mechanism for fine-tuning, rather than the Key (K) matrix.
This choice is primarily based on the following considerations:
Why Choose Q and V Instead of K?
1. Parameter Impact Efficiency
The Query (Q) and Value (V) matrices play a more direct role in the attention mechanism:
- The Query (Q) determines what the model “pays attention to,” directly affecting the direction of attention allocation.
- The Value (V) determines what information the model “retrieves,” directly affecting the content representation of the output.
In contrast, the Key (K) matrix is mainly used for similarity calculations with the Query, serving as an intermediary in the entire attention mechanism, and has a relatively small direct impact on the final output.
2. Experimental Effect Verification
Extensive practice has shown that fine-tuning Q and V typically yields better performance improvements. Researchers have found through comparative experiments that allocating these parameters to the Q and V matrices under a limited trainable parameter budget can achieve better model adaptability and task performance.
3. Computational Resource Optimization
The core idea of LoRA is to reduce the number of parameters that need to be trained through low-rank decomposition. Under limited computational resources, choosing to fine-tune the matrices that have the most significant impact on model performance is a more economical approach. Fine-tuning the Q and V matrices usually achieves substantial performance improvements with a smaller number of parameters.
4. Working Principle of the Attention Mechanism
From the perspective of the working principle of the attention mechanism:
- The Query (Q) represents the information needed at the current position.
- The Key (K) is used to calculate similarity with the Query to determine attention weights.
- The Value (V) is the actual information that is aggregated with weights.
Fine-tuning Q can change the direction of the model’s focus, while fine-tuning V can change the content of the information the model retrieves. The combination of these two can effectively adjust the model’s adaptability to specific tasks.
What is the Implementation Process of LoRA Fine-Tuning?
In practical applications of LoRA, the fine-tuning process typically includes:
- Selecting target layers: Identifying the layers to which LoRA will be applied, usually the Q and V matrices in the attention layers of the Transformer architecture.
- Initializing low-rank matrices: Creating low-rank decomposition matrices (A and B) for the selected Q and V matrices.
- Freezing original pre-trained weights: Keeping the original model parameters unchanged.
- Training only the newly added low-rank matrices: During training, only updating the parameters introduced by LoRA.
- Merging parameters during inference: Optionally merging LoRA parameters with the original parameters (which can be a weighted merge) without increasing computational overhead during inference.
What to Do If Fine-Tuning Q and V Does Not Yield Good Results?
Although Q and V are the most common choices, depending on the specific task and model characteristics, other combinations may sometimes be used:
- Some researchers may choose a combination of Q and K.
- For certain specific tasks, it may be sufficient to fine-tune only the V matrix.
- In resource-rich situations, it may sometimes be beneficial to fine-tune all three matrices: Q, K, and V.
- In addition to the attention layers, LoRA may also be applied to feedforward network layers.
Conclusion
In PEFT’s LoRA fine-tuning, selecting the Query (Q) and Value (V) matrices is the most common and proven effective approach. This is mainly because these two matrices have a more direct impact on model output, allowing for better performance improvements under a limited parameter budget. However, the specific choice should also be adjusted based on task characteristics, model architecture, and available resources to achieve optimal fine-tuning results.
<span>Previous LoRA-related articles: Key Points You Must Know About LoRA</span>
Key Points You Must Know About LoRA
How Much Do You Know About Dropout in Deep Learning?
Common Downsampling Methods in Deep Learning
Inner Product, Outer Product, Hadamard Product—Several Common Vector Operations in Deep Learning