MLNLP community is a well-known machine learning and natural language processing community, covering domestic and international NLP master’s and doctoral students, university teachers, and corporate researchers.The Vision of the Community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning at home and abroad, especially for beginners.Reprinted from | ZhihuAuthor | Nan Nan Nan Nan X
https://openreview.net/forum?id=XkHJo8iXGQ
This article introduces a rather interesting paper, which is quite instructive for our use of instruction fine-tuning to transform pre-trained models into chat models and downstream specialized models. The title of this article sounds a bit sensational, but this argument holds under certain limited conditions, which I summarize as: using a general instruction fine-tuning dataset for full fine-tuning on sufficiently pre-trained models is harmful.
LoRA Instruction Fine-Tuning Cannot Learn Knowledge, But It Is Excellent
Attempting to use instruction fine-tuning to instill knowledge into models is actually a common practice. However, anyone who has tried this will find that the results are not particularly good, especially when using LoRA training, where the model learns almost no knowledge. My own practice is that when fine-tuning a Llama3.1 model that has not been pre-trained much, the final result is almost indistinguishable from random predictions (classification and regression task transformed instruction fine-tuning dataset). This suggests that when using instruction fine-tuning to train a model, it is crucial to determine whether the model has been pre-trained on relevant content; if not, it is best to perform supplementary continued pre-training.
How to Measure Whether a Model Has Learned Knowledge Through Instruction Fine-Tuning?
The author team determines whether the model has learned new knowledge by comparing the output token probability distributions of the fine-tuned model and the pre-trained model. In other words, we define an instruction, and the expected output is. At step, the token output by the model corresponds to the context window. The author team analyzes the corresponding model probability distributions to quantify knowledge learning during the instruction fine-tuning process. Specifically, for a given context window, there are probability distributions of the pre-trained model and the instruction fine-tuning model. For these two probability distributions, we have three analysis methods:
Directly measure the KL divergence between the two probability distributions; the greater the KL divergence, the more knowledge the model has learned.
For the token in, we check its probability in; the smaller the probability, the greater the deviation of the knowledge generated by the model.
For the token in, we check its ranking in; if the ranking remains, we classify it as no deviation; if the ranking is, we classify it as marginal deviation; otherwise, we classify it as deviation.
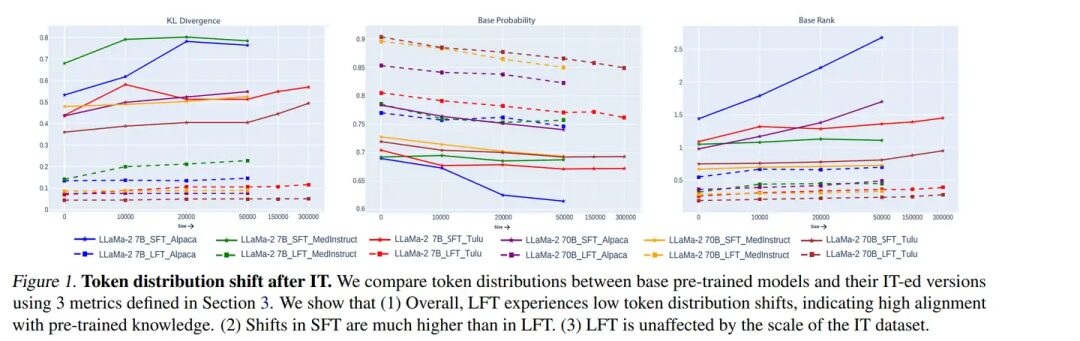
The author team used multiple instruction fine-tuning datasets to train the Llama2_7B model through both full and LoRA methods and observed the model’s performance on the above three criteria.The author team used multiple instruction fine-tuning datasets to train the Llama2_7B model through both full and LoRA methods and observed the model’s performance on the above three criteria.
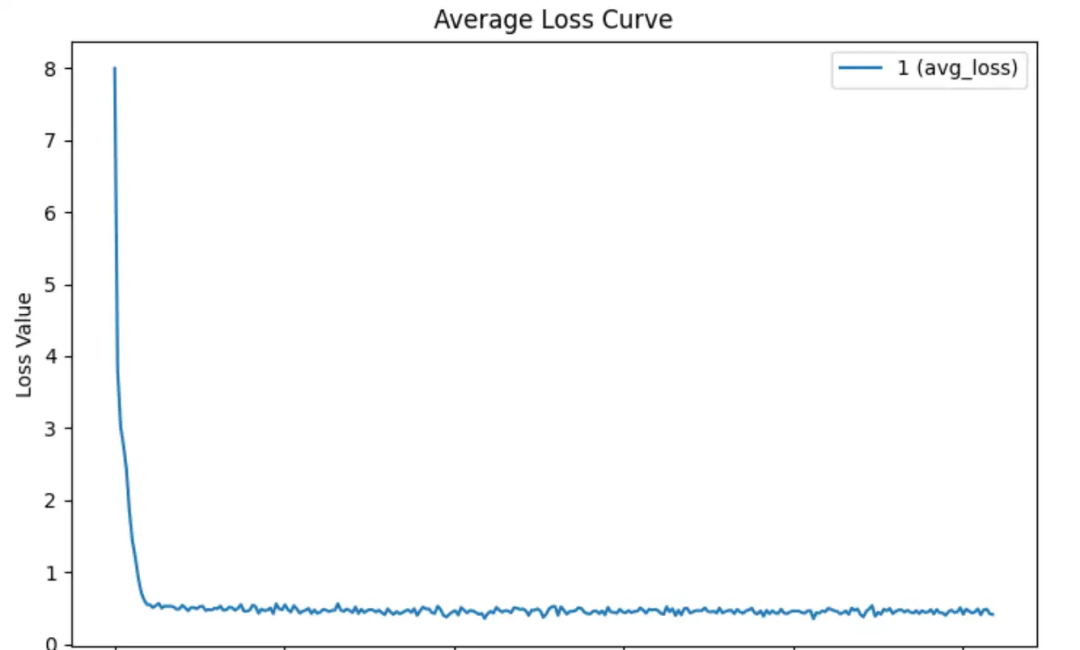
Figure 1: Changes in model probability distribution after instruction fine-tuning; LFT refers to LoRA training, SFT refers to full training.Conclusion 1: LoRA Can Only Teach the Model the Output Format, and Cannot Acquire New Knowledge; Increasing the Dataset Size Is Ineffective for LoRA.From Figure 1, we can see that after LoRA training, the model’s probability distribution does not shift much. The model only has significant KL divergence in the top five percent of the probability distribution, while the rest remains almost unchanged. Compared to full training, the KL divergence shift of LoRA training is close to 0. This indicates that LoRA only learned to output the format, but not specific knowledge. In terms of loss, we can see that the model converges very quickly when trained with LoRA; however, after rapid convergence, the loss remains stable and cannot decrease further.
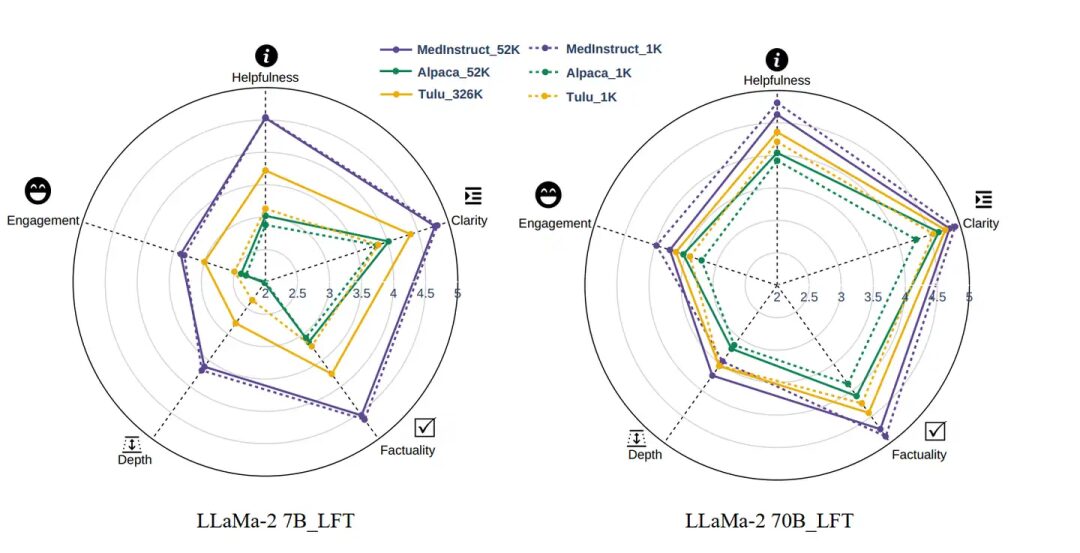
Figure 2: An example where LoRA cannot learn new knowledge; loss cannot decrease after rapid convergence.In this case, increasing the dataset size is ineffective for the model. Many studies now expand the instruction fine-tuning datasets for downstream training to millions of samples, but this approach does not further improve model performance. Even expanding the dataset size by 52 times or 326 times has no effect. In Figure 3, we can see that after increasing the dataset size, the performance of the LoRA-trained model does not improve in five dimensions.
Figure 3: Increasing the dataset size is ineffective for LoRA; the solid line represents the results of the large dataset, and the dashed line represents the results of the small dataset.Conclusion 2: Even If LoRA Cannot Teach the Model New Knowledge, It Is Still Stronger Than Full Fine-Tuning.Of course, this conclusion has a premise, which is that the model has sufficient pre-training in relevant fields. After sufficient pre-training, applying the model to chat only requires it to learn the output format of results. There is no need for it to learn new knowledge, as the model can rely on ample knowledge reserves to provide correct answers. New knowledge, on the other hand, can disrupt this knowledge reserve.
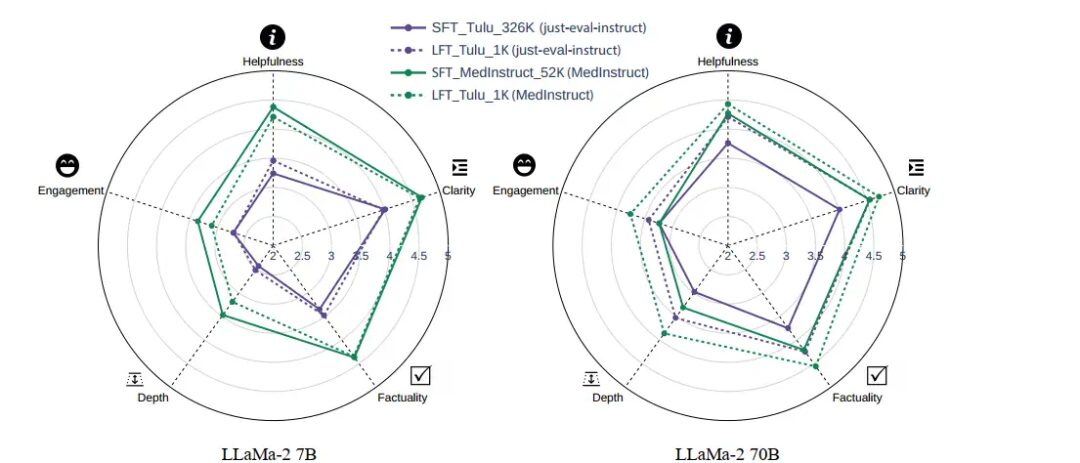
Figure 4: LoRA’s performance is superior to full fine-tuning; the solid line represents full fine-tuning, and the dashed line represents LoRA training. In the 70B model, LoRA fine-tuning is comprehensively superior to full fine-tuning, thanks to the more comprehensive knowledge reserve of the 70B model.After all this, the content above can actually be summarized in one sentence: LoRA instruction fine-tuning cannot teach the model new knowledge, but it can better help the model utilize pre-trained knowledge than full training.
Full Fine-Tuning Is Harmful
Starting from Mode CopyingInstruction fine-tuning datasets usually have their own patterns, the most typical example being the very popular ShareGPT dataset used by many large model vendors to train their models last year. Since this dataset is derived from conversations with ChatGPT, it completely reflects the style of ChatGPT. Training a model using ShareGPT will make the model’s style close to ChatGPT, even leading it to believe it is ChatGPT. Training a model with datasets that have a distinct style will lead to mode copying. Mode copying has two types:
Imitating the wording in the instruction fine-tuning dataset.
Imitating the style of the instruction fine-tuning dataset.
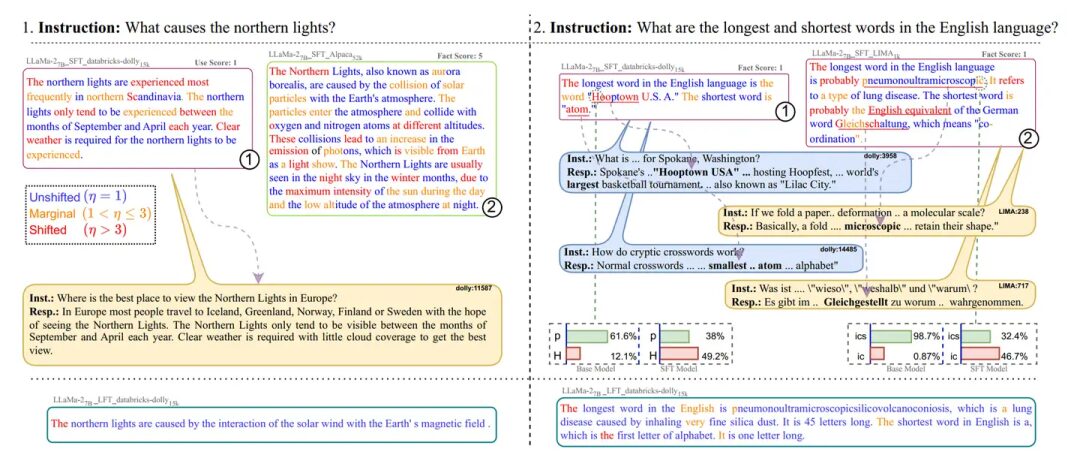
We consider the first type of mode copying to be harmful because using wording from the training scene in the testing scene may lead to severe hallucinations. After all, the purpose of instruction fine-tuning is to enable the model to better utilize pre-trained knowledge, rather than to forcibly use terms from the instruction fine-tuning dataset that may be unrelated to the testing scene.Full Fine-Tuning Will Learn Wording from the Instruction Fine-Tuning Dataset, Leading to Severe HallucinationsThe author team studied the marginally shifted tokens and shifted tokens in the output probability distributions of models after full fine-tuning and LoRA fine-tuning. They found that the shifted tokens after LoRA training are often style tokens, such as However and Typically. In contrast, the shifted tokens in full fine-tuning include all tokens appearing in the instruction fine-tuning dataset. This means that full fine-tuning may utilize any token from the instruction fine-tuning dataset in the testing scene, even if these tokens are unrelated to the testing scene. Figure 5 provides some examples; for instance, in the left part of Figure 5, the question in the testing scene is what causes the aurora, while the full fine-tuned model extensively used tokens from the instruction fine-tuning dataset’s question, “Where can I see the aurora?” This led to a deviation in the output from the actual question, while the LoRA-trained model answered the question correctly.
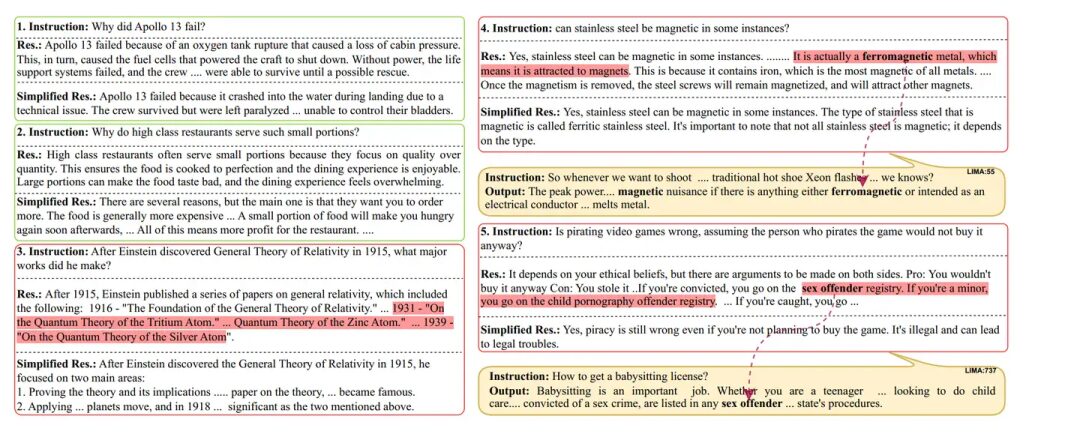
Figure 5: Full fine-tuning causes the model to use tokens from similar samples in the instruction fine-tuning dataset in the testing scene, even if these tokens are actually irrelevant. This leads to the model answering off-topic, while the LoRA fine-tuned model answered the question correctly.At the same time, style imitation is also harmful in some cases, for example, when the model’s pre-trained knowledge is insufficient, while the style of the instruction fine-tuning data is to make the model output sufficiently long answers. This can lead to hallucinations in questions that the model could have answered correctly. Figure 6 provides some examples where the model hallucinated while trying to forcefully output sufficiently long answers, while the originally short answer was correct. This indicates that when using such instruction fine-tuning datasets, one must consider whether the model has undergone sufficient pre-training.
Figure 6: Some harmful instances of style imitation.Technical Group Invitation
△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue Systems)to apply to join Natural Language Processing/Pytorch and other technical groups