
This is the experience derived from hundreds of experiments by the author Sebastian Raschka, and it is worth reading.
Increasing the amount of data and the number of model parameters is recognized as the most direct way to improve neural network performance. Currently, the parameters of mainstream large models have expanded to the trillion level, and the trend of “large models” will only intensify.
This trend brings various computational challenges. Fine-tuning a large language model with a trillion-level parameter count not only takes a long training time but also requires a large amount of high-performance memory resources.
To reduce the cost of fine-tuning large models, researchers at Microsoft developed Low-Rank Adaptation (LoRA) technology. The brilliance of LoRA lies in the fact that it adds a detachable plugin on top of the existing large model, keeping the main model unchanged. LoRA is lightweight and easy to use.
LoRA is one of the most widely used and effective methods for efficiently fine-tuning a customized large language model.
If you are interested in open-source LLMs, LoRA is a fundamental technology worth learning and should not be missed.
Professor Sebastian Raschka from the University of Wisconsin-Madison has conducted a comprehensive exploration of LoRA. After years of exploration in the field of machine learning, he is very passionate about breaking down complex technical concepts. After hundreds of experiments, Sebastian Raschka summarized his experiences in fine-tuning large models using LoRA and published them in Ahead of AI magazine.

On the basis of preserving the author’s original meaning, Machine Heart has translated this article:
Last month, I shared an article about LoRA experiments, mainly based on the open-source Lit-GPT library maintained by my colleagues at Lightning AI, discussing the main experiences and lessons I learned from the experiments. Additionally, I will answer some common questions related to LoRA technology. If you are interested in fine-tuning customized large language models, I hope these insights can help you get started quickly.
In short, the main points I discuss in this article include:
-
Although LLM training (or all models trained on GPUs) has inevitable randomness, the results of multi-lun training are still very consistent.
-
If limited by GPU memory, QLoRA provides a cost-effective compromise. It saves 33% of memory at the cost of a 39% increase in runtime.
-
When fine-tuning LLMs, the choice of optimizer is not the main factor affecting the results. Whether it is AdamW, SGD with a scheduler, or AdamW with a scheduler, the impact on the results is minimal.
-
Although Adam is often considered a memory-intensive optimizer because it introduces two new parameters for each model parameter, this does not significantly affect the peak memory requirements of LLMs. This is because most memory will be allocated for large matrix multiplications rather than for storing additional parameters.
-
For static datasets, multiple iterations in multi-lun training may not perform well. This often leads to overfitting and deteriorates training results.
-
If you want to combine LoRA, ensure it is applied across all layers, not just in the Key and Value matrices, to maximize the model’s performance.
-
Tuning the LoRA rank and selecting an appropriate α value is crucial. A little tip: try setting the α value to twice the rank value.
-
A single GPU with 14GB of RAM can efficiently fine-tune a model with 7 billion parameters in a few hours. For static datasets, it is impossible to make an LLM a “jack-of-all-trades” that performs excellently on all baseline tasks. Solving this problem requires a diverse data source or the use of techniques other than LoRA.
Additionally, I will answer ten common questions related to LoRA.
If readers are interested, I will write another article providing a more comprehensive introduction to LoRA, including detailed code for implementing LoRA from scratch. Today’s article mainly shares key issues in using LoRA. Before we officially start, let’s supplement some basic knowledge.
Introduction to LoRA
Due to the limitations of GPU memory, updating model weights during training is costly.
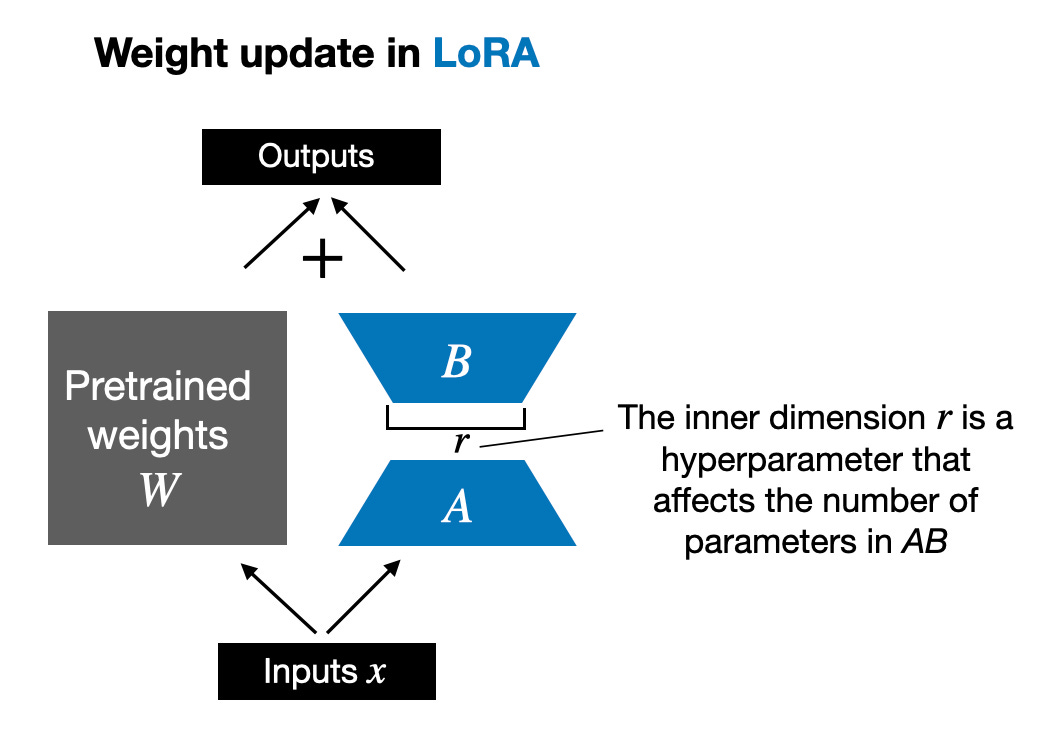
For example, suppose we have a language model with 7B parameters, represented by a weight matrix W. During backpropagation, the model needs to learn a ΔW matrix, which aims to update the original weights to minimize the loss function value.
The weight update is as follows: W_updated = W + ΔW.
If the weight matrix W contains 7B parameters, then the weight update matrix ΔW also contains 7B parameters, making the computation of ΔW very resource-intensive.
LoRA, proposed by Edward Hu et al., decomposes the part of weight change ΔW into a low-rank representation. Specifically, it does not require explicitly calculating ΔW. Instead, LoRA learns the decomposed representation of ΔW during training, as shown in the diagram below, which is the secret of LoRA saving computational resources.
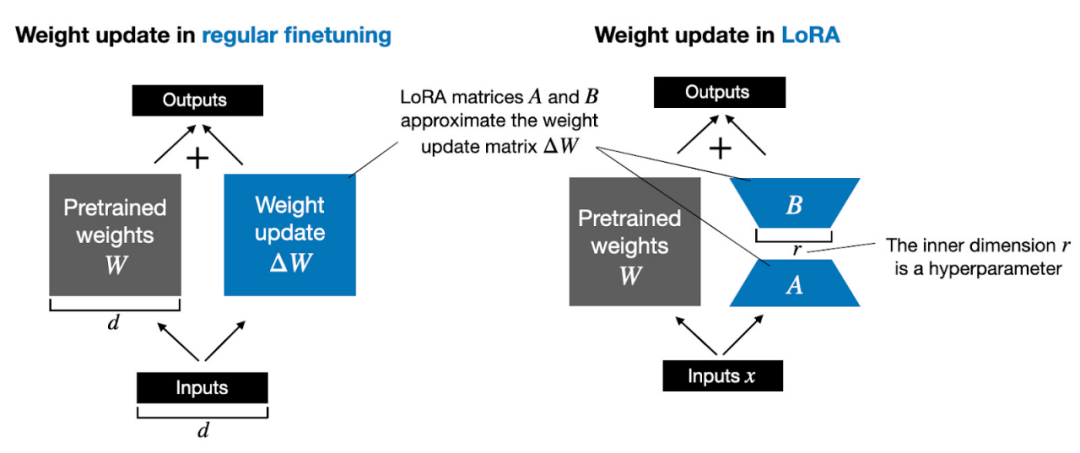
As shown above, the decomposition of ΔW means we need to use two smaller LoRA matrices A and B to represent the larger matrix ΔW. If A has the same number of rows as ΔW and B has the same number of columns as ΔW, we can express the decomposition as ΔW = AB. (AB is the result of the matrix multiplication between matrices A and B.)
How much memory does this method save? It still depends on the rank r, which is a hyperparameter. For example, if ΔW has 10,000 rows and 20,000 columns, it requires storing 200,000,000 parameters. If we choose A and B with r=8, then A has 10,000 rows and 8 columns, and B has 8 rows and 20,000 columns, resulting in 10,000×8 + 8×20,000 = 240,000 parameters, which is about 830 times less than 200,000,000 parameters.
Of course, A and B cannot capture all the information covered by ΔW, but this is determined by the design of LoRA. When using LoRA, we assume that model W is a full-rank large matrix that gathers all the knowledge from the pre-training dataset. When we fine-tune LLMs, it is not necessary to update all weights, only a smaller number of weights than ΔW need to be updated to capture the core information, which is achieved through the AB matrix via low-rank updates.
Consistency of LoRA
Although the randomness of LLMs, or models trained on GPUs, is inevitable, experiments using LoRA show that the final benchmark results of LLMs exhibit remarkable consistency across different test sets. This provides a good foundation for conducting other comparative studies.
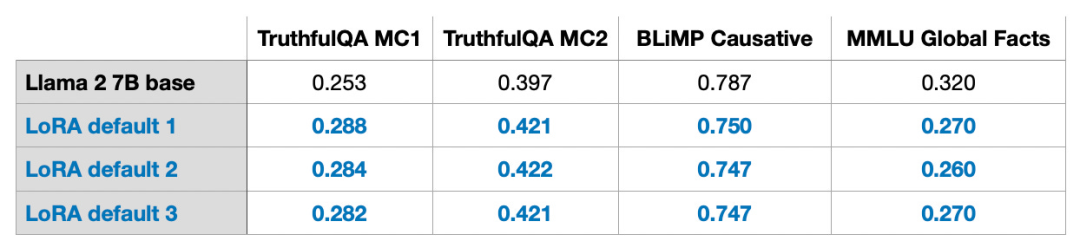
Please note that these results were obtained under default settings, using a lower value of r=8. Experimental details can be found in another article of mine.
Article link: https://lightning.ai/pages/community/lora-insights/
QLoRA Computation – Memory Trade-offs
QLoRA, proposed by Tim Dettmers et al., is short for Quantized LoRA. QLoRA is a technique that further reduces memory usage during fine-tuning. During backpropagation, QLoRA quantizes the pre-trained model weights to 4 bits and uses a paging optimizer to handle memory peaks.
I found that using LoRA can save 33% of GPU memory. However, due to the additional quantization and dequantization of pre-trained model weights in QLoRA, training time increased by 39%.
Default LoRA has 16-bit floating-point precision:
-
Training time: 1.85 hours
-
Memory usage: 21.33GB
With 4-bit normal floating-point QLoRA:
-
Training time: 2.79 hours
-
Memory usage: 14.18GB
Additionally, I found that the model’s performance was almost unaffected, indicating that QLoRA can serve as an alternative to LoRA training, further addressing common GPU memory bottleneck issues.

Learning Rate Scheduler
The learning rate scheduler reduces the learning rate throughout the training process to optimize the model’s convergence and avoid excessive loss values.
Cosine annealing is a scheduler that adjusts the learning rate following a cosine curve. It starts with a higher learning rate and then smoothly decreases, approaching 0 in a cosine-like pattern. A common variant of cosine annealing is the half-cycle variant, which completes only half a cosine cycle during training, as shown in the diagram below.
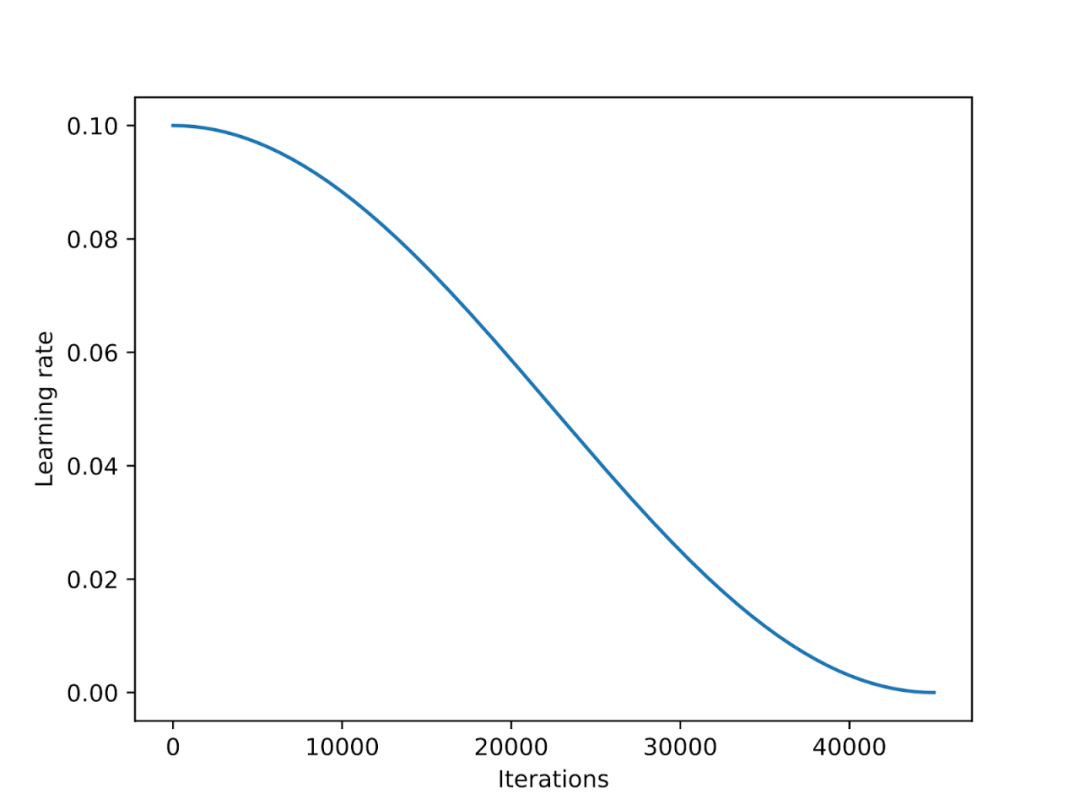
In my experiments, I added a cosine annealing scheduler to the LoRA fine-tuning script, which significantly improved the performance of SGD. However, it had little gain for Adam and AdamW optimizers, with almost no change after adding it.
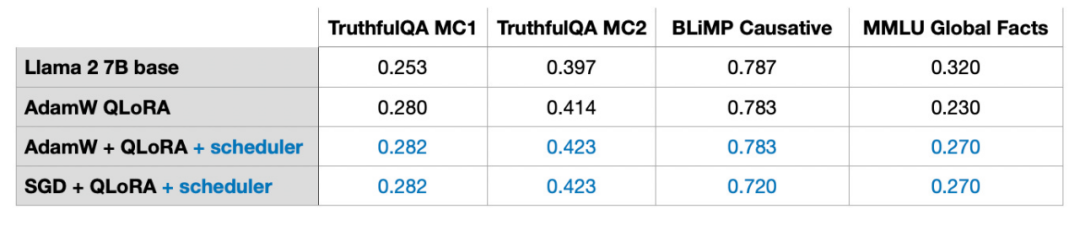
In the next section, I will discuss the potential advantages of SGD compared to Adam.
Adam vs SGD
Adam and AdamW optimizers are popular in deep learning. If we are training a model with 7B parameters, using Adam allows us to track an additional 14B parameters during training, effectively doubling the model’s parameter count under unchanged conditions.
SGD cannot track additional parameters during training, so what advantages does SGD have over Adam in terms of peak memory?
In my experiments, training a 7B parameter Llama 2 model using AdamW and LoRA (default settings r=8) required 14.18 GB of GPU memory. Training the same model with SGD required 14.15 GB of GPU memory. Compared to AdamW, SGD only saved 0.03 GB of memory, which is negligible.
Why is the memory savings so small? This is because using LoRA has already significantly reduced the model’s parameter count. For example, if r=8, out of the 6,738,415,616 parameters of the 7B Llama 2 model, only 4,194,304 are trainable LoRA parameters.
Looking at the numbers, 4,194,304 parameters may still seem like a lot, but they only occupy 4,194,304 × 2 × 16 bits = 134.22 megabits = 16.78 megabytes. (We observed a 0.03 Gb = 30 Mb difference, which is due to the additional overhead when storing and copying optimizer states.) The 2 represents the number of extra parameters stored by Adam, and the 16 bits refer to the default precision of model weights.
If we expand the rank of the LoRA matrix from 8 to 256, the advantages of SGD over AdamW will become apparent:
-
Using AdamW would occupy 17.86 GB of memory
-
Using SGD would occupy 14.46 GB of memory
Therefore, as the matrix size increases, the memory saved by SGD will play an important role. Since SGD does not need to store additional optimizer parameters, it can save more memory compared to other optimizers like Adam when dealing with large models. This is a significant advantage for memory-constrained training tasks.
Iterative Training
In traditional deep learning, we often perform multiple iterations on the training set, with each iteration referred to as an epoch. For example, when training a convolutional neural network, it is common to run hundreds of epochs. So, does multi-iteration training also work for instruction fine-tuning?
The answer is no. When I doubled the iteration count of the Alpaca example instruction fine-tuning dataset with a data size of 50k, the model’s performance decreased.

Thus, I conclude that multiple iterations may be detrimental to instruction fine-tuning. I observed the same situation in the 1k example LIMA instruction fine-tuning set. The decline in model performance may be due to overfitting, and the specific reasons still need further exploration.
Using LoRA in More Layers
The table below shows the experiments where LoRA only works on selected matrices (i.e., the Key and Value matrices in each Transformer). Additionally, we can enable LoRA between other linear layers, such as query weight matrices, projection layers, multi-head attention modules, and output layers.

If we add LoRA on these additional layers, the number of trainable parameters for the 7B Llama 2 model will increase from 4,194,304 to 20,277,248, a fivefold increase. Applying LoRA in more layers can significantly improve model performance, but it also requires higher memory space.
Moreover, I only explored (1) enabling LoRA only on query and weight matrices, and (2) enabling LoRA on all layers. It is worth further investigating what effects using LoRA across more layer combinations will have. If we can understand whether using LoRA on projection layers benefits training results, we can better optimize the model and improve its performance.
Balancing LoRA Hyperparameters: R and Alpha
As stated in the paper proposing LoRA, LoRA introduces an additional scaling factor. This factor is used to apply LoRA weights during forward propagation. The scaling involves the previously discussed rank parameter r, as well as another hyperparameter α (alpha), applied as follows:

As shown in the formula in the above image, the larger the value of LoRA weights, the greater the impact.
In my previous experiments, I used parameters r=8, alpha=16, which resulted in a 2x scaling. When reducing the weight of large models with LoRA, setting alpha to twice the rank value is a common rule of thumb. However, I am curious whether this rule still applies to larger r values.
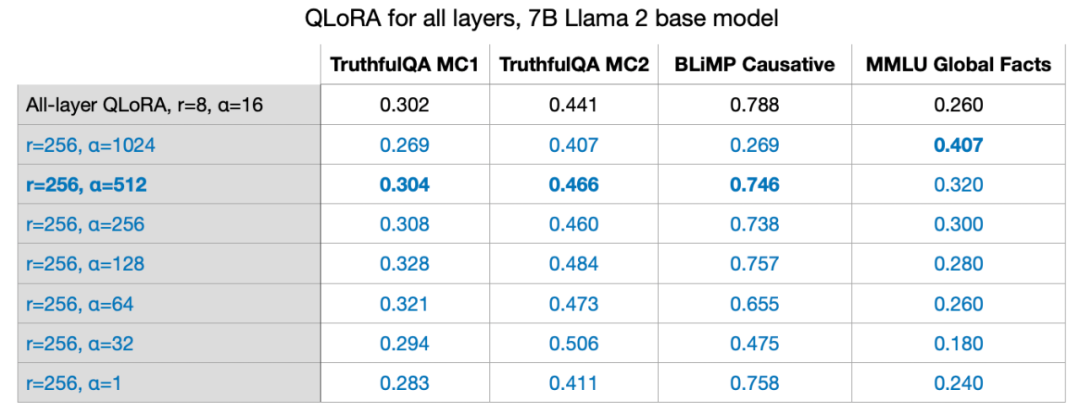
I also tried r=32, r=64, r=128, and r=512, but omitted this process for clarity. However, r=256 indeed yielded the best results. In fact, choosing alpha=2r provided the optimal outcome.
Training a 7B Parameter Model on a Single GPU
LoRA allows us to fine-tune a large language model with 7B parameters on a single GPU. In this specific case, using the optimally set QLoRA (r=256, alpha=512), processing 17.86 GB (50k training samples) of data on an A100 takes about 3 hours (here using the Alpaca dataset).

In the remainder of this article, I will answer other questions you may encounter.
10 Questions
Q1: How important is the dataset?
The dataset is crucial. I used the Alpaca dataset, which contains 50k training samples. I chose Alpaca because it is very popular. Since this article is already lengthy, I will not discuss the test results on more datasets here.
Alpaca is a synthetic dataset, and by today’s standards, it may be somewhat outdated. The quality of the data is critical. For example, in June, I discussed the LIMA dataset in an article, which consists of a carefully selected dataset of only a thousand examples.
Article link: https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-dataset
As the title of the paper proposing LIMA states: Less is more for alignment. Although LIMA has fewer data than Alpaca, the results of the 65B Llama model fine-tuned on LIMA outperform those of Alpaca. Using the same configuration (r=256, alpha=512), I achieved model performance similar to that of Alpaca, which is 50 times larger in data volume.
Q2: Is LoRA suitable for domain adaptation?
I currently do not have a clear answer to this question. Based on experience, knowledge is usually extracted from the pre-training dataset. Generally, language models absorb knowledge from pre-training datasets, while instruction fine-tuning mainly helps LLMs better follow instructions.
Since computational power constraints are a key factor limiting the training of large language models, LoRA can also be used on specialized datasets in specific domains to further pre-train existing pre-trained LLMs.
Additionally, it is worth noting that my experiments included two arithmetic benchmark tests. In both benchmark tests, models fine-tuned with LoRA performed significantly worse than the pre-trained base model. I speculate this is due to the Alpaca dataset lacking corresponding arithmetic examples, causing the model to “forget” arithmetic knowledge. We need further research to determine whether the model “forgot” arithmetic knowledge or stopped responding to the corresponding instructions. However, it can be concluded here that “when fine-tuning LLMs, it is a good idea to include examples of every task we care about in the dataset.”
Q3: How to determine the optimal r value?
I currently do not have a good solution for this question. The optimal r value needs to be determined based on the specific situation of each LLM and each dataset, with a specific analysis for each case. I suspect that a value of r that is too large will lead to overfitting, while a value that is too small may not allow the model to capture the diverse tasks in the dataset. I suspect that the more diverse the task types in the dataset, the larger the required r value. For example, if I only need the model to perform basic two-digit arithmetic operations, a very small r value may already suffice. However, this is just my hypothesis and needs further research to verify.
Q4: Does LoRA need to be enabled for all layers?
I only explored (1) enabling LoRA only on query and weight matrices and (2) enabling LoRA on all layers. It is worth further investigating what effects using LoRA across more layer combinations will have. If we can understand whether using LoRA on projection layers benefits training results, we can better optimize the model and improve its performance.
If we consider various settings (lora_query, lora_key, lora_value, lora_projection, lora_mlp, lora_head), there are 64 combinations to explore.
Q5: How to avoid overfitting?
In general, a larger r is more likely to lead to overfitting because r determines the number of trainable parameters. If the model has overfitting issues, the first consideration should be to reduce the r value or increase the size of the dataset. Additionally, one can try increasing the weight decay rate of the AdamW or SGD optimizer or increasing the dropout value of the LoRA layers.
I did not explore the dropout parameter of LoRA in my experiments (I used a fixed dropout rate of 0.05), but the dropout parameter of LoRA is also a research-worthy issue.
Q6: Are there other optimizers to choose from?
Sophia, released in May this year, is worth a try. Sophia is a scalable stochastic second-order optimizer for language model pre-training. According to the following paper: “Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training,” Sophia is twice as fast as Adam while achieving better performance. In short, both Sophia and Adam normalize based on gradient curvature rather than gradient variance.
Paper link: https://arxiv.org/abs/2305.14342
Q7: Are there other factors affecting memory usage?
Besides precision and quantization settings, model size, batch size, and the number of trainable LoRA parameters, the dataset also affects memory usage.
The block size of Llama 2 is 4048 tokens, which means Llama can process sequences containing 4048 tokens at once. If masks are applied to later tokens, the training sequence will become shorter, saving a lot of memory. For example, the Alpaca dataset is relatively small, with the longest sequence length being 1304 tokens.
When I tried using other datasets with a maximum sequence length of 2048 tokens, memory usage soared from 17.86 GB to 26.96 GB.
Q8: What advantages does LoRA have compared to full fine-tuning and RLHF?
I did not conduct RLHF experiments, but I tried full fine-tuning. Full fine-tuning requires at least 2 GPUs, each occupying 36.66 GB, taking 3.5 hours to complete fine-tuning. However, the baseline test results were poor, possibly due to overfitting or suboptimal hyperparameters.
Q9: Can LoRA weights be combined?
The answer is yes. During training, we separate LoRA weights from pre-trained weights and add them during each forward pass.
Assuming there is an application in the real world with multiple sets of LoRA weights, with each set corresponding to a user’s application, it makes sense to store these weights separately to save disk space. At the same time, after training, we can merge pre-trained weights with LoRA weights to create a single model. This way, we do not need to apply LoRA weights during each forward pass.

We can update the weights as shown above and save the merged weights.


Scan the QR code to add the assistant’s WeChat
About Us
