Analysis Report on DeepSeek-V2 MLA (Multi-Head Latent Attention) Technology

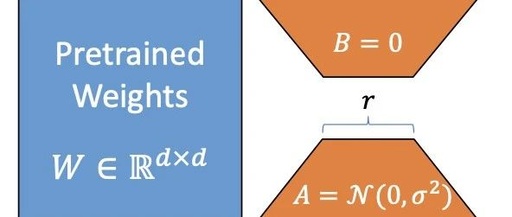
1. Core Objective MLA (Multi-Head Latent Attention) is an innovative attention mechanism designed to address the inference efficiency issues caused by the excessively large KV cache in traditional Transformer models. Its core objective is to significantly reduce memory usage (KV cache) during inference through low-rank compression and decoupled positional encoding, while maintaining or even improving … Read more