
This article starts from the planning module in the Copilot 3.0 architecture, combining the reinforcement learning (GRPO) training practices of DeepSeek R1, to explore how large models can flexibly orchestrate multiple agents under a multi-agent architecture to better solve practical problems.

GRPO Training Table
Background
1. Business Scenario
Merchants operate Copilot as a professional business assistant, primarily serving merchants in various issues encountered in daily operations. Its core functions include:
-
Basic business support: merchant onboarding, product signing, operation tool usage, etc.;
-
Operational services: reconciliation, data analysis, strategy recommendations, etc.;
-
Intelligent optimization: keyword configuration, banner generation, product image optimization, etc.;
Experience entry: Search for “Alipay Merchant Assistant” mini-program in the Alipay APP. Open the mini-program to directly experience the business assistant Copilot. Currently, core functions only support merchants registered on Alipay.
From the perspective of solving user problems, Copilot needs to possess the following core capabilities:
1. Comprehensive web search and natural language answering
2. Business data analysis and visualization
3. Intelligent matching of platform strategies
4. Image material generation and optimization
5. Precise user group targeting
2. Problem Analysis
In summarizing the limitations of the Copilot 2.0 framework, we identified the following core issues:
-
A single LLM architecture struggles to balance business needs with general capabilities;
-
Submodule capabilities such as intent recognition, query rewriting, and task planning are limited;
-
Insufficient efficiency in handling complex queries;
Based on these challenges, we made significant upgrades to the Copilot architecture in CY25, launching version 3.0. This version adopts a Multi-Agent architecture, achieving intelligent agent scheduling through the planning model, significantly enhancing the system’s problem-solving capabilities.
3. The Role of Planning
Planning is more like solving a complex combinatorial problem. Under the premise of fully understanding the user’s question (context), it assigns the user’s question to one or more suitable experts to solve the problem. This is a complex task that includes rewriting, decomposition, allocation, and generating execution sequences. For such complex tasks, we first think of using CoT to improve accuracy. In the planning module of Copilot 2.0 in CY24, we first attempted a short CoT model, which yielded good results. After comparing the planning accuracy of “without thinking process” and “with thinking process,” we decided to continue using last year’s CoT method and upgrade the model on this basis, explicitly printing the model’s thinking process to help users understand that multiple agents will jointly serve their questions.
For example, if there are three agents (abc), theoretically, there are at least 15 different planning allocation schemes. Combined with the user’s question, we assign each expert the corresponding problem to solve.
Difficulties
1. How to have both fish and bear’s paw
Those who have used the DeepSeek R1 deep thinking model understand that sometimes when the model starts thinking, it just can’t stop.The thinking process is too long, and the output gets stuck; simple problems are repeatedly verified, leading to circular reasoning. Deep thinking is designed for complex problems, but this also causes the model to develop a habit of repeated verification. The challenge we face now is to ensure accuracy for complex problems while allowing the thinking process for simple problems to be “quick and decisive,” saving reasoning costs and improving user experience.
2. How to annotate the thinking process
It is said that much of the data for the DeepSeek model is annotated by students from Peking University’s Chinese Department, but most of our assistants are not majoring in Chinese. How can we write a thinking process that is both business-compliant and logical? Annotating a segment of the thinking process takes a long time, and the acceptance cost is high. Is it really necessary to write it manually? Annotating data with a thinking process requires higher standards for our synthetic data.
3. Do historical data need to be re-annotated with each product iteration?
Business iterations are frequent; today there may be 5 agents, and tomorrow it may upgrade to 8 agents. Does that mean historical annotated data cannot be used? It is also important to ensure the model’s iteration efficiency at low cost in the face of business changes.
Effect Comparison
1. From Case Studies
1.1. Multi-Agent Case Comparison
|
Query |
Copilot 3.0 |
Copilot 2.0 |
|
User Question: How to configure search keywords Comparative Analysis: Copilot 3.0’s planning module assigns the user’s question to knowledge Q&A and strategy recommendation experts. Even if the user asks an operational question, it also recommends suitable strategies for the user, making one-click operations more convenient. It anticipates the user’s expectations. Execution Plan: Knowledge Q&A Expert -> Strategy Recommendation Expert Copilot 2.0 directly identifies the intent as knowledge Q&A and responds to the user in FAQ format. Although this is not wrong, it is not intelligent enough. |
|
 |

1.2. Thinking Length Comparison
| Query | Before GRPO | After GRPO |
| Recommendation Today’s news | 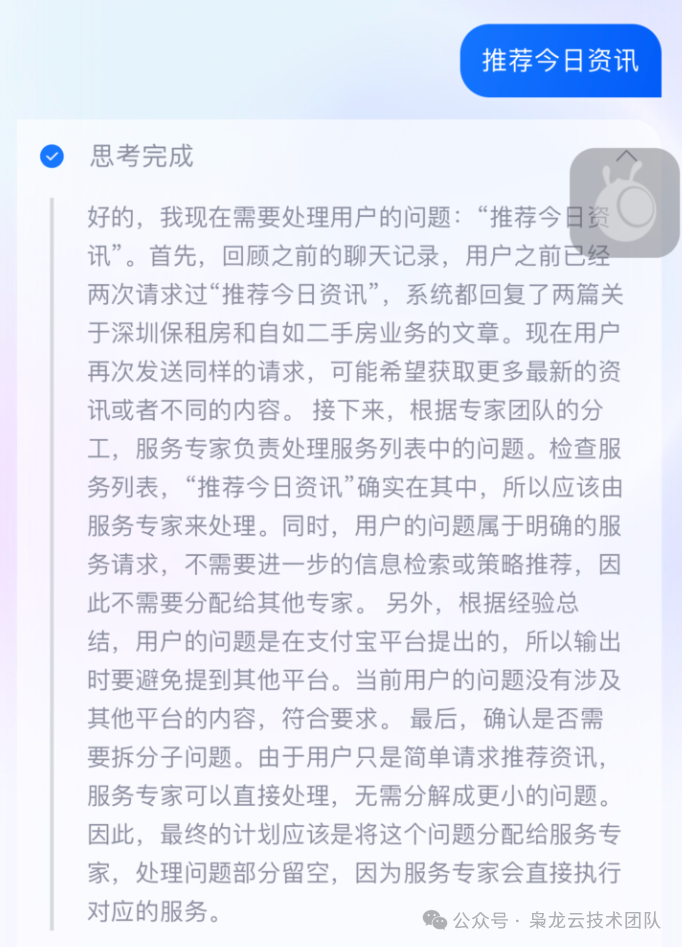 |
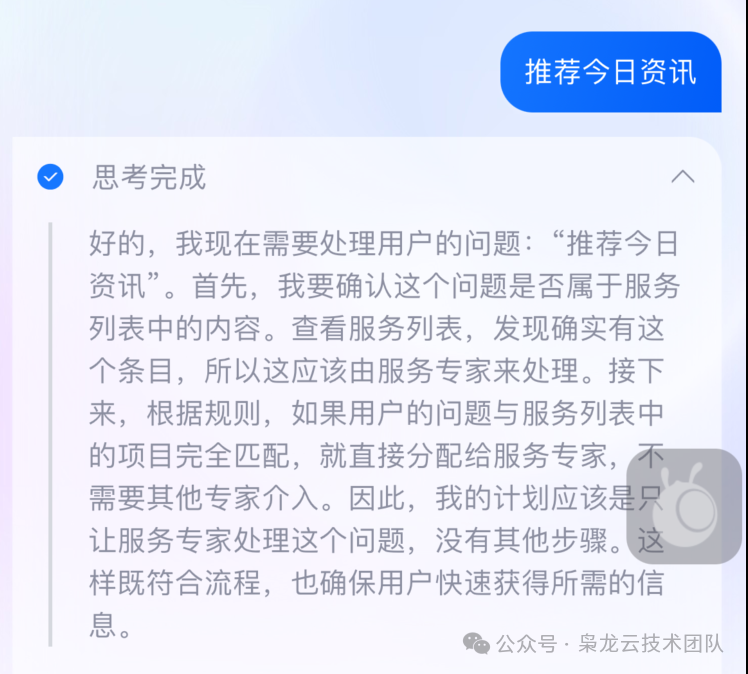 |
2. From Metrics
After GRPO training, the average reasoning length decreased from240.29 to93.28 (a decrease of61.2%), and the length variability improved significantly (standard deviation decreased from 77.30 to 26.11), with the distribution becoming more concentrated.
At the same time, accuracy increased from78.7% to86.1%, an absolute increase of 7.4 percentage points, and a relative increase of9.4%.
This also verifies that GRPO training can improve both accuracy and thinking length (i.e., reasoning costs) while ensuring model precision.
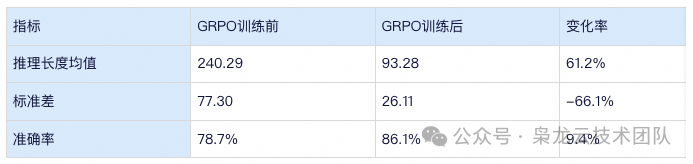
(The above results were obtained by running batches on 3217 annotated data)
Solution
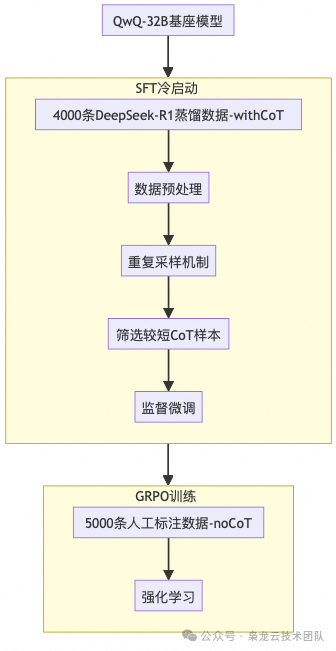
1. Dataset Construction
1.1. Input and Output Definition
Input Dimensions
-
Historical context window: using a dynamic sliding window (N rounds of dialogue)
-
Expert list: Agent capabilities supported in Copilot
-
Data analysis tool list
-
Product service list
-
…
Output Format
-
Thinking process
-
Planning results (completed question + expert sequence + problems handled by experts + execution order)
<think>Okay, I now need to handle the user's question: "View the business weekly report." First, based on the provided tool list, the user's question falls under one of the items. Therefore, this question should be handled by the data analysis expert, as they are responsible for querying and analyzing data from the tool list. Next, check if there are any other related sub-questions that need to be decomposed, but the user's question is very clear, so no further decomposition is needed. Finally, confirm whether other experts need to be involved, but only the data analysis expert is needed here.</think>
<answer>{ "Completed Question": "View the business weekly report", "plan": [{ "Expert": "Data Analysis Expert", "Handled Problems": ["View the business weekly report"] }]}</answer>1.2. Cold Start Data
Using DeepSeek R1 to extract synthetic data (thinking process + planning results), filtering for shorter samples for training in the SFT phase. This phase mainly allows the model to learn to output in a specific format.
1.3. Manually Annotated Data
Manually annotated synthetic data (only planning results) for GRPO training. By manually annotating, we ensure the model’s accuracy and consistency in planning results, providing high-quality training data for subsequent reinforcement learning.
2. Multi-Stage Training (SFT + GRPO)
If SFT is exam-oriented education, GRPO is quality education, giving the model a range to explore and find the next iteration direction from better answers. I won’t elaborate on SFT training here; below is a detailed explanation of the GRPO training process.
2.1. Training Configuration
|
Base |
QwQ-32B |
|
GPU Configuration |
3 machines with 24 A100 cards |
|
Parameter Configuration |
Important settings include |
|
Training Framework |
ModelScope’s ms-swift |
2.2. Reward Function Design
The reward system mainly unfolds from three directions, involving seven different reward functions, which can be weighted based on the importance of each part.
For example:
Reward = 0.1 * StrictFormatReward + 0.1 * JSONValidReward + 0.1*ThinkLengthReward + 0.1 * ThinkQualityReward + 0.2 * CorrectnessReward + 0.3 * ExpertValidationReward + 0.1 * ProcessingQualityRewardMulti-Dimensional Reward System

Format Integrity Assessment
-
StrictFormatReward: Regex matching for XML tag structure validity;
class StrictFormatReward(BaseReward): _pattern = re.compile(r"^<think>\n.*?\n</think>\n\n<answer>\n.*?\n</answer>$", re.DOTALL)
def __call__(self, completions, **kwargs) -> List[float]: processed = self.preprocess(completions) return [1.0if p.answer and self._pattern.match(c) else0.0 for c, p in zip(completions, processed)]-
JSONValidReward: Validates the integrity and compliance of the JSON structure and fields;
Thinking Process Assessment
-
ThinkLengthReward: Limits the length of the thinking text;
class ThinkLengthReward(BaseReward): def __call__(self, completions, **kwargs) -> List[float]: processed = self.preprocess(completions) rewards = [] for p in processed: try: length = len(p.think) if min_length <= length <= max_length: rewards.append(1.0) else: # Use S-curve to calculate penalty deviation = abs(length - mid)/eps # reward = 1.0 / (1.0 + np.exp(5*(deviation-0.5))) # Smooth transition rewards.append(float(reward)) except Exception as e: logger.error(f"Error calculating think length reward: {e}") rewards.append(0.0) return rewards-
ThinkQualityReward: Keyword filtering mechanism (e.g., detection of sensitive words like “WeChat”);
Answer Accuracy Assessment
-
CorrectnessReward: Rewriting accuracy, multi-dimensional assessment (semantic similarity/coverage);
-
ExpertValidationReward: Accuracy of expert assignment;
-
ProcessingQualityReward: Planning accuracy, multi-dimensional assessment (semantic similarity/coverage/diversity);
3. Multi-Task Mixed Training
GRPO can effectively ensure the model’s generalization ability. For the task of assigning agents, the model learns to choose the more suitable agent from a given list. If new agents are to be added, new task data can be added based on the original dataset. GRPO training is conducted on the basis of the SFT model. We mix historical data with the data after iteration for training, which does not affect the model’s performance. During inference, using the latest inference prompt can meet the iterative effect.
For example:
Due to business changes, questions originally assigned to the “Strategy Agent” need to be partially reassigned to the “Crowd Operation Agent”.
ToDo: Add the “Crowd Operation Agent” to the expert list in the prompt, and add relevant training data, mixing it with historical data.
Tips: There is no need to change historical data because the historical prompt’s expert list does not include the “Crowd Operation Agent”; the “Strategy Agent” is the optimal choice for the current problem.
Experimental Phenomena
1. With Thinking Process
1.1. Direct GRPO
Phenomenon:
All reward functions start from a relatively low value and oscillate, with the reward ultimately converging between 0.5 and 0.6.
1.2. SFT First, Then GRPO
Phenomenon:
1. The model’s adherence to format and answer quality is relatively high from the start.
2. As the model iterates, rewriting, expert selection, and planning rewards all improve.
3. The length of thinking significantly decreases and ultimately converges around 150.
4. The reward ultimately converges around 0.9.
2. Without Thinking Process
SFT First, Then GRPO
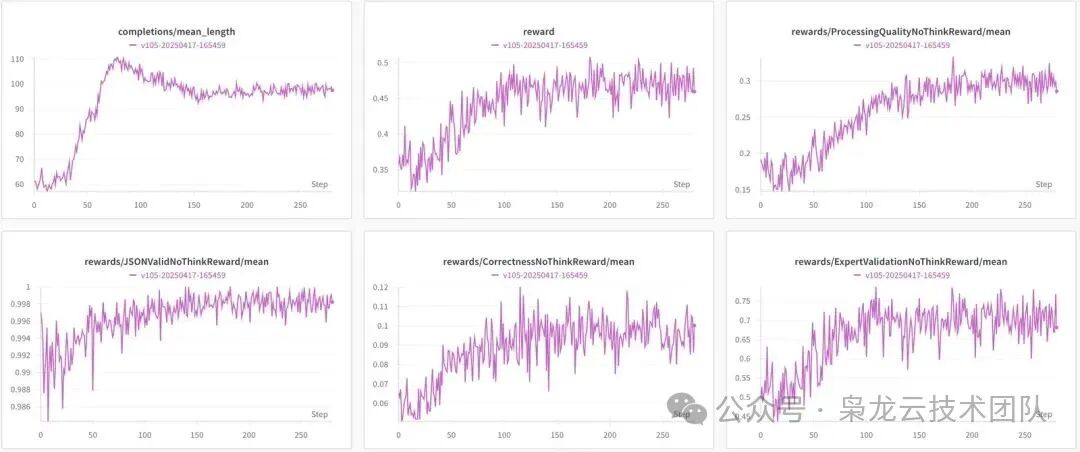
Phenomenon:
1. After GRPO, the model’s capabilities without a thinking process can also improve to some extent;
2. The model’s average output length increases, ultimately stabilizing around 100 tokens;
3. The rewriting ability remains weak, possibly requiring a review of prompt and data quality.
Cloud-Based Classic Architecture Serverless Version
This solution adopts a cloud-based Serverless architecture, natively supporting elastic scaling, pay-as-you-go, and service hosting, reducing the manual resource management and performance cost optimization work for enterprises, while avoiding potential single-point failure risks through high availability configurations.
Click to read the original text for details.