Recently, Anthropic and Devin each published a blog post, one advocating for the use of Multi-Agent systems and the other arguing against it. Their viewpoints seem completely opposite, but in fact, they are not.
One discusses how to be an ‘Engineer’, while the other talks about how to be a ‘Researcher’. Although their perspectives appear to be diametrically opposed, this is simply due to the differing requirements of the two ‘roles’.
Anthropic’s article clearly states at the beginning that they are building a research type of Agent, whose working method involves searching for as much information as possible on the internet, thoroughly understanding complex problems, and ultimately producing a comprehensive report that considers all aspects. The Agent they developed is essentially a ‘Researcher’.
The article from Cognition (the company that developed Devin) focuses on how to write better code, ultimately producing runnable, reliable software that meets requirements. The Agent they developed is essentially an ‘Engineer’.
For a researcher, the thought process must be broad, and the output can be an understandable paper.
For a programmer, the results must be reliable, and the output must absolutely be runnable code.
This distinction leads to different strategies when implementing AI Agents.
Multi-Agent systems can think broadly like researchers, while Single-Agent systems can maintain focus and consistency like engineers.
However, from both articles, I would like to share a few insights on AI Agent development:
1. Increasing context and tools can lead to decreased performance of a single Agent
This may seem counterintuitive. Currently, large models support increasingly longer context lengths, even exceeding millions of tokens, and protocols like MCP encourage the use of tools. These are all signs of progress, but how can increasing context and tools lead to decreased performance?
To clarify, while AI development indeed provides longer contexts and better tool support, this is merely a capability; there is no need to push to the limits. For example, if Guan Yu can lift a maximum of 400 pounds, that is impressive, but his Green Dragon Crescent Blade cannot weigh 400 pounds; otherwise, wielding it would be strenuous and could lead to exhaustion. Conversely, an 80-pound Green Dragon Crescent Blade allows Guan Yu to use it more skillfully and effectively.
Similarly, if a large model is given too long a context, it will inevitably distract attention; the more tools added through prompts, the more likely the large model is to choose difficult options.
LangChain has conducted tests using different large models for tasks, selecting varying numbers of tools and different context lengths, and the results are roughly as shown in the following image.
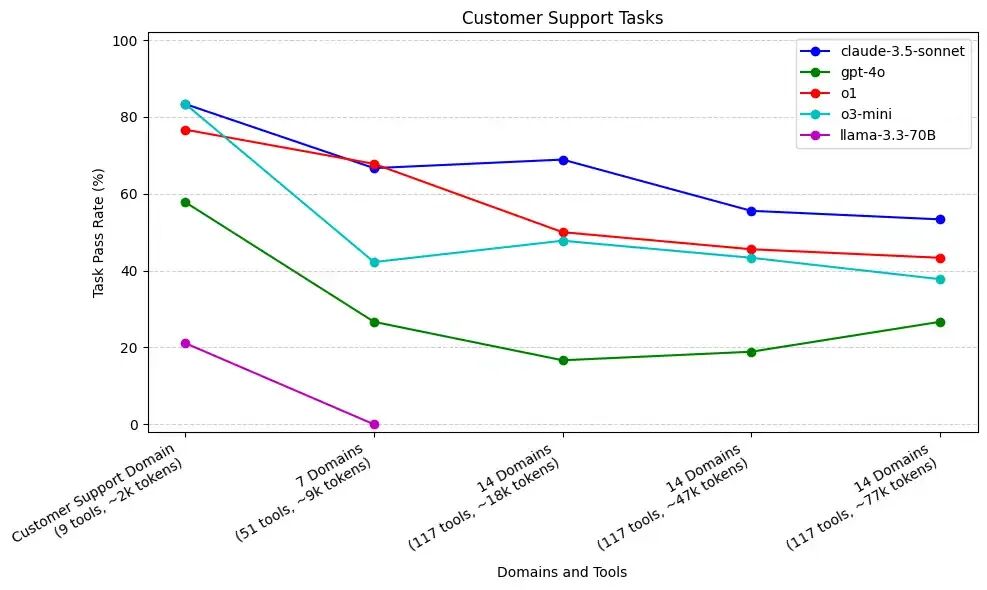
It is clear that while in some cases, more tools and longer contexts provide slight performance improvements, the overall trend is downward.
Therefore— when writing AI Agents, control the context length and the list of tools; longer is not always better.
2. Manage context well; delete what needs to be deleted and compress information when necessary
Based on the above conclusion, it is natural to understand that context length must be controlled; one should not use the large model’s capability limits as a guideline.
For AI Agents that need to run for extended periods, such as those writing code or playing games, it is absolutely essential not to cram all irrelevant information into the context; otherwise, it will crash after just a few rounds!
Thus, do not treat all historical information as context like in Chat; the prompts sent to the large model (which represent the context text) should be trimmed and prioritized as necessary. For example, in AI Coding’s Cursor, while it can access all code in the user’s codebase, it cannot possibly include the entire codebase in the prompt every time; it must select only relevant code content, which is more optimal in terms of both cost and performance.
However, some information may not be needed in a particular round but could be required in a future round. Deleting it would be a waste! Therefore, create a persistent storage library to store all information, and each time you interact with the large model, search this library for necessary content to add to the context.
If a single Agent can manage context well, it can still achieve excellent results; the power of AI Agents lies here.
3. Let different Agents play different roles
In Devin’s description, they only discussed how a coding AI Engineer maintains consistency. However, this engineer is merely a coding role. In actual engineering, we also need roles for writing tests and performing QA. We all understand that having programmers test their own code can easily lead to overlooked issues, as their thinking tends to assume they have made no mistakes.
Therefore, even if not conducting research, I believe that incorporating multiple Agents to assist in software development is better. At least one Agent can write the working code, while another can write the test code. Different roles will have different perspectives, making it easier to avoid singular thinking and allowing multiple Agents to complement each other.
In Conclusion
Nothing is absolute; whether one must use Multi-Agent systems or should never use them is not definitively correct. Debating these matters without considering specific problems and environments is meaningless.
In practice, one should follow the teachings of great individuals—

Choose the appropriate solution based on actual circumstances; practice is the only criterion for testing truth.