“Two Heads are Better Than One” (两个脑袋比一个好/双Agent更优) is an old saying in English. Researchers of the MAS-TTS framework have creatively applied this simple wisdom to LLMs, enabling multiple agents to collaborate like an expert think tank. Experimental data strongly demonstrates that in the face of complex problems, multi-agent systems achieve 60.0% performance, significantly outperforming single agents at 46.7%. Just as a problem that one person cannot solve can often find a breakthrough through discussion with another, a brilliant move that one chess player cannot see may emerge when two players collaborate.

A New Chapter in Agent Collaboration
While the capabilities of a single agent are impressive, they still have limitations when facing complex real-world tasks. For instance, when a company needs to decide whether to launch a new product, it requires evaluations from multiple departments such as marketing, finance, technology, and risk, rather than simply answering questions like “How’s the weather today?” Large language models have made significant progress in single-agent mode through Test-time Scaling (TTS), but how to effectively scale collaboration and reasoning capabilities in multi-agent systems (MAS) remains a pressing issue. Recently, researchers from Rutgers University, the University of Connecticut, and NVIDIA Research have proposed a novel adaptive multi-agent framework that enhances collaborative reasoning capabilities through model-level training and system-level coordination, providing a new approach for the development of agent products.

The Current State and Challenges of Multi-Agent Systems
Current multi-agent systems, while showing great promise in areas such as mathematical reasoning, software development, and scientific discovery, largely rely on the contextual learning capabilities of existing LLMs and guided reasoning techniques, lacking specialized training for collaboration optimization. In most existing frameworks, the collaboration methods between agents are often pre-defined, lacking flexibility and adaptability, making it difficult to dynamically adjust collaboration strategies based on the complexity of the problem and domain characteristics. Additionally, the computational and time costs of the collaborative reasoning process in multi-agent systems are significantly higher than those of single agents, making resource optimization a key challenge while ensuring performance.
Core Components of the MAS-TTS Framework
The MAS-TTS framework is built on the AgentVerse open-source multi-agent platform, creating a complete collaborative reasoning system through expansion and optimization. The framework mainly consists of three core components: data generation pipeline, model training module, and multi-agent collaboration system. The system architecture adopts a modular design, facilitating expansion and customization, with the main structure including: agentverse (core implementation of multi-agents), data (various task datasets), dataloader (data loader), and LLaMA-Factory (model training tool). This design allows researchers and engineers to easily add new tasks, models, and agent roles, achieving flexible functional expansion.
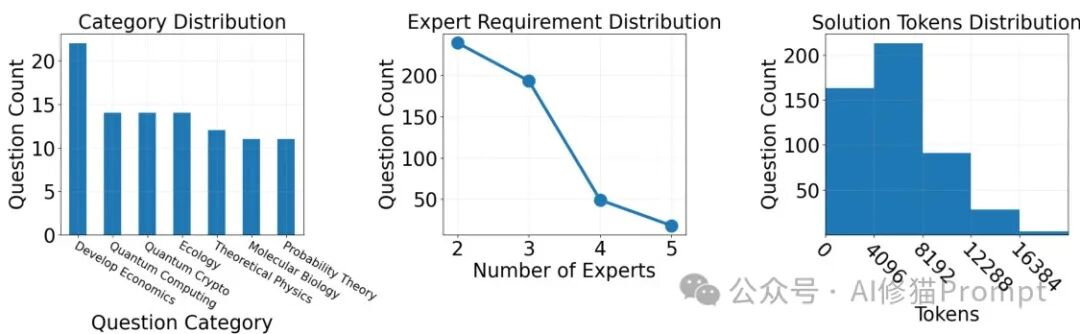
M500: Construction of a High-Quality Multi-Agent Collaborative Reasoning Dataset
Researchers have constructed a high-quality M500 dataset through a carefully designed automated pipeline, containing 500 detailed multi-agent collaborative reasoning trajectories. During the dataset construction process, researchers considered three key factors: difficulty, diversity, and interdisciplinarity, filtering out problems that require interdisciplinary knowledge to solve and that have answers exceeding 1024 tokens using the DeepSeek-R1 model. Collaborative reasoning trajectories were generated using the open-source multi-agent framework AgentVerse and the reasoning model DeepSeek-R1, involving multiple roles: expert recruiters, problem solvers, executors, and evaluators. These agents collaboratively solve problems through multiple rounds of discussion and generate detailed reasoning histories.

To ensure data quality, researchers filtered based on three criteria: 1) Consensus, meaning that problem solvers reach an agreement within the maximum allowed number of critical iterations; 2) Format compliance, ensuring that each agent’s reasoning is encapsulated within specific tags; 3) Correctness verification, retaining only trajectories with correct answers. Through this method, the final M500 dataset was formed, containing 500 interdisciplinary collaborative problems and their high-quality reasoning trajectories, providing a solid foundation for subsequent model training.
The dataset covers tasks from multiple fields, including AIME2024 (American Invitational Mathematics Examination), GPQA-Diamond (PhD-level scientific questions), MATH-500 (competition-level math problems), HumanEval, and MBPP-Sanitized (programming problems), etc.
M1-32B: A Large Language Model Optimized for Collaborative Reasoning
Inspired by research based on Simple-Scaling, researchers recognized that the long-chain reasoning (Chain of Thought, CoT) capabilities of LLMs can be developed through supervised fine-tuning (SFT) on detailed reasoning trajectories. They fine-tuned the Qwen2.5-32B-Instruct model using the M500 dataset, resulting in the M1-32B model optimized for multi-agent collaboration. During training, researchers ensured that all reasoning trajectories for the same problem were grouped in the same batch and arranged in the order of generation in the original multi-agent system. This approach helps the model learn collaborative reasoning in a coherent and logically sequential manner. Through this training strategy, the M1-32B model can effectively collaborate in multi-agent environments, providing long-chain reasoning and expanding reasoning capabilities from multiple expert perspectives.
Math L_SFT = E_((x,y) in M500) [ -1/|y| * sum_{t=1}^{|y|} log P_f(y_t|x,y_{<t}) ]CEO Agent: An Innovation in Adaptive Test-time Scaling
To address the application issues of test-time scaling (TTS) strategies in multi-agent systems, researchers proposed the introduction of a “CEO” agent, driven by the M1-32B model, to dynamically manage collaboration and resource allocation. The CEO agent evaluates the problem, the current state of solutions, feedback, and available resources, deciding whether to accept proposed solutions or require further improvements. Additionally, the CEO agent guides subsequent discussions, determining how many agents are involved and setting appropriate reasoning depths (i.e., token budgets) for each agent’s response. This design is inspired by the observation that leaderless teams in human society often lack efficiency and coherent direction. Through the CEO agent, multi-agent systems can dynamically adjust settings, more effectively scaling collaborative reasoning capabilities.
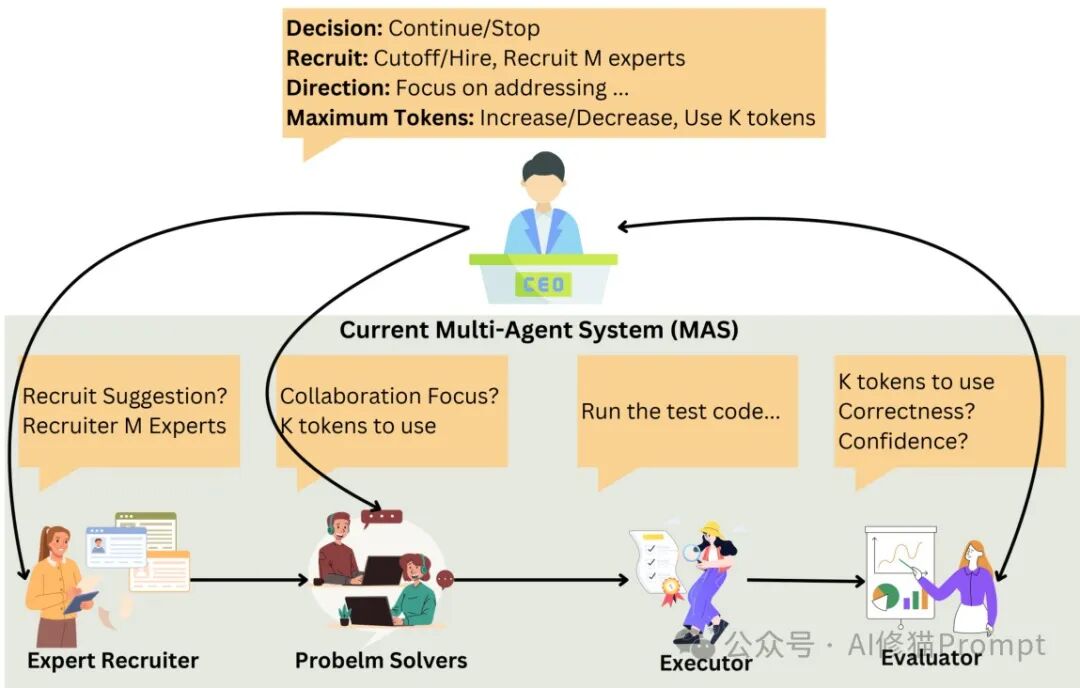
Enterprise Hypothesis Validation Multi-Agent Example
I wrote a multi-agent code for enterprise hypothesis validation based on the MAS-TTS framework, using DeepSeek-V3. Below are the actual running results. Although this system simplifies the complex architecture of MAS-TTS, it retains its core collaborative reasoning concept. The system includes a CEO agent and multiple domain experts (marketing, finance, technology, risk, etc.), collaboratively completing a comprehensive evaluation of business hypotheses. During the process, the CEO agent is responsible for task allocation and result integration, similar to the coordinating role in MAS-TTS, while each expert agent focuses on in-depth analysis in their respective fields, collectively constructing a more comprehensive and reliable evaluation result than a single agent. This structured collaboration approach validates the core idea of “two agents are better” and demonstrates how to apply the MAS-TTS collaborative framework to real business decision-making scenarios, providing a concise and practical implementation example for enterprise-level applications.


Swipe up and down to see more
Slide left and right to see more
Significant Performance Improvement
Researchers conducted a comprehensive evaluation of the system in three key areas: general understanding, mathematical reasoning, and programming. The results show that the integration of M1-32B with the CEO agent significantly outperforms baseline models. Performance improved by 12% on GPQA-Diamond, 41% on AIME2024, 11% on MATH-500, and 10% on MBPP-Sanitized, achieving comparable performance to state-of-the-art open-source and closed-source models (such as DeepSeek-R1 and o3-mini) on certain tasks. These results demonstrate that the method effectively enhances general Q&A, writing, mathematical reasoning, and programming capabilities in multi-agent systems.

“Aha Moments”: Emergent Behaviors in Multi-Agent Systems
Researchers observed that when using M1-32B, agents sometimes exhibit emergent behaviors that help validate and improve the collaborative process. For example, when a problem solver fails to identify errors in their solution, the CEO agent actively checks its validity, identifies errors, and proposes alternative correct solutions, prompting the problem solver to modify the original response accordingly. This collaborative interaction occurs when other agents are unaware of their mistakes, reflecting true collaborative intelligence. Such emergent behavior may stem from the CEO agent’s training on multi-agent collaborative reasoning trajectories, enabling it to actively validate and correct solutions based on learned collaboration patterns and insights gained from other agents’ reasoning.
Further Research: Optimizing Collaboration and Reasoning Strategies
By systematically adjusting the total number of iterations, critical iterations, total number of agents, and maximum token limits, researchers delved into how to scale collaboration and reasoning in multi-agent systems. Experiments showed that increasing interactions among Problem Solvers significantly improved performance, which could be achieved by raising the critical iteration limit or increasing the total number of Problem Solvers. However, involving too many Problem Solvers may reduce performance due to divergent discussions among agents. Increasing the maximum allowed token count for each agent effectively improved system performance, with optimal token limits varying by task, such as 16384 tokens for AIME2024 and 8192 tokens for GPQA.
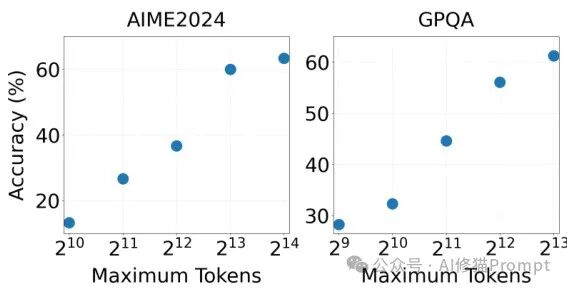
Comparison of Single-Agent and Multi-Agent Performance
Researchers further compared the performance differences of M1-32B in single-agent and multi-agent environments. The results showed that using M1-32B in multi-agent systems significantly improved performance compared to using it alone, for example, achieving 60.0% performance on AIME2024 in multi-agent systems, while single-agent performance was 46.7%. In contrast, using Qwen2.5 in multi-agent systems showed only slight improvements compared to using it alone, further proving the effectiveness of the proposed method in enhancing multi-agent system performance. This comparison highlights the advantages of the M1-32B model in collaborative environments and demonstrates that models designed specifically for collaboration can provide greater value in multi-agent systems.
How to Implement a Multi-Agent Collaboration Framework
As an engineer developing agent products, you can implement a similar multi-agent collaboration framework through the following steps. First, build or collect high-quality multi-agent collaboration data, ensuring that the data includes complete reasoning trajectories, diverse problem types, and expert roles. Second, fine-tune existing LLMs using this data to optimize their collaborative reasoning capabilities, paying attention to maintaining the original generation order and integrity of the data during training. Finally, design adaptive coordination mechanisms, such as the CEO agent, to dynamically adjust the number of agents, discussion depth, and resource allocation based on problem complexity, achieving more efficient collaborative reasoning.
Future Directions for Collaboration Optimization
This research proposes an adaptive test-time scaling method to enhance multi-agent collaborative reasoning capabilities through the construction of the M500 dataset, fine-tuning the M1-32B model, and designing the CEO agent. Experimental results indicate that this method significantly outperforms baseline models in tasks such as general understanding, mathematical reasoning, and programming, even achieving comparable performance to state-of-the-art models on certain tasks. These findings emphasize the importance of learning collaboration and adaptive coordination in scaling multi-agent reasoning, providing new directions for building more powerful and flexible AI systems.
The Future is Here, Let’s Walk Together!


<End of Article>结>
- Please contact this author for reprints; unauthorized scraping and reprinting will be prosecuted.
🎉Let’s create more beauty together! 🎉
If you find this article helpful
Thank you for your [like], [view]
<Your likes and views are visible only to me>
👉WeChat ID: xiumaoprompt
Please indicate your intention when adding!