Multi-Agent Workflow
Tip
The multi-agent workflow architecture collaborates with different specialized agents to handle user queries and generate a comprehensive research report.
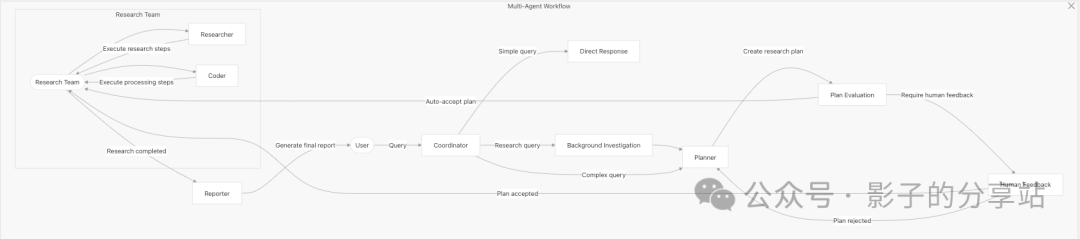
Agent Responsibilities and Capabilities
The multi-agent workflow of DeerFlow consists of five specialized agents, each with specific roles and responsibilities.
| Agent | Role | Primary Responsibilities |
| Coordinator | Entry | Handles greetings and small talk, classifies user requests, and routes research queries to the Planner. |
| Planner | Research Planning | Creates a structured research plan containing specific steps based on query requirements. |
| Researcher | Information Gathering | Executes research steps using web search and crawling tools. |
| Coder | Data Processing | Performs data analysis using Python code. |
| Reporter | Content Analysis | Creates a comprehensive report based on the collected information. |
Coordinator Agent
Classifies user requests into three categories:
- • Direct Handling: Greetings and small talk.
- • Polite Refusal: Inappropriate or harmful requests that the system will refuse to process.
- • Handing to Planner: Research questions and factual inquiries that will be further processed.
Planner Agent
Breaks down complex queries into manageable steps to create a detailed research plan.
- 1. Assess whether there is enough context to answer the query directly.
- 2. If context is insufficient, create a structured research plan with specific steps.
- 3. Classify steps as “Research” (web search) or Processing (computational tasks).
- 4. Limit the number of steps in the plan, with a maximum thinking step count (default is 3).
Researcher Agent
Executes research steps that require information gathering.
- 1. Use built-in tools such as
<span>web_search_tool</span>and<span>crawl_tool</span> - 2. Dynamically load tools when available.
- 3. Document sources and attribute information to ensure citation.
- 4. Structure and synthesize the collected information.
Coder Agent
Executes data processing involving Python code.
- 1. Analyze requirements and plan solutions.
- 2. Implement solutions using Python scripts.
- 3. Utilize available libraries such as pandas and numpy.
- 4. Document methods and visualize results.
Reporter Agent
Responsible for synthesizing all collected information into a complete final report.
- • Organize information in a clear structure and logically.
- • Highlight key findings and important insights.
- • Include relevant images from the research process.
- • Properly cite all sources.
- • Maintain the user’s preferred language.
Workflow Execution Process
Workflow Configuration
| Parameter | Description | Default |
| debug | Enable debug logging. | False |
| max_plan_iterations | Maximum number of plan iterations. | 1 |
| max_step_num | Maximum number of steps in the plan. | 3 |
| enable_background_investigation | Perform web search before planning. | True |
| mcp_settings | Configure dynamic tool loading. | None |
Mapping Prompts to Agents
Maps the prompts of agents to the actual code files that define their behavior.

Structured Planning and Step Execution
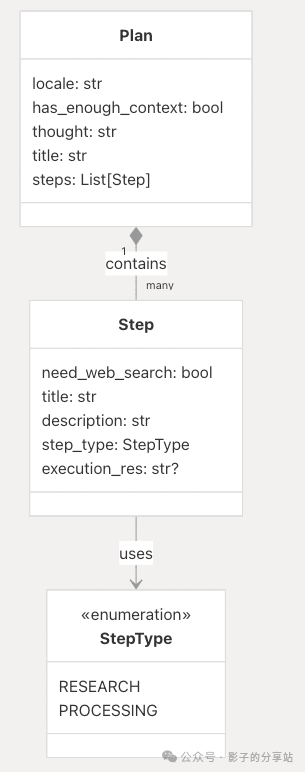
Step Types and Execution
Steps are divided into two types: Research and Processing.
StepType.RESEARCH
- • Requires web search
<span>need_web_search: true</span> - • Focuses on gathering information, statistics, and data points.
- • Executed by the Researcher Agent using web search and crawling tools.
StepType.PROCESSING
- • Does not require web search
<span>need_web_search: false</span> - • Involves computation, data analysis, and computational tasks.
- • Executed by the Coder Agent using Python for data processing.
Tool Integration
DeerFlow integrates various tools that agents can use to gather information and process data.
Built-in Tools
| Tool | Description | Used By |
| web_search_tool | Performs web searches to gather information. | Researcher |
| crawl_tool | Reads content from URLs. | Researcher |
Dynamic Tool Loading with MCP
Supports dynamic loading of additional tools via MCP.
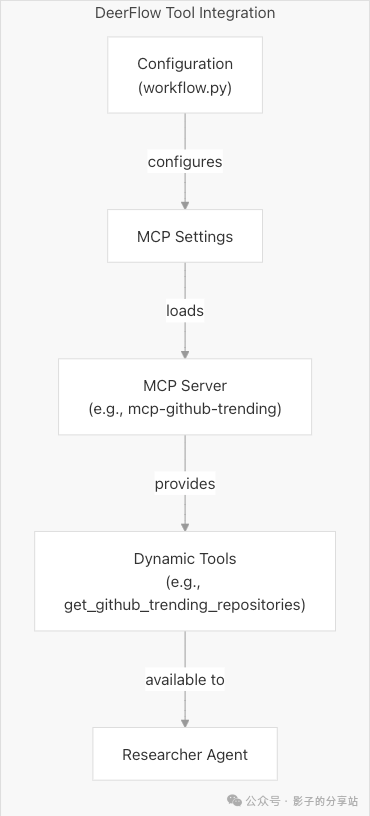
Here is an example of MCP settings for a GitHub trending repository.
"mcp_settings": {
"servers": {
"mcp-github-trending": {
"transport": "stdio",
"command": "uvx",
"args": ["mcp-github-trending"],
"enabled_tools": ["get_github_trending_repositories"],
"add_to_agents": ["researcher"]
}
}
}Data Flow
Tip
This section documents the flow of data from user input to the final research report, including messages, events, states during front-end and back-end interactions, and internal data transformations within each component.
Preview of Data Flow
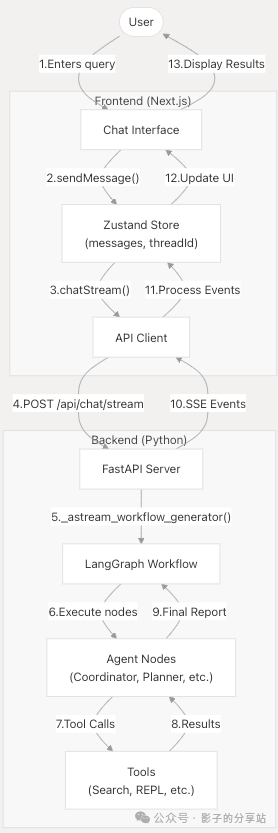
Front-end Data Flow
User Input as API Request
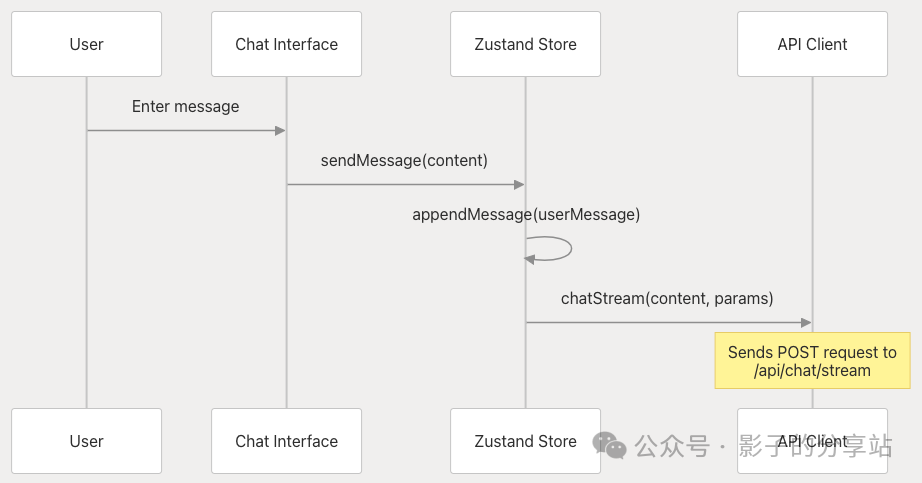
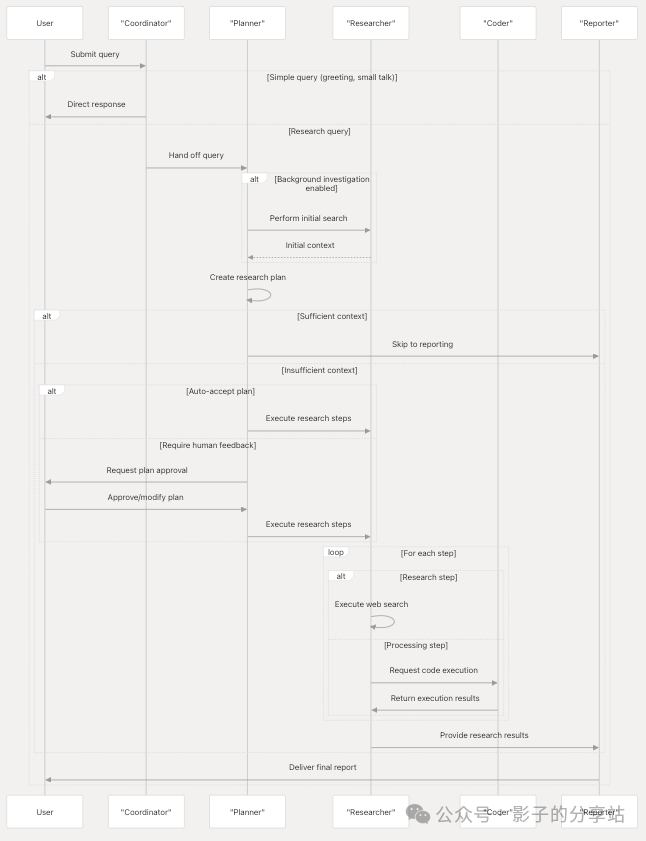
The processing flow of the sendMessage function (web/src/core/store/store.ts 76-154) is as follows:
- 1. Create a new user message, generate a unique ID, and add it to the Zustand state store.
- 2. Retrieve chat settings from the store using
<span>getChatStreamSettings()</span> - 3. Initiate an API call using the user message and configuration parameters, calling
<span>chatStream()</span> - 4. Set the front-end state to “responding” during the conversation.
The parameters of the chat stream include the following:
| Parameter | Description |
| thread_id | Unique identifier for the conversation. |
| auto_accepted_plan | Whether to automatically accept the research plan. |
| max_plan_iterations | Maximum number of iterations for the plan. |
| max_step_num | Maximum number of research steps. |
| enable_background_investigation | Whether to perform background web searches. |
| mcp_settings | MCP configuration. |
Event Handling and State Management
The front-end uses Zustand to manage application state, with key state components including:
| State | Description |
| messageIds | Array of message IDs in chronological order. |
| messages | Mapping of message objects indexed by ID. |
| researchIds | Array of research session IDs. |
| researchPlanIds | Mapping of research IDs to plan message IDs. |
| researchReportIds | Mapping of research IDs to report message IDs. |
| researchActivityIds | Mapping of research IDs to activity message IDs. |
| ongoingResearchId | Currently active research session. |
| openResearchId | Research currently being viewed by the user. |
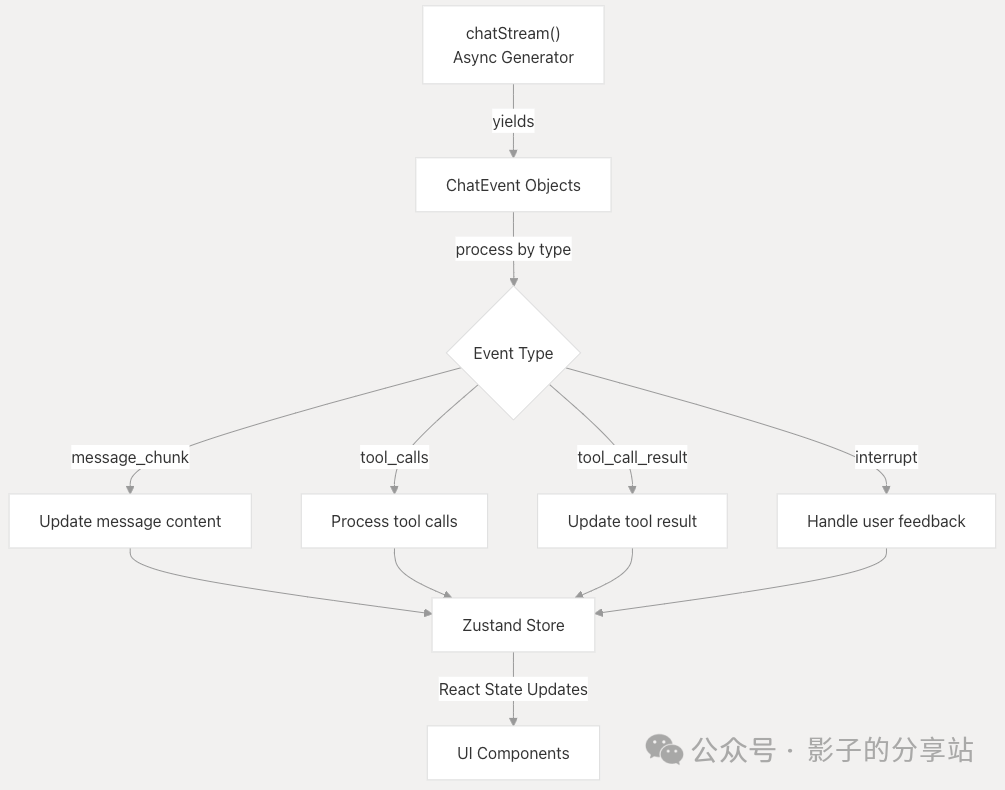
When the back-end receives events, they are processed and update the above states.
- • message_chunk: Updates message content.
- • tool_calls: Handles tool calls.
- • tool_call_result: Updates tool call results.
- • interrupt: Handles user feedback.
The following state update functions are used to manage state changes during chat and research processes, ensuring the front-end can correctly display conversation and research progress:
- • appendMessage: Adds a new message to the store.
- • updateMessage: Updates existing messages with new content.
- • updateMessages: Batch updates multiple messages.
- • setOngoingResearch: Tracks the current research session.
- • openResearch: Controls the research content displayed in the UI.
API Communication
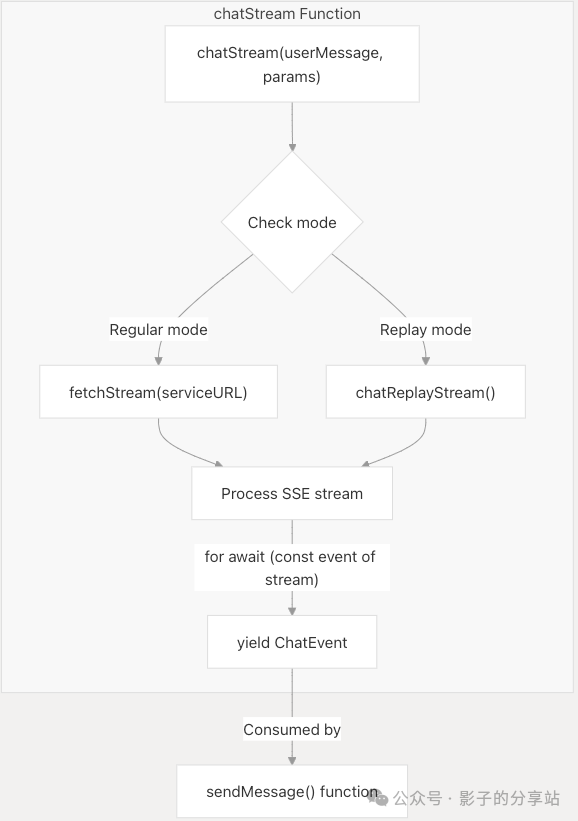
The front-end and back-end communicate via SSE for streaming responses, supporting two modes:
- • Regular mode: Sends actual requests to the back-end and receives real-time responses.
- • Replay mode: Uses pre-recorded responses for demonstration or testing.
Back-end Data Flow
Request Handling
When the back-end receives a chat request, it is processed through the <span>/api/chat/stream</span> endpoint.
- • Parses user input and generates a UUID.
- • Initializes streaming events.
- • Starts StreamResponse, using
<span>_astream_workflow_generator()</span>to process the request and generate streaming responses.
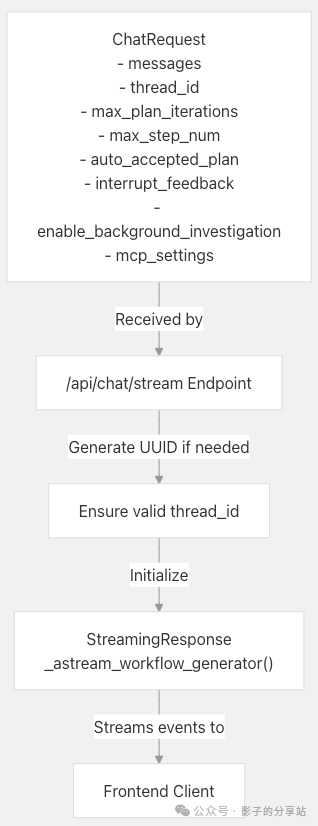
Workflow Event Generation
<span>_astream_workflow_generator()</span><span> is responsible for the following:</span>
- 1. Sets the initial state of the LangGraph workflow.
- 2. Streams agent interactions and results back to the client.
- 3. Converts LangGraph events to SSE (Server-Sent Events).

LangGraph State Flow
Manages state transitions between agent nodes, with each node processing the current state and returning an object used to update the state and guide the workflow to the next node.
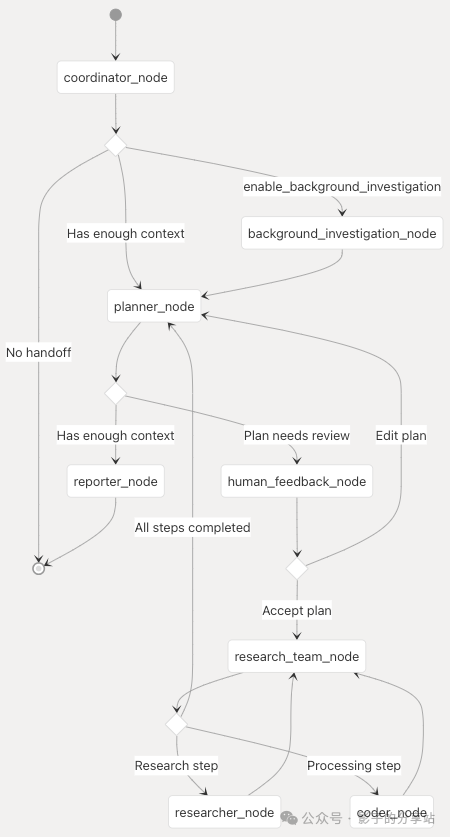
The LangGraph state object contains:
| State Key | Description |
| messages | History of conversation messages. |
| plan_iterations | Number of iterations for the plan. |
| current_plan | The current research plan. |
| observations | Results collected from research steps. |
| final_report | The final generated report. |
| locale | The language environment of the conversation. |
| auto_accepted_plan | Whether to automatically accept the plan. |
| enable_background_investigation | Whether to perform background searches. |
Data Structures
Message Structure
The Message is the primary data structure of the DeerFlow system, flowing between the front-end and back-end.
| Field | Type | Description |
| id | string | Unique identifier for the message. |
| threadId | string | Conversation thread ID. |
| role | string | “user” or “assistant”. |
| agent | string | Name of the agent. |
| content | string | Text content of the message. |
| contentChunks | string[] | Chunks of streamed content. |
| isStreaming | boolean | Whether the message is still being generated. |
| toolCalls | object[] | Tools called by the message. |
| interruptFeedback | string | Terminal information from user feedback. |
ChatEvent Structure
The events streamed from the back-end to the front-end have the following structure:
{
"event": "<event_type>",
"data": "<JSON data>"
}Where event_type can be:
- • message_chunk: Text content from the agent.
- • tool_calls: Agent requests to use tools.
- • tool_call_chunks: Partial content of tool calls.
- • tool_call_result: Results of tool execution.
- • interrupt: Requests user feedback.
ChatRequest Structure
The structure of requests passed from the front-end to the back-end is as follows:
{
"messages": [{ "role": "user", "content": "string" }],
"thread_id": "string",
"auto_accepted_plan": true,
"max_plan_iterations": 3,
"max_step_num": 5,
"interrupt_feedback": "string",
"enable_background_investigation": true,
"mcp_settings": {
"servers": {
"server_name": {
"transport": "string",
"command": "string",
"args": ["string"],
"url": "string",
"env": { "key": "value" },
"enabled_tools": ["string"],
"add_to_agents": ["string"]
}
}
}
}References
https://deepwiki.com/bytedance/deer-flow/2.1-multi-agent-workflow
https://deepwiki.com/bytedance/deer-flow/2.2-data-flow#data-flow
Postscript
A WeChat friend I met a long time ago saw me sharing content about deer-flow and greeted me, saying it was developed by their team. The world is surprisingly small.

Additionally, for friends from the 26th and 27th cohorts looking for internships, if you have a solid background and skills in AI engineering, feel free to DM me your resume to avoid being filtered out directly. I know several teams are still hiring, and I can help refer you to teams at Meituan, Alibaba, etc.
