Recently, there have been two interesting articles about Multi-agent systems that are worth checking out.
- https://www.anthropic.com/engineering/built-multi-agent-research-system
- https://cognition.ai/blog/dont-build-multi-agents#applying-the-principles
On June 13, 2026, Anthropic released “How We Built Our Multi-Agent Research System,” sharing the engineering challenges encountered in building multi-agent systems and the lessons learned.
Claude now possesses research capabilities, enabling it to perform complex tasks through web searches, Google Workspace, and any integrated applications.
- https://www.anthropic.com/news/research
A multi-agent system consists of multiple agents working collaboratively. Our research functionality includes an agent that plans a research process based on user queries and then utilizes tools to create parallel agents to search for information simultaneously.Multi-agent systems introduce new challenges in agent coordination, evaluation, and reliability.
Benefits of a Multi-Agent System
Research work involves open-ended questions, making it difficult to predict the necessary steps in advance. Due to the inherently dynamic and path-dependent nature of this process, you cannot hard-code a fixed path for exploring complex topics. When people conduct research, they often continuously adjust their methods based on new discoveries and track leads that emerge during the investigation.
This unpredictability makes AI agents particularly suitable for research tasks.Research requires the ability to flexibly pivot or explore indirect connections during the investigation. Models must operate autonomously at multiple stages, determining subsequent research directions based on intermediate results.A linear, one-time process cannot handle these tasks.
The essence of searching is compression: extracting profound insights from vast amounts of data. Sub-agents assist in compression by operating in parallel within their respective context windows, synchronously exploring different aspects of the problem before distilling the most important markers for the lead research agent. Each sub-agent also implements focus separation—using different tools, prompts, and exploration paths—which reduces path dependency and allows for a comprehensive and independent investigation.
Once intelligence reaches a certain threshold, multi-agent systems become a key avenue for enhancing performance. For example, despite individual humans becoming smarter over the past hundred thousand years, the collective intelligence and collaborative capabilities of human society have exponentially increased in the information age. Even agents with general intelligence face limitations when acting alone; however, a group of agents can accomplish far more tasks.
Internal evaluations indicate that multi-agent research systems excel particularly in breadth-first queries, which involve simultaneously exploring multiple independent directions. We found that in our internal research evaluations, a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 as sub-agents outperformed the single-agent Claude Opus 4 by 90.2%.
Multi-agent systems can operate effectively primarily because they help spend enough tokens to solve the problem. The reason for the higher efficiency of multi-agent systems compared to single-agent systems can be explained by the consumption of sufficient tokens, along with other explainable factors such as tool invocation frequency and model selection.
The multi-agent architecture can effectively scale token usage to handle tasks beyond the capabilities of a single agent. This also leads to drawbacks: in practical applications, these architectures quickly consume tokens. In our data, the tokens used by agents are typically about four times more than those used in chat interactions, while multi-agent systems use about fifteen times more tokens than chat.
To ensure economic viability, multi-agent systems need to tackle tasks that are valuable enough to cover the increased costs associated with performance improvements. Additionally, some fields that require all agents to share the same context or involve numerous dependencies between agents are currently not suitable for multi-agent systems.
Architecture Overview for Research
Our research system employs a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process and delegates tasks to parallel operating specialized sub-agents.
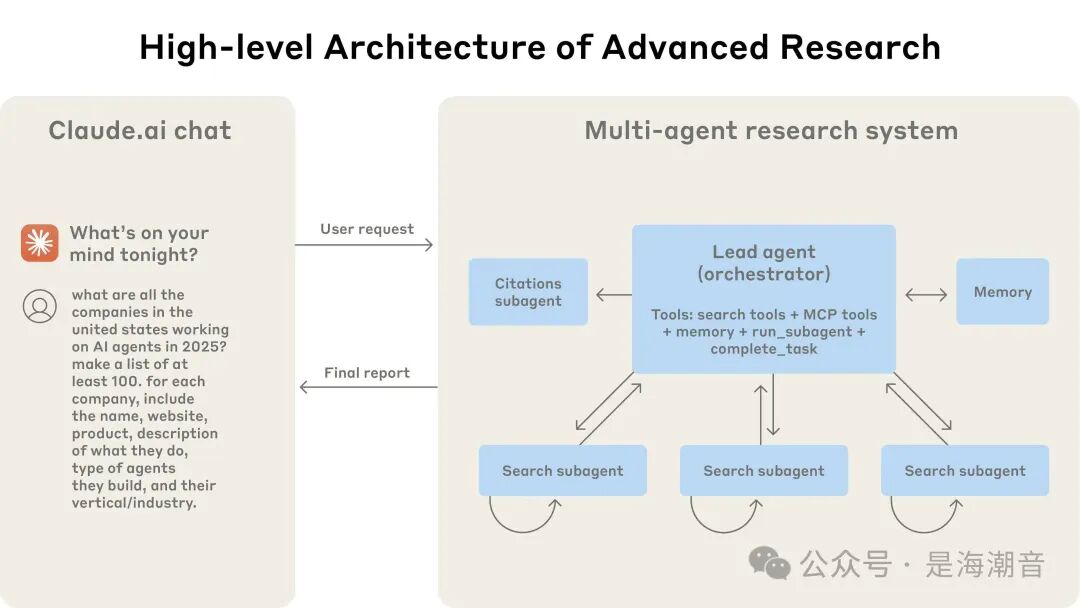
When a user submits a query, the lead agent analyzes it, formulates a strategy, and generates sub-agents to explore different aspects simultaneously. As shown in the figure above, sub-agents collect information by repeatedly using search tools, acting as intelligent filters, and then return a list of companies to the lead agent to compile the final answer.
Traditional RAG employs static retrieval. That is, they retrieve a set of data blocks most similar to the input query and use these blocks to generate responses. In contrast, our architecture employs multi-step searches, dynamically seeking relevant information, adapting to new discoveries, and analyzing results to form high-quality answers.
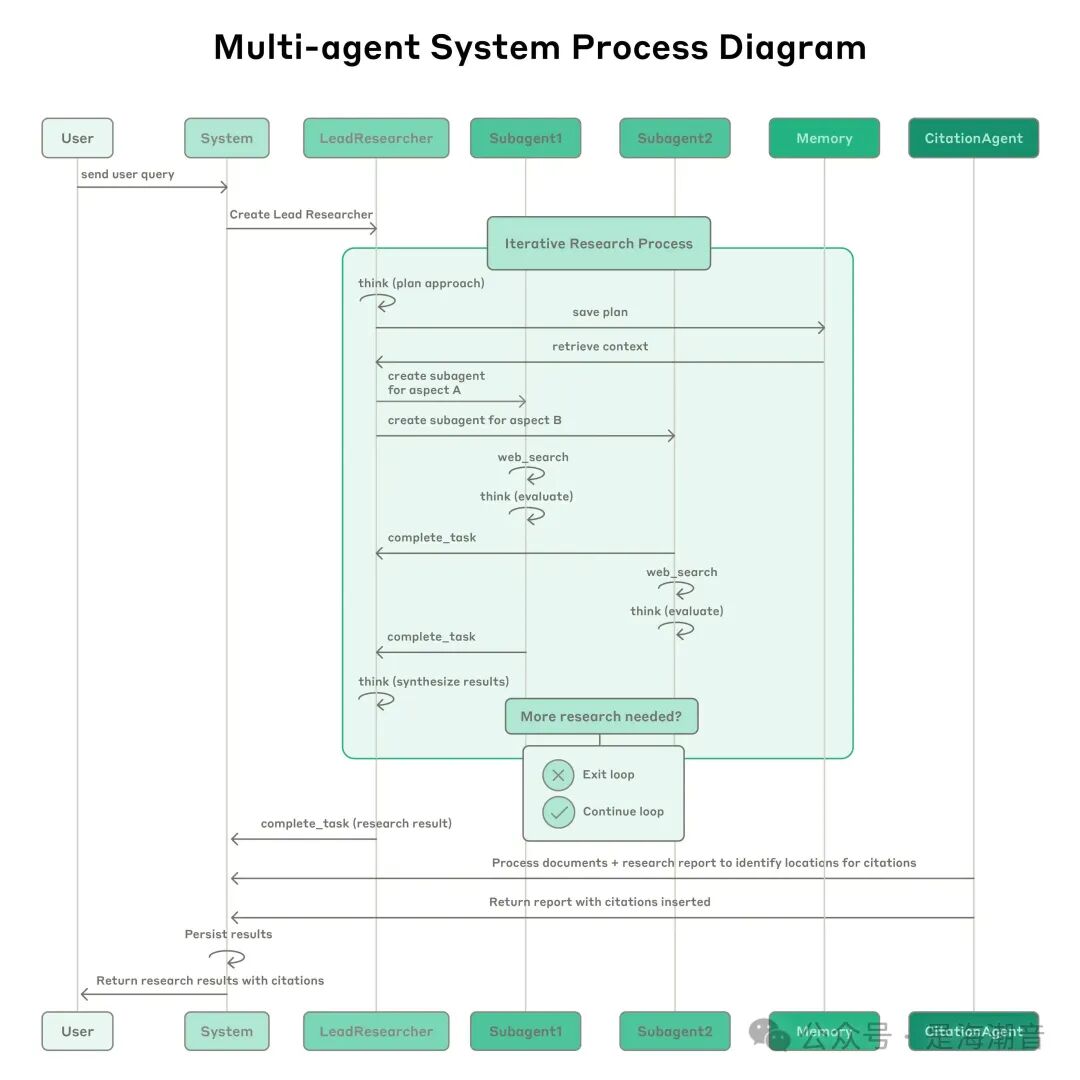
Prompt Engineering and Evaluations for Research Agents
Multi-agent systems differ from single-agent systems in key ways, including the rapid increase in coordination complexity. Early agents made some mistakes, such as generating 50 sub-agents for simple queries, endlessly searching for non-existent information sources on the web, and interfering with each other through excessive updates.
Here are some principles we summarized for guiding agents:
-
Think like your agents. To iterate on prompts, you must understand their effects. To help us do this, we use a console, employing the same prompts and tools as our system to build simulations and observe the agent’s workflow step by step. This immediately reveals some failure modes: agents continue running even when sufficient results have been obtained, use overly verbose search queries, or select the wrong tools. Effective prompts rely on establishing an accurate mental model of the agents, making the most impactful changes clear.
-
Teach the orchestrator how to assign tasks. In our system, the lead agent breaks down queries into subtasks and describes these tasks to the sub-agents. Each sub-agent needs a goal, an output format, guidance on which tools and information sources to use, and clear task boundaries. Without detailed task descriptions, agents may duplicate work, overlook details, or fail to find necessary information. Initially, we allowed the lead agent to give simple, brief instructions like “research the semiconductor shortage issue,” but we found these instructions often too vague, leading sub-agents to misunderstand tasks or conduct identical searches as other agents. For example, one sub-agent researched the 2021 automotive chip crisis while two others repeated work investigating the current supply chain in 2025 without effective division of labor.
-
Adjust input effort based on query complexity. Agents struggle to judge the effort required for different tasks, so we embedded adjustment rules in the prompts. Simple fact-finding requires 1 agent to make 3 to 10 tool calls, direct comparisons may need 2 to 4 sub-agents, each making 10 to 15 calls, while complex research may require more than 10 clearly defined sub-agents. These clear guidelines help the lead agent allocate resources efficiently, avoiding over-investment in simple queries, a common failure mode in our early versions.
-
The design and selection of tools are crucial. The interaction interface between agents and tools, as well as the human-computer interaction interface, are equally important. Using the right tools is more efficient and often absolutely necessary. For example, if an agent needs to search for information that only exists in Slack, it is doomed to fail from the start. For MCP servers that enable models to use external tools, this issue is more complex, as agents may encounter tools they have never seen before, and the quality of tool descriptions can vary widely. We established clear heuristic methods for agents: for instance, first check all available tools, match tool usage with user intent, conduct extensive external exploration via the web, or prioritize specialized tools over general ones. Poor tool descriptions can lead agents completely off track, so each tool needs a clear purpose and description.
-
Enable agents to self-improve. We found that the Claude 4 model can be an excellent prompt engineer. When given a prompt and a failure mode, it can diagnose the reasons for agent failures and suggest improvements. We even created a tool-testing agent—when it encounters a defective MCP tool, it attempts to use it and then rewrites the tool description to avoid failure. By testing the tool dozens of times, this agent discovered key nuances and vulnerabilities. This process of improving tool usability reduced the time for future agents using new descriptions to complete tasks by 40%, as they could avoid most errors.
-
Start broad, then narrow down. Search strategies should mimic the research methods of professionals: explore broadly first, then delve into specific details. Agents often default to using overly long, specific queries, resulting in very few returned results. To overcome this tendency, we guide agents to start with short, broad queries, assess available information, and then gradually narrow their focus.
-
Guide the thinking process. Expanding the thinking mode allows Claude to output more tokens in a visible thought process, serving as a controllable draft area. The lead agent uses thinking to plan its approach, assess which tools are suitable for the task, determine the complexity of the query and the number of sub-agents, and clarify each sub-agent’s role. Our tests show that expanded thinking improves instruction-following ability, reasoning capability, and efficiency. Sub-agents also engage in planning and then use interleaved thinking to evaluate quality, identify gaps, and refine their next queries after obtaining tool results. This makes sub-agents more efficient in adapting to any task.
-
Parallel tool invocation changes speed and performance. Complex research tasks naturally involve exploring multiple information sources. Our early agents executed sequential searches, which were extremely slow. To improve speed, we introduced two forms of parallelization: (1) the lead agent initiates 3-5 sub-agents in parallel rather than serially; (2) sub-agents use 3 or more tools in parallel. For complex queries, these changes reduced research time by up to 90%, enabling the “research” function to accomplish more work in minutes rather than hours while covering more information than other systems.
Effective Evaluation of Agents
-
Start evaluating immediately with small samples. In the early stages of agent development, due to the abundance of readily available results, changes often have a significant impact. A slight adjustment to a prompt can increase the success rate from 30% to 80%. Given the dramatic effects, only a few test cases can reveal changes. We started with about 20 queries that represent actual usage patterns. Regularly testing these queries allows us to clearly see the impact of changes. We often hear that AI development teams delay creating evaluations because they believe only large-scale evaluations with hundreds of test cases are useful. However, it is better to conduct small-scale tests with a few examples immediately rather than wait until a more comprehensive evaluation can be constructed.
-
LLM-as-judge evaluation scales when done well. Research outputs are difficult to evaluate programmatically because they are free-form text with rarely a single correct answer. LLMs are well-suited for scoring outputs. We used an LLM judge to evaluate each output based on criteria in a title: factual accuracy (does the statement match the source?), citation accuracy (does the cited source match the statement?), completeness (does it cover all required aspects?), source quality (does it use primary sources rather than lower-quality secondary sources?), and tool efficiency (does it use the correct tools a reasonable number of times?). We tried multiple judges to evaluate each component but found that a single LLM call, with a prompt output score ranging from 0.0-1.0 and a pass-fail grade, was the most consistent and aligned with human judgment. This method is particularly effective when eval test cases have clear answers, allowing us to use LLM judgment to simply check if the answer is correct (i.e., does it accurately list the top 3 pharmaceutical companies by R&D budget?). Using LLM as a judge enables us to scale evaluations of hundreds of outputs.
-
Human evaluations can uncover omissions in automated assessments. Testers can identify extreme cases that automated evaluations miss. These include hallucinatory responses to uncommon queries, system failures, or subtle biases in source selection. In our case, human testers noted that early agents consistently chose SEO-optimized content farms over authoritative sources like academic PDFs or personal blogs that ranked lower. Incorporating source quality heuristics into prompts helped address this issue. Even in the era of automated evaluations, human testing remains crucial.
Production Reliability and Engineering Challenges
-
Agents are stateful, and errors can accumulate. Agents can run for extended periods, maintaining state across multiple tool calls. This means we need to execute code persistently and handle errors during the process. Without effective mitigation measures, minor system failures can be catastrophic for agents. When errors occur, we cannot simply restart from scratch: restarting is costly and can frustrate users. Instead, we built systems capable of recovering from the point where the error occurred. We also leverage the intelligence of the model to gracefully handle issues: for example, informing the agent when a tool fails and allowing it to adapt, which has proven surprisingly effective. We combine the adaptability of AI agents built on Claude with deterministic safeguards like retry logic and regular checkpoints.
-
Debugging benefits from new methods. Agents make dynamic decisions, and even with the same prompts, there is uncertainty between runs. This makes debugging more challenging. For instance, users may report that an agent “cannot find obvious information,” but we cannot pinpoint the cause. Did the agent use a poor search query? Select a suboptimal information source? Or did a tool fail? After adding comprehensive production tracking, we could diagnose the reasons for agent failures and systematically address issues. In addition to standard observability, we monitor agents’ decision patterns and interaction structures while not monitoring the content of individual conversations to protect user privacy. This high-level observability helps us diagnose root causes, discover unexpected behaviors, and fix common failures.
-
Deployment requires careful coordination. Agent systems are highly stateful networks composed of prompts, tools, and execution logic that run almost continuously. This means that whenever we deploy updates, agents may be at any stage of their execution process. Therefore, we need to prevent well-intentioned code changes from disrupting existing agents. We cannot update every agent to a new version simultaneously. Instead, we use rainbow deployments, gradually shifting traffic from the old version to the new version while both versions run concurrently to avoid disrupting running agents.
-
Synchronization can create bottlenecks. Currently, our lead agent executes sub-agents synchronously, waiting for each group of sub-agents to complete their tasks before proceeding to the next step. This simplifies coordination but creates bottlenecks in the information flow between agents. For example, the lead agent cannot guide sub-agents, sub-agents cannot coordinate with each other, and the entire system may be blocked while waiting for a single sub-agent to complete a search. Asynchronous execution would enable more parallelism: agents could work simultaneously and create new sub-agents as needed. However, this asynchronicity introduces challenges in result coordination, state consistency, and error propagation between sub-agents. As models become capable of handling longer and more complex research tasks, we expect performance improvements to outweigh the complexities introduced.