
The second chapter provides an overview of the information hierarchy in Multi-Agent Systems (MAS) and the main threats corresponding to each level, along with a brief analysis of the threat propagation paths. Compared to single large model inference applications and traditional non-intelligent applications, the transmission of information between multi-agent systems, the iterative negotiation of risks, and the fuzzy and generalized expression of instructions centered around “intent” are the biggest differences in security risk models between multi-agent systems and traditional applications, as well as the key points for consideration and defense.
Chapter Two: Overview of Security Risks in Multi-Agent AI Application Environments
Compared to traditional AI inference applications, the multi-agent AI application environment combined with large models is more complex, with extensive information and tool connections, involving user interactions, internal module collaboration within agents, communication between agents, and integration with external services. This chapter aims to systematically present a layered and interconnected security threat analysis framework for multi-agent systems based on the concept map of “Main Risk Points in Multi-Agent Intelligent Application Environments,” providing an overview and classification of the security threats present at these key interaction points and modules, and in-depth analysis of the risk propagation paths, offering a unified view for the detailed analysis in subsequent chapters.
Figure 2.1: Main Risk Points in Multi-Agent Intelligent Application Environments
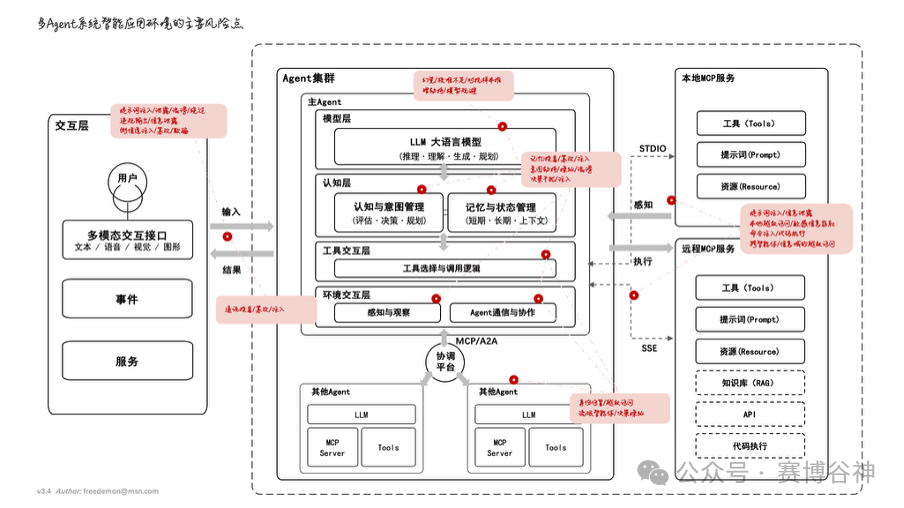
2.1 Layered Overview of Security Threats in Multi-Agent AI Application Environments
The security threats faced by multi-agent AI systems are multi-layered and multi-dimensional. Due to the abstract, multi-dimensional, and uncertain nature of information expression in large language models, the complexity of risk propagation when information flows interact with complex agent systems far exceeds that of a single AI model. Based on the concept map provided in the appendix, we can divide the entire multi-agent application environment into the following key interaction and processing levels, identifying the risk points and their possible propagation paths:
2.1.1 Interaction Layer Risks:
Main Function: Users provide input to the AI agent system through multi-modal interaction interfaces (text, voice, visual, graphics).
Key Risks: At this level, attackers primarily exploit techniques such as prompt injection, information leakage, bypassing, constructing non-compliant output, side-channel injection, and tampering/deception to directly affect the interaction between users and the agent system. These attacks may occur during the input processing phase, attempting to alter the agent’s intent or steal sensitive information. For a detailed analysis of these attacks, please refer to Chapter Three: Inherent Security Threats to AI Brains (Core of LLM) in 3.2 Prompt Injection Attacks, 3.6 Privacy Threats.
2.1.2 Agent or Agent Cluster Risks:
Main Function: The agent cluster is the core processing unit of the AI agent system, including the main agent and its model layer (LLM, responsible for reasoning, understanding, generating, and planning) and cognition layer (responsible for cognition and intent management, memory and state management). Additionally, it includes the tool interaction layer (tool selection and invocation logic) and environment interaction layer (perception and observation, agent communication and collaboration).
Key Risks::
-
Model Layer: Faces risks such as hallucination, misalignment, adversarial examples, and model evasion, directly affecting the output quality and reliability of the LLM. For a detailed analysis of these inherent threats, please refer to Chapter Three: Inherent Security Threats to AI Brains (Core of LLM) in 3.1 Jailbreak Attacks, 3.3 Hallucination Risks, 3.4 Alignment Deviation Issues.
-
Cognition Layer:
-
Memory and State Management: Faces risks of memory poisoning, tampering/injection, which may lead to intent hijacking, deception/misleading, and decision interference/injection. For a detailed analysis of memory module threats, please refer to Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.2 Memory Module Threats and Chapter Five: Threats to External Entity Interactions in 5.1 Agent-Memory Interaction Threats.
-
Cognition and Intent Management: Receives output from the LLM and evaluates, decides, and plans; its core logic may be maliciously exploited, leading to manipulated intent, prompting the agent to make unexpected decisions.
-
Tool Interaction Layer: The main risks arise from improper tool selection and invocation logic, which may lead to agents misusing or abusing tools, executing high-risk operations. For a detailed analysis of tool usage risks, please refer to Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.4 Action Module Threats.
-
Environment Interaction Layer:
-
Perception and Observation: Faces risks of communication poisoning, tampering/injection, which may lead to agents receiving false or manipulated information from the environment. For a detailed analysis of perception module threats, please refer to Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.1 Perception Module Threats.
-
Agent Communication and Collaboration: In a multi-agent system, communication between agents may face risks of identity spoofing/privilege escalation and rogue agents/decision manipulation, threatening the integrity and reliability of collaboration. For a detailed analysis of inter-agent interaction threats, please refer to Chapter Five: Threats to External Entity Interactions in 5.3 Agent-Agent Interaction Threats.
2.1.3 MCP and External Service Risks:
Main Function: MCP services include local MCP services and remote MCP services. They provide access to tools, prompts, and resources through STDIO (Standard I/O) and SSE (Server-Sent Events) protocols, as well as optional knowledge bases (RAG), APIs, and code execution functionalities.
Key Risks::
-
Local MCP Services: MCP supports local MCP services with stdio as the transport layer, primarily facing risks of prompt injection, information leakage, local privilege escalation/sensitive information theft, command injection/code execution, etc. These risks typically occur in the local deployment environment of MCP services. For a detailed analysis of MCP protocol and tool security risks, please refer to Chapter Six: The Position, Role, and Related Attacks of the Model Context Protocol (MCP) in Multi-Agent Systems in 6.2 Security Threats at the MCP Protocol Level, 6.3 Security Risks of Tools and Resources Carried by the MCP Protocol.
-
Network MCP Services: MCP supports network MCO services with http/SSE protocols as the transport layer, facing more complex network attack risks in addition to those similar to local MCP services, such as cross-agent/information privilege escalation, identity spoofing/privilege escalation, and rogue agents/decision manipulation, which are particularly prominent in multi-agent communication. For a detailed analysis of remote MCP service risks, please refer to Chapter Six: The Position, Role, and Related Attacks of the Model Context Protocol (MCP) in Multi-Agent Systems in 6.4 Security Risks at the MCP Transport Layer.
2.2 Risk Propagation Path Analysis
In the multi-agent AI application environment, security risks do not exist in isolation but interact through complex, dynamic propagation paths, threatening the overall security, reliability, and compliance of the system. Understanding these propagation paths is key to identifying deep-seated vulnerabilities and designing effective defense strategies.
-
From Interaction Layer to Agent Cluster: External inputs (such as malicious prompt injections) can directly attack the core of the LLM or affect the perception module, propagating to the cognition layer and tool interaction layer.
-
Propagation within Agent Internal Modules: Issues with LLM output (such as hallucinations, misalignment) will propagate to the cognition layer, affecting intent management, memory, and planning, ultimately leading to incorrect tool selection or actions.
-
From Agent Cluster to MCP Services: Instructions issued by agents (such as tool invocation logic) will be transmitted to local or remote MCP services via the MCP protocol. If these services have vulnerabilities, they may be exploited for attacks (such as command injection).
-
MCP Services to Agent Cluster: Contaminated prompts or resources provided by MCP services will be returned to the agent cluster, further affecting LLM reasoning, memory, and planning.
-
Communication Between Agents/With Other Agents: Communication between agents or with other agents, if subjected to poisoning or identity spoofing, may lead to the spread of false information within the multi-agent system or manipulation of other agents by rogue agents.
Figure 2.2: Relationship Diagram of Intelligent Components and Risks in Multi-Agent Systems
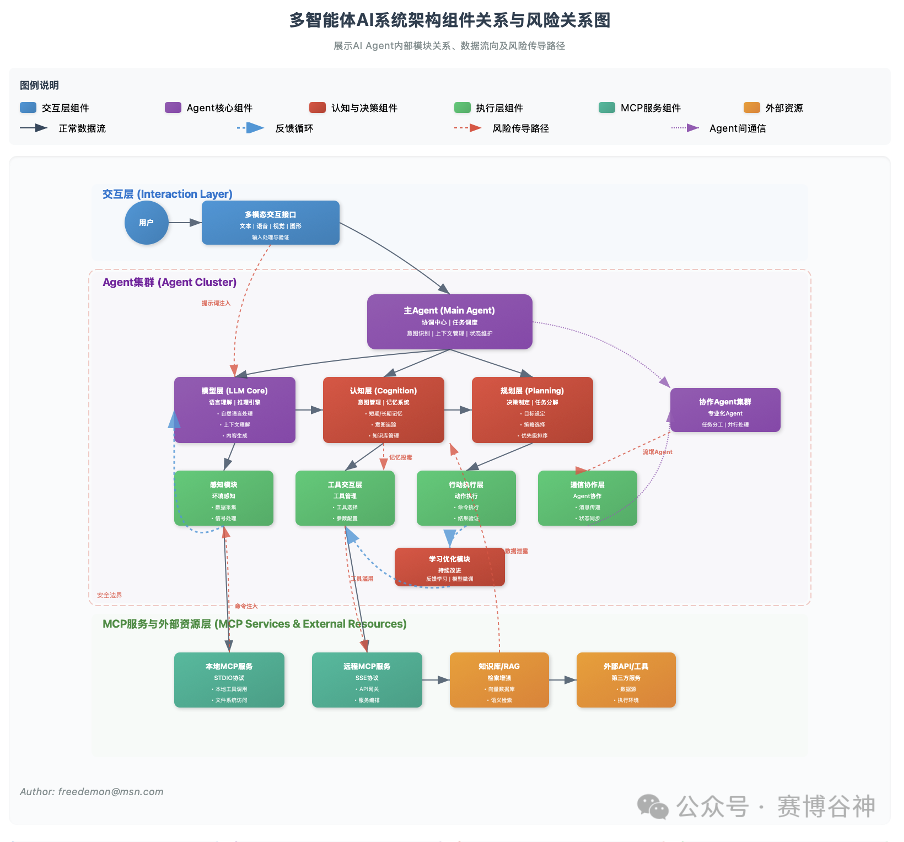
From the analysis of threat paths and propagation relationships, we can see that the risks in the multi-agent AI application environment are highly interconnected and dynamically changing. An attack on any link may impact the overall security, reliability, and compliance of the system along complex propagation paths.
2.3 Risk Classification Table by Module
The following table summarizes the security threats in the multi-agent AI application environment based on the above concept map and classifies them by module.
|
Module (Module) |
Risk Type (Risk Type) |
Typical Attack Method (Typical Attack Method) |
Risk Association and Propagation Path |
|
Interaction Layer (Interaction Layer) |
Prompt Injection Constructing Non-Compliant Output |
Malicious prompt injection, information leakage, bypassing security defenses, side-channel injection, tampering/deception |
User Input → LLM Core (Chapter Three: Inherent Security Threats to AI Brains (Core of LLM) in 3.2 Prompt Injection Attacks, 3.6 Privacy Threats). |
|
Agent Cluster (Agent Cluster) – Model Layer |
Hallucination Misalignment Adversarial Examples Model Evasion |
Misalignment, adversarial examples, model evasion |
Internal Issues of LLM → Cognition Layer, Tool Interaction Layer (Chapter Three: Inherent Security Threats to AI Brains (Core of LLM) in 3.1 Jailbreak Attacks, 3.3 Hallucination Risks, 3.4 Alignment Deviation Issues). |
|
Agent Cluster (Agent Cluster) – Cognition Layer |
Memory Poisoning Intent Hijacking Decision Interference/Injection |
Tampering/injecting memory, deception Misleading, manipulating cognition and intent management logic |
Affecting memory and state management, thereby affecting LLM core reasoning and planning (Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.2 Memory Module Threats, Chapter Five: Threats to External Entity Interactions in 5.1 Agent-Memory Interaction Threats). |
|
Agent Cluster (Agent Cluster) – Tool Interaction Layer |
Tool Misuse Privilege Escalation |
Improper tool selection and invocation logic |
Affecting tool selection and invocation logic, thereby affecting MCP service calls and environment interactions (Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.4 Action Module Threats). |
|
Agent Cluster (Agent Cluster) – Environment Interaction Layer |
Communication Poisoning Identity Spoofing/Privilege Escalation Rogue Agent Decision Manipulation |
Tampering/injecting perception and observation data, deceiving agent communication, forging agent identities |
Affecting perception and observation, thereby affecting the cognition layer and agent communication (Chapter Four: Inherent Security Threats to Non-Brain Modules in 4.1 Perception Module Threats, Chapter Five: Threats to External Entity Interactions in 5.3 Agent-Agent Interaction Threats). |
|
Local MCP Services (Local MCP Services) |
Prompt Injection/Info Leakage Command Injection/Code Execution |
Malicious prompt injection, local privilege escalation/sensitive information theft, malicious command injection |
Affecting prompts and resources provided by local MCP services, directly executing high-risk operations (Chapter Six: The Position, Role, and Related Attacks of the Model Context Protocol (MCP) in Multi-Agent Systems in 6.2 Security Threats at the MCP Protocol Level, 6.3 Security Risks of Tools and Resources Carried by the MCP Protocol). |
|
Remote MCP Services (Remote MCP Services) |
Cross-Agent/Information Privilege Escalation Identity Spoofing/Privilege Escalation Rogue Agent Decision Manipulation |
Forging agent identities, rogue agents, decision manipulation |
Affecting remote MCP service communication, thereby affecting agent communication (see Chapter Six: The Position, Role, and Related Attacks of the Model Context Protocol (MCP) in Multi-Agent Systems in 6.4 Security Risks at the MCP Transport Layer). |