Today is March 27, 2025, Thursday, Beijing, clear weather.
Today, we continue to discuss the R1 reasoning model and the topic of multi-agents.
There are three interesting experimental reports.
They are: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking (Think Twice), Length of Training Data is More Important than Difficulty for Training Reasoning Models, and Why Do Multi-Agent LLM Systems Fail.
The research on experimental schemes and some findings is quite meaningful, but the experimental conclusions depend on the experimental environment settings themselves and are for reference only.
By grasping the fundamental issues, addressing root causes, and systematizing topics, we can achieve deeper insights. Let’s work together.
1. Two Experiments on R1 Class Reasoning Model Training and Inference Performance
Regarding new discoveries in reasoning model thinking patterns,
1. Reasoning models benefit from thinking twice
It seems that thinking twice actually slows things down. The paper Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking (https://arxiv.org/pdf/2503.19855) proposes the idea of using previous answers as prompts for subsequent rounds, iteratively refining model reasoning. The key prompt is: {Original question prompt} The assistant’s previous answer was:

A more concrete reality is:
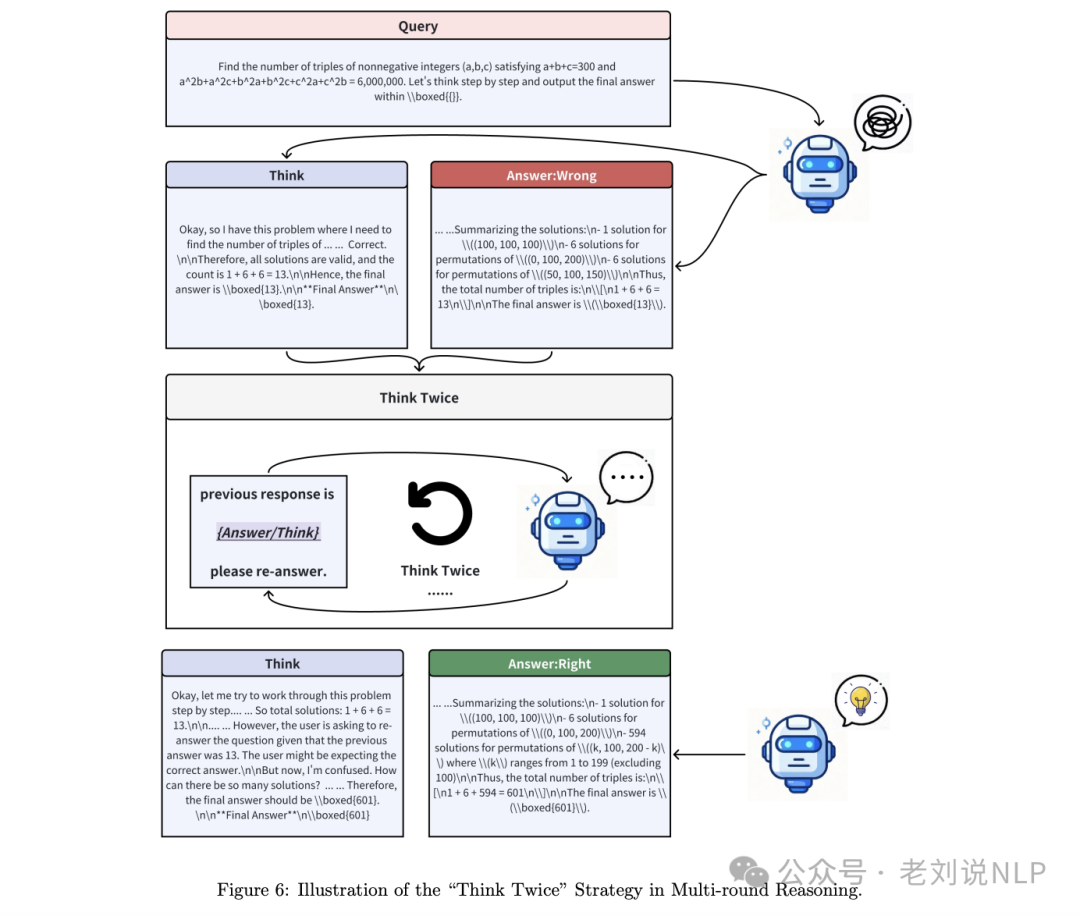
So, what are the results?
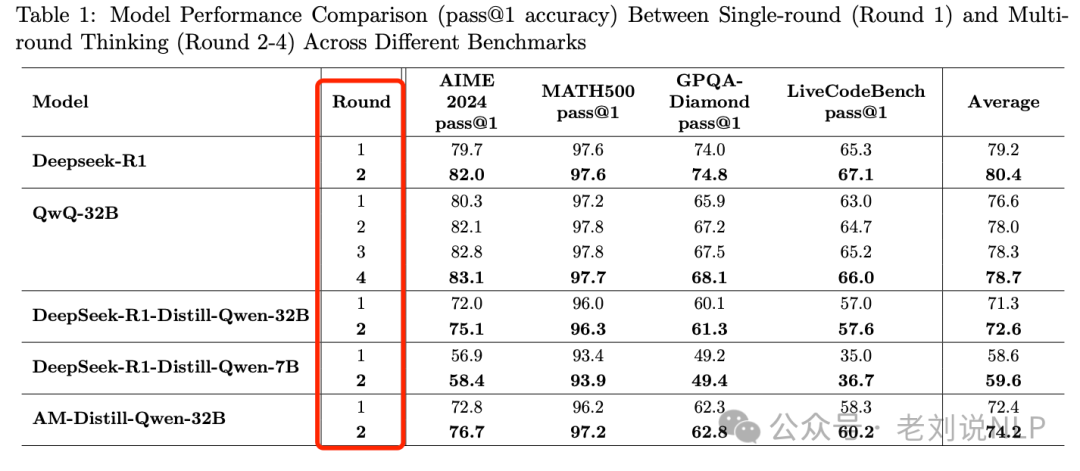
Extensive experiments conducted on multiple models such as QWQ-32B and DeepSeek-R1 show consistent performance improvements across various benchmark tests like AIME 2024 and MATH-500.
For example, the accuracy of QWQ-32B on the AIME 2024 dataset improved from 80.3% (first round) to 82.1% (second round), while DeepSeek-R1’s accuracy increased from 79.7% to 82.0%.
However, the question arises: will thinking again 1) lead to issues with instruction adherence due to inconsistencies with the training data? 2) Given that a single think is already perceived as slow, adding another round of thinking may increase time without significant practical value? Moreover, there is a contrary direction focusing on reducing think time, which is also worth attention.
2. The length of training data is more important than difficulty
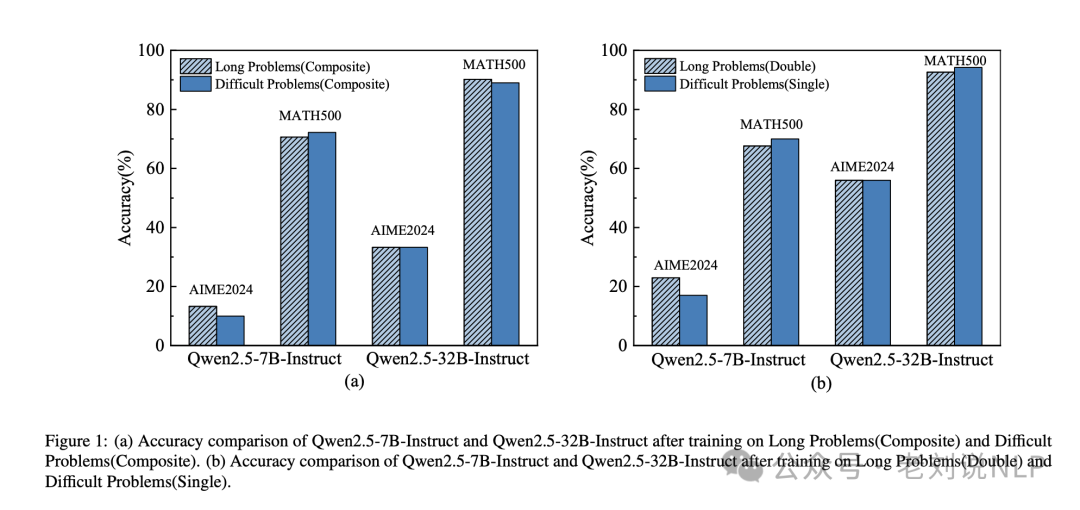
An experiment on R1 reasoning capability, Long Is More Important Than Difficult for Training Reasoning Models (https://arxiv.org/pdf/2503.18069), found that the primary factor affecting model performance is the reasoning length rather than the difficulty of the questions; determining the scaling law of reasoning length indicates that model performance grows logarithmically with the increase in reasoning data length.
After fine-tuning the Qwen2.5-32B instruction language model on the Long1K dataset, we proposed Long1K-32B, which, using only 1000 training samples, achieved a mathematical accuracy of 95.6% and a GPQA accuracy of 71.1%, outperforming DeepSeek-R1-Distil-QWEN-32B.
https://huggingface.co/ZTss/LONG1
2. Why do Multi-Agent Systems Fail?
This recent analysis conclusion is also quite interesting. Why Do Multi-Agent LLM Systems Fail? (https://arxiv.org/pdf/2503.13657) analyzes five popular MAS frameworks and over 150 dialogue trajectories, with six professional annotators identifying three categories of 14 failure modes.
Let’s look at a few points:
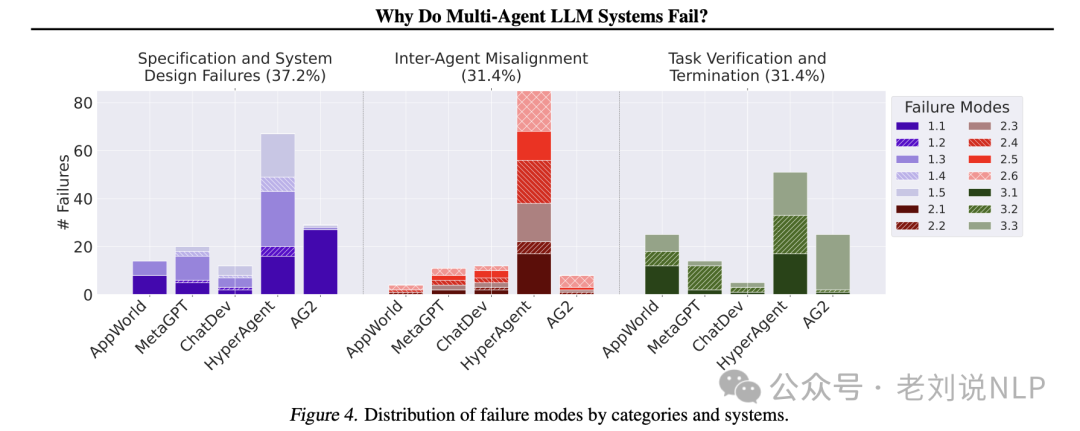
1. Specific definitions of the three categories of 14 failure modes
The three categories of 14 failure modes are as follows, and we can observe their actual distribution.

1) Specification and System Design Failures
This category includes failures caused by defects in system architecture design, poor dialogue management, unclear or violated task specifications, and insufficient or non-compliance with agent roles and responsibilities. There are five failure modes:
1.1 Non-compliance with task specifications. Failure to adhere to specified constraints or requirements of a given task, leading to suboptimal or incorrect results.
1.2 Non-compliance with role specifications. Failure to adhere to the defined responsibilities and constraints of assigned roles, which may cause one agent to behave like another.
1.3 Step repetition. Unnecessary repetition of completed steps in the process, which may cause delays or errors in task completion.
1.4 Loss of dialogue history. Unexpected context truncation, ignoring recent interaction history, and reverting to a previous dialogue state.
1.5 Lack of understanding of termination conditions. A lack of recognized or understood standards that should trigger the termination of agent interactions, which may lead to unnecessary continuations.
2) Inconsistencies between agents
This category includes failures caused by ineffective communication, poor collaboration, conflicting behaviors between agents, and gradually deviating from the initial task, with six failure modes:
2.1 Dialogue reset. Unexpected or unjustified restarting of dialogue, which may result in loss of context and progress made in interactions.
2.2 Failure to request clarification. Inability to request additional information when encountering unclear or incomplete data, which may lead to erroneous actions.
2.3 Task derailment. Deviation from the expected goals or focus of the established task, which may lead to irrelevant or ineffective actions.
2.4 Information concealment. Failure to share or communicate important data or insights that agents possess, which could affect the decisions of other agents if shared.
2.5 Ignoring inputs from other agents. Ignoring or failing to adequately consider inputs or suggestions provided by other agents in the system, which may lead to suboptimal decisions or missed collaboration opportunities.
2.6 Mismatch between reasoning and action. Discrepancies between the logical reasoning process and the actions actually taken by agents, which may lead to unexpected or undesired behaviors.
3) Task validation and termination
This category includes failures due to premature execution of termination and a lack of sufficient mechanisms to ensure the accuracy, completeness, and reliability of interactions, decisions, and outcomes, with three failure modes:
3.1 Premature termination. Ending dialogue, interaction, or tasks before all necessary information has been exchanged or goals have been achieved, which may lead to incomplete or incorrect results.
3.2 Inadequate or insufficient validation. (Partial) omission of appropriate checks or confirmations of task results or system outputs, which may allow errors or inconsistencies to propagate undetected.
3.3 Incorrect validation. Failure to adequately validate or cross-check key information or decisions during iterations, which may lead to errors or vulnerabilities in the system.
2. Five mainstream agent frameworks and their actual performance
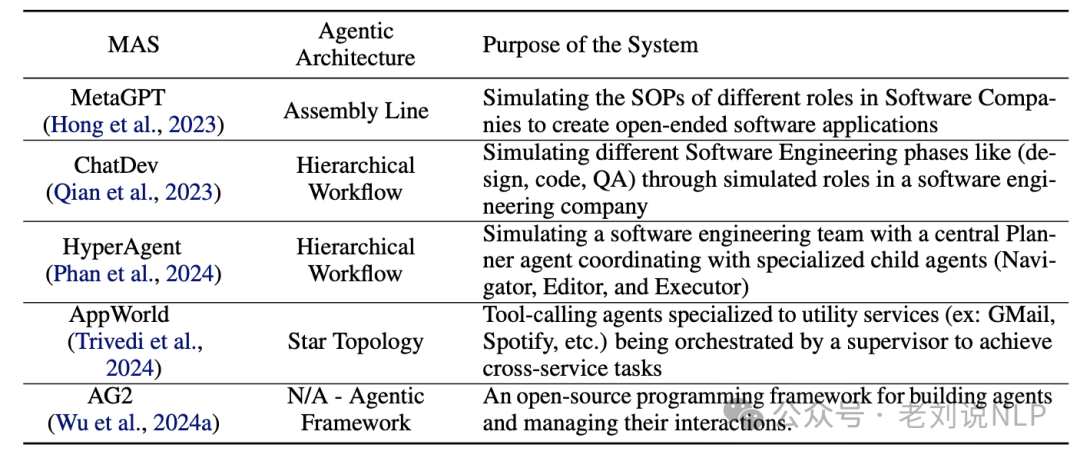
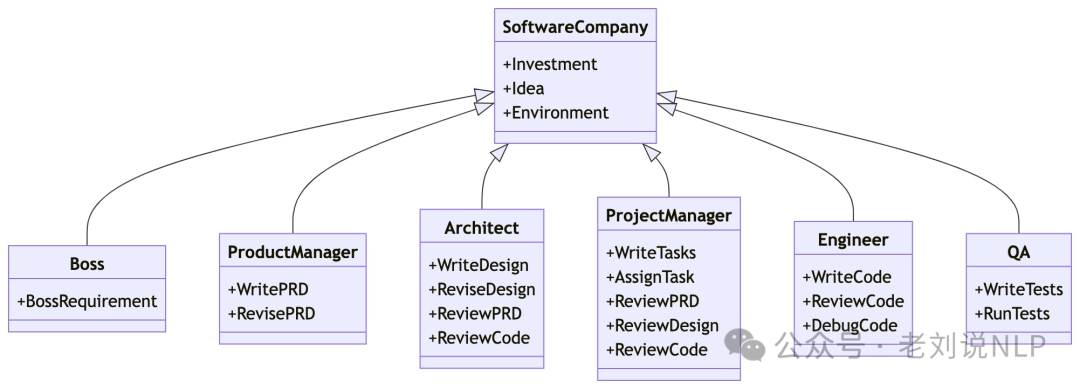
MetaGPT (https://arxiv.org/pdf/2308.00352, https://github.com/geekan/MetaGPT). Simulates a software engineering company involving agents such as coders and validators. The goal is to have agents with domain expertise collaborate to solve a programming task specified in natural language by encoding standardized operating procedures of different roles into agent prompts.
ChatDev (https://github.com/OpenBMB/ChatDev). Initializes different agents, each assuming common roles in a software development company. This framework divides the software development process into three stages: design, coding, and testing. Each stage is further subdivided into subtasks, for example, testing is divided into code review (static) and system testing (dynamic).

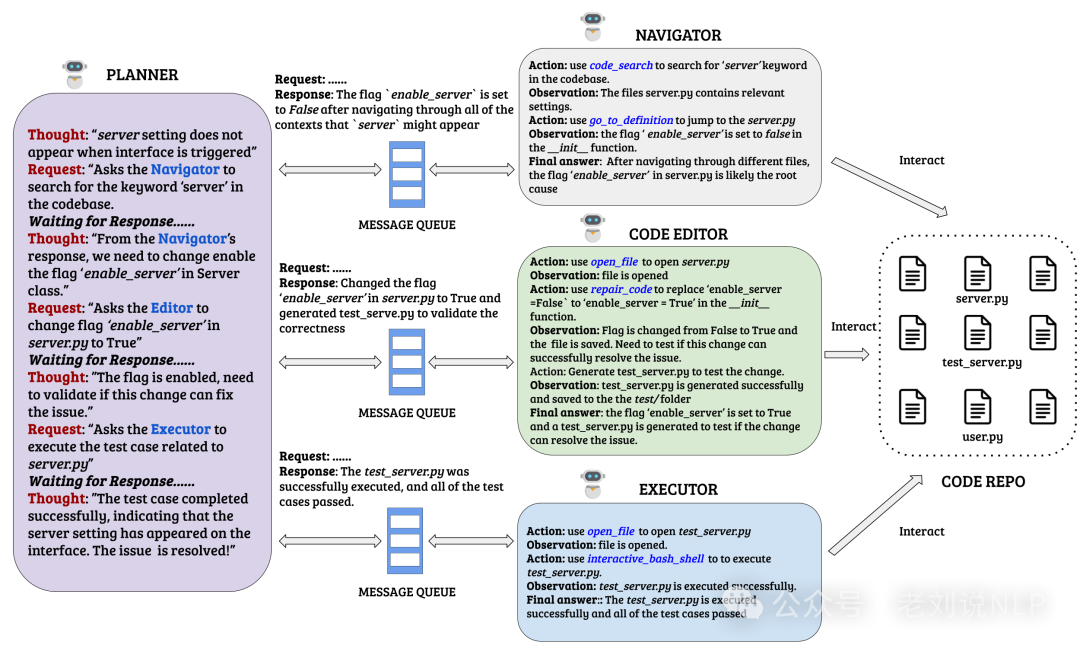
HyperAgent (https://github.com/FSoft-AI4Code/HyperAgent). Organizes software engineering tasks around four main agents: planner, navigator, code editor, and executor.
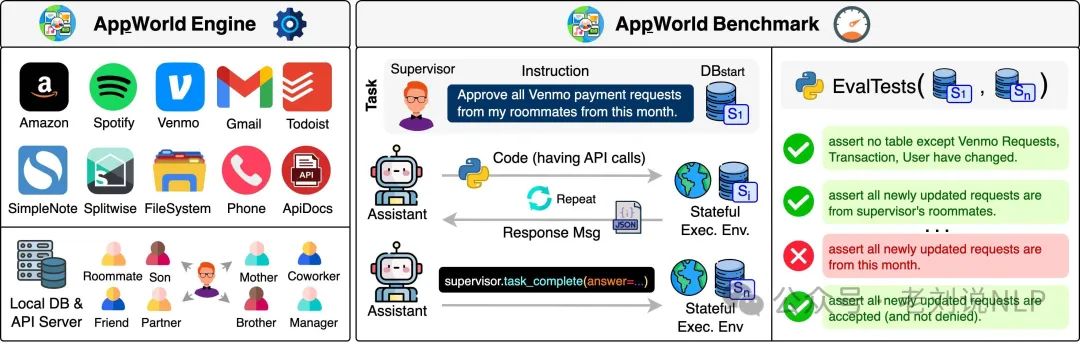
APPworld (https://arxiv.org/abs/2407.18901, https://github.com/StonyBrookNLP/appworld) introduces the AppWorld Engine, a high-fidelity execution environment containing 9 everyday applications that can be operated through 457 APIs, involving about 100 digital activities of people living in a simulated world, and benchmarks related to natural, diverse, and challenging autonomous agent tasks that require rich and interactive coding.
AG2 (https://github.com/ag2ai/ag2) is used to build agents and manage their interactions. With this framework, various flexible dialogue patterns can be constructed, integrating tool usage and customizing termination strategies.
The actual performance of several frameworks is as follows:
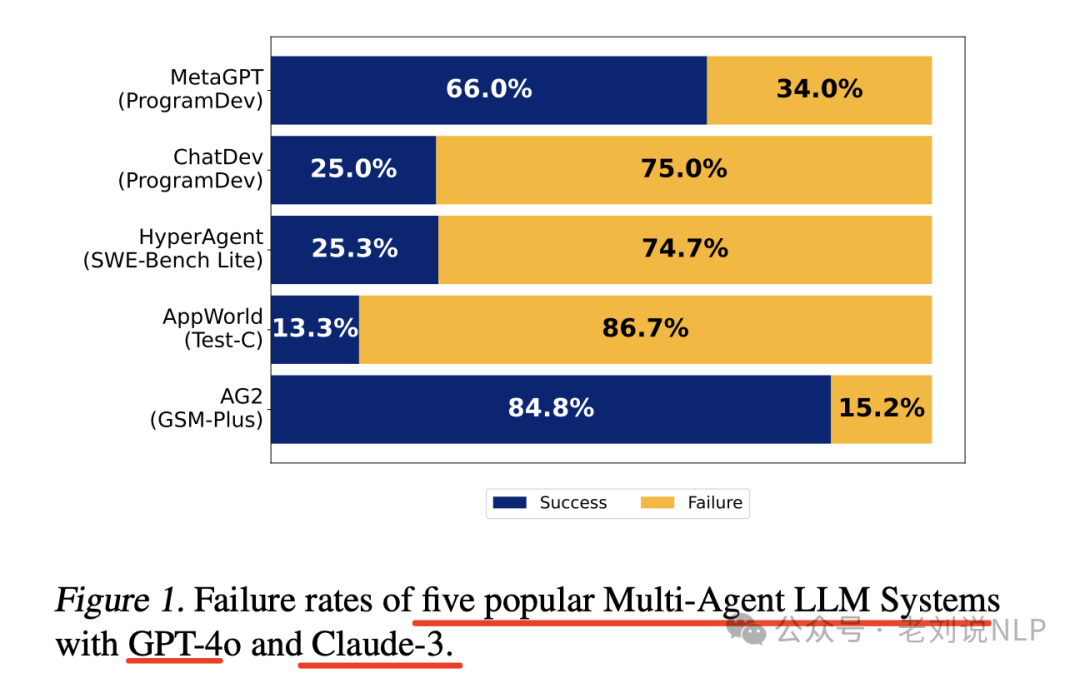
Specific effectiveness details are as follows:
References
1. https://arxiv.org/pdf/2503.13657
2. https://arxiv.org/pdf/2503.19855
3. https://arxiv.org/pdf/2503.18069
About Us
Lao Liu, an NLP open-source enthusiast and practitioner, homepage: https://liuhuanyong.github.io.
If you are interested in large models, knowledge graphs, RAG, document understanding, and would like to join the community for daily newsletters, online sharing of NLP history by Lao Liu, and exchange of insights, you are welcome to join the community, which is continuously recruiting.
How to join the community: Follow the public account and click on the membership community in the backend menu to join.