In the past two years, the most exciting development in the field of AI has been the rise of large language models (LLMs), which have demonstrated remarkable understanding and generation capabilities.
Building on this foundation, a grander vision has emerged: to construct Multi-Agent Systems (MAS).
Imagine not a single AI working alone, but a “dream team” of multiple specialized AI agents, each possessing specific skills (such as coding, design, testing, communication) that collaborate to accomplish complex, multi-step tasks, such as developing software, conducting scientific research, or even simulating human social behavior.
The potential of this “collective intelligence” is tantalizing: task decomposition, parallel processing, specialization, brainstorming…
Theoretically, MAS should be able to tackle grand challenges that a single LLM struggles with, achieving a “1+1 > 2” effect. However, reality can be quite stark.

Despite the industry’s enthusiasm for MAS, in many benchmark tests, the performance of these “AI dream teams” shows only marginal improvement compared to single-agent frameworks, and sometimes even worse. This raises the question:
Why do these seemingly powerful AI teams often fail in practice?
This paper from UC Berkeley systematically and deeply investigates this issue for the first time.
The researchers did not simply attribute the failures to the limitations of LLMs themselves (such as “hallucination” or “alignment” issues), but instead focused on the complexity of MAS system design and the interactions between agents.
Through detailed analysis of five popular MAS frameworks and over 150 task execution processes, they proposed a taxonomy called MASFT (Multi-Agent System Failure Taxonomy), which systematically reveals the root causes of these system failures.

- Paper link:https://arxiv.org/pdf/2503.13657
- Paper title:Why Do Multi-Agent LLM Systems Fail?
- Research team:UC Berkeley
- Github link:https://github.com/multi-agent-systems-failure-taxonomy/MASFT
Background Knowledge: What are LLM Agents and Multi-Agent Systems (MAS)?
Before we delve into the reasons for failure, let’s quickly understand some key concepts:
1. Large Language Models (LLM):
These can be understood as an extremely powerful “brain” that learns to understand and generate human language through training on vast amounts of text data, even possessing some reasoning and planning capabilities.
2. LLM-based Agent:
This is not just the LLM itself. An LLM agent typically consists of “LLM brain + specific instructions/role settings + memory (dialogue history) + action capabilities (such as using tools, calling APIs)“.
You can think of it as an intelligent assistant endowed with a specific identity and tools, such as an “AI programmer”, “AI researcher”, or “AI customer service agent”. It can dynamically interact with its environment (such as the internet, software tools) based on task requirements and adjust its behavior according to feedback.
3. Multi-Agent Systems (MAS):These are collections of multiple LLM agents designed to communicate and coordinate with each other to achieve a larger goal. The intention behind designing MAS is to leverage the power of “division of labor and collaboration”, for example:
- Task decomposition: Breaking complex tasks into smaller parts for specialized agents to handle.
- Parallel processing: Multiple agents working simultaneously to increase efficiency.
- Context isolation/specialization: Each agent focuses on its own domain, avoiding information overload and enhancing expertise.
- Diverse reasoning/discussion: Different agents may propose different insights, leading to better solutions through discussion or debate.
The MAS systems studied in the paper (such as MetaGPT, ChatDev, HyperAgent, AppWorld, AG2) simulate collaborative models of software companies, research teams, etc. For instance, ChatDev simulates a software development company, including AI agents in roles such as CEO, CTO, programmers, and testers, who complete software development tasks through dialogue.
MAS Falls Short of Expectations
Let’s look at some data:
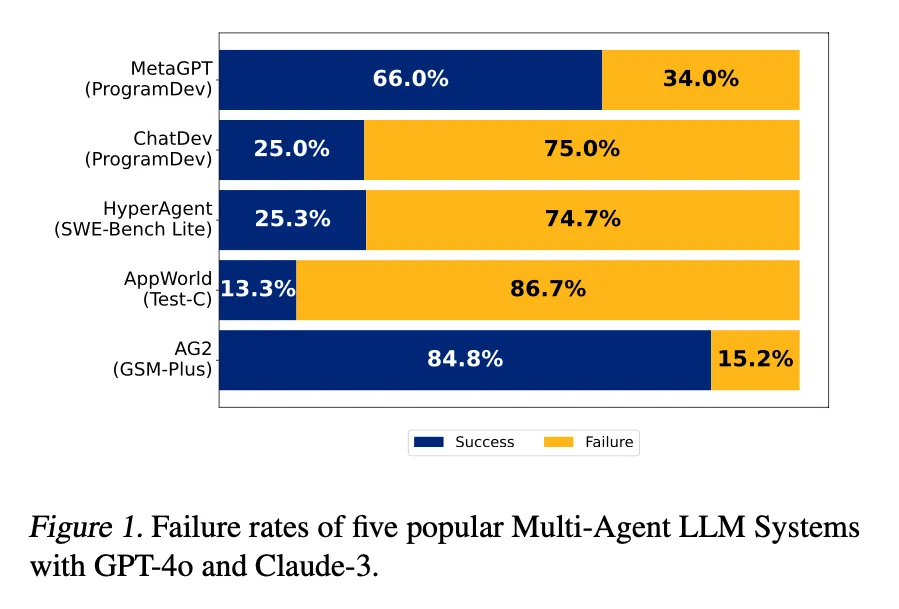
In some popular MAS frameworks and tasks, the success rates are shockingly low:
- MetaGPT (software development task): Success rate only 66.0%
- ChatDev (software development task): Success rate only 25.0%
- HyperAgent (software engineering benchmark): Success rate only 25.3%
- AppWorld (cross-application task): Success rate only 13.3%
- AG2 (math problem solving): Success rate 84.8% (relatively high, but still a 15.2% failure rate)
This means that even with powerful underlying LLMs (such as GPT-4o, Claude-3), these carefully designed AI teams often fail to successfully complete tasks in many cases. This performance starkly contrasts with expectations of their “collective intelligence”.
Failures Attributed to 14 Specific Failure Modes
To systematically identify the reasons for failure, the researchers employed Grounded Theory.
They invited six human experts to carefully review over 150 task execution records from five different MAS systems (each record averaging over 15,000 lines of text, primarily consisting of dialogues and action logs between agents).
The core of Grounded Theory is to let theories emerge naturally from the data rather than pre-setting hypotheses. The experts repeatedly read, marked, and discussed the failure points in these records, continuously refining and summarizing, ultimately forming a classification system that includes 14 specific failure modes, which are categorized into three major classes. This classification system is called MASFT.

To ensure the reliability of the classification system, the researchers conducted inter-annotator agreement tests.
Three experts independently used MASFT to annotate the same batch of task records, calculating their level of agreement (Cohen’s Kappa coefficient). After multiple rounds of iterative optimization, the final MASFT achieved a Kappa score of 0.88, indicating that the classification system has high reliability and consistency.
Next, we will detail the three major failure categories of MASFT and the specific modes they include:
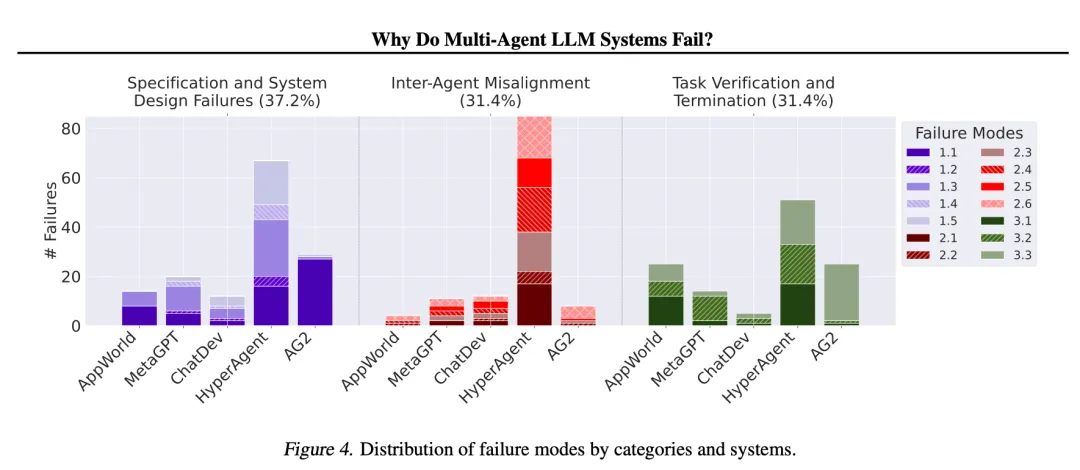
Category One: Specification and System Design Failures (37.17% of total failures)
These failures stem from defects in the system design itself, unclear task instructions, or agents failing to adhere to their roles and responsibilities. Just like in a project team, if the project goals are vague, member responsibilities unclear, and workflows chaotic, failure is almost inevitable.
FM-1.1: Disobey task specification (15.2%):
Agents fail to comply with specific requirements or constraints of the task.
For example: ChatDev was asked to develop a two-player chess game using standard international chess notation (like ‘Ke8’, ‘Qd4’) as input, but it ultimately generated a game that required input of the coordinates of the pieces before and after the move (x1, y1), (x2, y2), which completely did not meet the requirements.
FM-1.2: Disobey role specification (1.57%):
Agents overstep their defined roles and do things beyond their responsibilities.
For example: During the requirement analysis phase in ChatDev, the agent playing the role of “Chief Product Officer (CPO)” sometimes skips discussions with the “CEO” and unilaterally defines the product vision and makes final decisions, which clearly exceeds the CPO’s responsibilities.
FM-1.3: Step repetition (11.5%):
Unnecessarily repeating steps that have already been completed, leading to delays or errors.
For example: The “Navigator” agent in HyperAgent repeatedly proposes the same steps to find code, even though it has already tried them or the problem has shifted.
FM-1.4: Loss of conversation history (2.36%):
The system unexpectedly truncates context, causing agents to forget recent interactions and revert to previous states.
For example: HyperAgent, while resolving a programming bug, initially decided to replace the required lightgbm library with a scikit-learn model (because it was not installed), but in subsequent interactions, it seems to forget this decision and goes back to trying to install lightgbm.
FM-1.5: Unaware of termination conditions (6.54%):
Agents do not know or understand when they should end interactions, leading to unnecessary dialogues continuing.
For example: In AG2, while solving a math problem, even after providing the correct (or unsolvable) answer, the agent continues to insist on proceeding, not realizing that the task has ended.
Category Two: Inter-Agent Misalignment (31.41% of total failures)
These failures occur during communication and collaboration between agents. Even if each agent appears “smart” individually, if they do not communicate effectively, have conflicting goals, or misunderstand each other, the overall performance of the team can suffer significantly. This is akin to a team lacking effective communication mechanisms, leading to information barriers, redundant work, or even internal strife.
FM-2.1: Conversation reset (5.50%):
Conversations unexpectedly or without reason restart, losing previous context and progress.
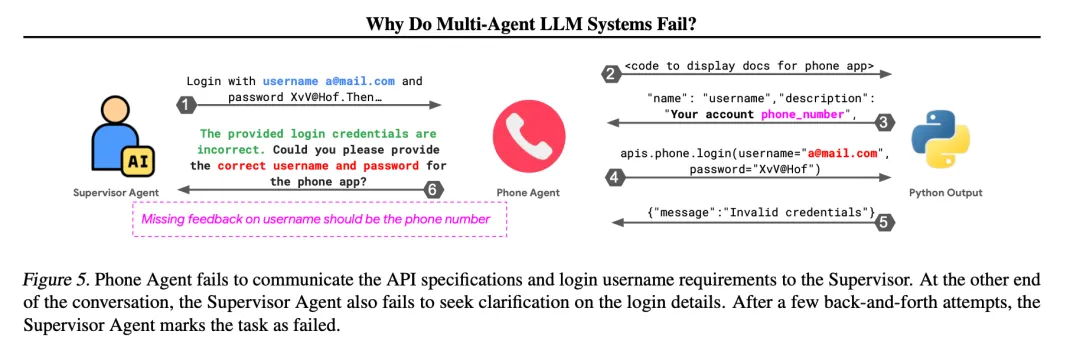
FM-2.2: Fail to ask for clarification (2.09%):
When faced with vague or incomplete information, agents fail to proactively request more information and instead act based on assumptions, leading to errors.
For example: In AppWorld, the “Supervisor” agent instructs the “Phone” agent to log in using an email address as the username, but the API documentation clearly requires a phone number. The “Phone” agent discovers this but does not clarify with the supervisor and instead attempts to log in with the incorrect email address, leading to failure. Meanwhile, the “Supervisor” agent also fails to check or inquire about details when providing instructions.
FM-2.3: Task derailment (5.50%):
Conversations or actions gradually deviate from the initially set task goals, becoming irrelevant or inefficient.
For example: AG2, while solving a math problem, may get sidetracked by some calculation detail, starting to solve a completely different problem, or after finding the correct answer, continues with unrelated calculations.
FM-2.4: Information withholding (6.02%):
One agent possesses information crucial to the task but fails to share it with other agents.
For example: The “Navigator” in HyperAgent sometimes finds potential solutions but fails to communicate them fully to the “Planner”, preventing the latter from making correct decisions.
FM-2.5: Ignored other agent’s input (4.71%):
Agents ignore or fail to adequately consider inputs, suggestions, or corrections provided by other agents.
For example: In the Multi-Agent Peer Review system, one agent received correct feedback from another agent regarding its mathematical problem-solving process, pointing out a calculation error. The agent verbally acknowledged the feedback but still insisted on its original incorrect result in the final answer, failing to adopt the correct correction.
FM-2.6: Reasoning-action mismatch (7.59%):
The internal “thinking” (reasoning process) of an agent does not align with the final “action” it takes (such as calling tools, generating code).
For example: The “Navigator” in HyperAgent, while analyzing a pylint bug, correctly identifies the problem and the code location that needs modification in its internal thought process, but in the final “answer” given to the “Planner”, it provides different or even unrelated suggestions.
Category Three: Task Verification and Termination Failures (31.41% of total failures)
These failures pertain to the “closing” phase of tasks: how to ensure the quality of the final results (correctness, completeness, reliability), and how to appropriately end tasks. A lack of effective quality control and clear termination mechanisms can lead to poor deliverables or wasted resources.
FM-3.1: Premature termination (8.64%):
Conversations, interactions, or tasks are ended before all necessary information has been exchanged or goals achieved.
For example: The “Editor” agent in HyperAgent claims to have completed modifications to the code, but in reality, it has not executed the modification operation and prematurely ends its task phase, leading to subsequent steps that depend on that modification failing.
FM-3.2: No or incomplete verification (9.16%):
The system lacks verification steps, or the verification steps do not cover all critical aspects, leading to errors or inconsistencies being overlooked.
For example: In ChatDev, while implementing the chess game, the agent responsible for verification only checks if the code compiles but does not actually run the game or check if it adheres to all chess rules (such as special moves, capturing rules, etc.), nor does it verify if the input and output meet task requirements. This leads to the possibility that even if the code runs, the game itself may be full of loopholes or unplayable. In AG2, while the total cost in a math problem may be calculated correctly, it may fail to perform subtraction verification when calculating the remaining amount or miscount the number of digits given in the problem.
FM-3.3: Incorrect verification (13.61%):
Verification steps exist, but the verification itself is incorrect or invalid, failing to identify actual problems.
For example: In MetaGPT, while implementing a board game, unit tests may only cover the most basic cases (like pawn movement) and fail to cover the complex movement rules of non-pawn pieces, mistakenly believing verification has passed. In the Multi-Agent Peer Review, agents reviewing peers’ answers may also make the same mistakes or fail to identify obvious logical flaws, giving incorrect “verification passed” conclusions.
What Do These Failures Mean? Not Just Technical Issues
The diverse failure modes revealed by MASFT, and their varying distribution across different MAS systems, indicate that the failures of MAS are not dominated by a single cause, but are systemic and diverse issues.
Interestingly, the authors of the paper connect these AI systems’ failure modes with research on High-Reliability Organizations (HROs).
HROs refer to organizations that maintain extremely low accident rates in highly complex and high-risk environments (such as nuclear power plants, aircraft carriers).
Research has found that HROs typically possess some key characteristics, such as extreme hierarchical differentiation, respect for expertise, and vigilance towards failures. Many failure modes in MASFT, however, violate these principles of HRO success:
- “Disobey role specification” (FM-1.2) violates “extreme hierarchical differentiation”.
- “Fail to ask for clarification” (FM-2.2) violates “deference to expertise”.
This indicates that building a successful MAS is not merely about enhancing the intelligence of the underlying LLMs; it is more akin to constructing an organization. If the organizational structure, communication protocols, distribution of responsibilities, and quality control processes are poorly designed, even if each member (agent) is “smart”, the entire system may operate inefficiently, make frequent errors, or even collapse entirely, much like a mismanaged company.
The opening lines of the paper are particularly apt:

“Happy families are all alike; every unhappy family is unhappy in its own way.” (Tolstoy, 1878)
Thus, successful systems are similar; failed systems each have their own problems.
Can These Issues Be Fixed?
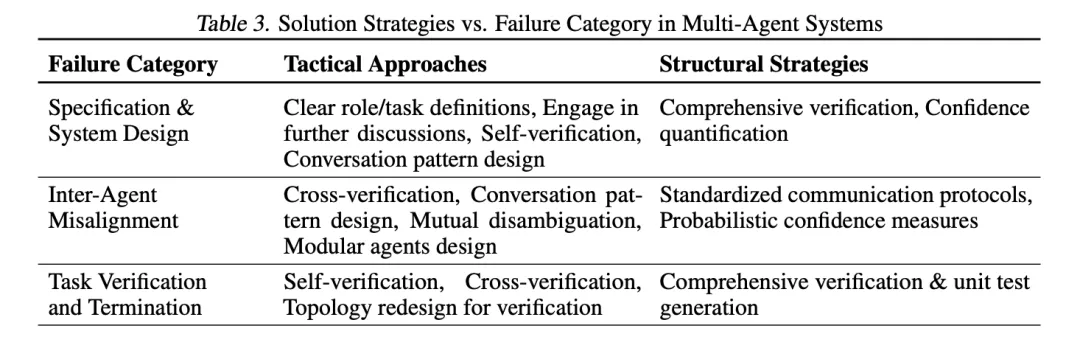
Having identified the problems, it is natural to seek solutions. The paper discusses two types of strategies:
1. Tactical Approaches:
These are relatively direct, targeted “quick fixes” for specific failure modes. For example:
- Improving prompts: Providing clearer task instructions and role definitions
- Optimizing agent topology/communication patterns: Changing the way agents connect and the rules of dialogue (e.g., from linear processes to circular feedback, or adding dedicated coordinators).
- Incorporating self-verification/retry mechanisms: Allowing agents to self-check after completing tasks or attempt to re-communicate when inconsistencies arise (Appendix E.5).
- Majority voting/resampling: Running multiple times or having multiple agents provide answers, selecting the most consistent result.
The researchers tried these tactical methods in two cases (AG2-MathChat and ChatDev, Sec 6). The results showed:
These methods do bring some improvements (for example, the improved ChatDev’s accuracy on the ProgramDev task increased from 25% to 40.6%), but the effects are limited and unstable.
For AG2, improving prompts had significant effects on GPT-4, but on GPT-4o, the new topology performed poorly. This indicates that these “band-aid” methods do not cure all problems.
2. Structural Approaches:
These are more fundamental, systemic changes aimed at enhancing the robustness and reliability of MAS from the infrastructure level. This often requires deeper research and more complex implementations.
- Robust verification mechanisms: Designing universal, cross-domain verification frameworks (not just code testing, but possibly involving logical verification, fact-checking, QA standards, etc.). The paper emphasizes the importance of verification, considering it the “last line of defense” against failures, but constructing universal verification mechanisms is highly challenging.
- Standardized communication protocols: Defining clear, structured communication languages and formats between agents to reduce ambiguity and achieve reliable interactions similar to computer network protocols.
- Uncertainty quantification: Enabling agents to assess and express their “confidence levels” regarding information or conclusions, actively seeking more information or taking more conservative actions when confidence is low.
- Enhanced memory and state management: Improving how agents record, retrieve, and utilize long-term/short-term memory to ensure contextual coherence.
- Reinforcement learning-based collaborative training: Training agents to learn better teamwork by rewarding desired behaviors (such as effective communication, adherence to roles, successful collaboration) and penalizing undesirable behaviors.
These structural approaches are considered key to solving MAS failure issues in the future, but they also present new research challenges.
This research provides us with the first systematic framework for understanding why LLM-based multi-agent systems frequently fail.
The paper clearly reveals that these failures are not merely issues with the underlying AI models, but more deeply rooted in systemic design, interactions between agents, and verification mechanisms, which are strikingly similar to the operational dilemmas of complex human organizations.
Furthermore, the findings remind us that it is unrealistic to expect that simple prompt engineering or fine-tuning will enable the “AI dream team” to reach its full potential.
Future efforts will require deeper, more fundamental structural changes, including designing more robust verification systems, more reliable communication protocols, and more effective collaboration mechanisms, to gradually build truly reliable, efficient multi-agent systems capable of addressing complex real-world challenges.
The road ahead is filled with challenges, but this paper undoubtedly provides a failure map to advance “collective intelligence”.

