Follow the WeChat public account “ML_NLP“ and set it as a “starred“, delivering substantial content to you in real-time!

This article is authorized to be transferred from the Zhihu author Anticoder, https://zhuanlan.zhihu.com/p/59413549. Unauthorized reproduction is prohibited.
Background: Focusing solely on a single model may overlook potential information that could enhance the target task from related tasks. By sharing parameters to a certain extent across different tasks, the original task may generalize better. In general, as long as there are multiple losses, it counts as MTL, with some aliases (joint learning, learning to learn, learning with auxiliary tasks).
Objective: To enhance the model’s generalization and performance by balancing training information from the main task and related auxiliary tasks. From a machine learning perspective, MTL can be viewed as a form of inductive transfer (prior knowledge), which improves model performance by providing inductive bias (a certain prior assumption about the model). For example, using L1 regularization biases our model towards a sparse solution (fewer parameters). In MTL, this prior is provided through auxiliary tasks, which is more flexible, guiding the model to favor some other tasks, ultimately leading to better generalization.
MTL Methods for DNN
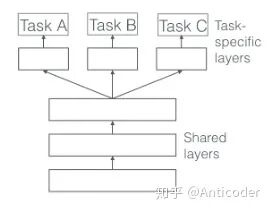
- hard parameter sharing (this method is already 26 years old <1993>)
Share some parameters across all tasks (generally at the lower layers), while using unique parameters for specific task layers (top layers). In this case, the risk of overfitting for shared parameters is relatively low (compared to non-shared parameters), with the overfitting risk being O(#tasks). [1]
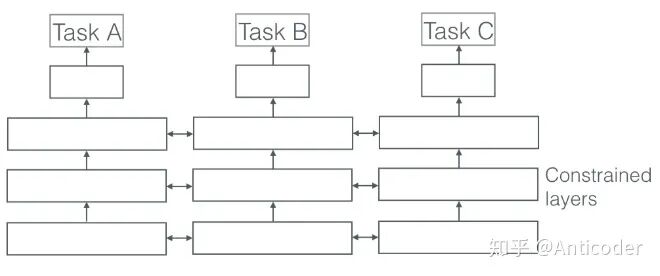
- soft parameter sharing
Each task has its own parameters, and finally constraints are applied to the differences between parameters of different tasks to express similarity. For example, L2, trace norm, etc.
Advantages and Use Cases
- implicit data augmentation: Each task generally has sample noise, and different tasks may have different noise, ultimately learning from multiple tasks can cancel out some noise (similar to the idea of bagging, where noise exists in various directions and averages out to zero).
- Some tasks with significant noise or insufficient training samples, high dimensionality, may not allow the model to learn effectively, or even fail to learn relevant features.
- Certain features may be difficult to learn in the main task (for example, only existing high-order correlations or suppressed by other factors), but can be learned well in auxiliary tasks. Auxiliary tasks can be used to learn these features, methods such as hints (predicting important features) [2].
- By learning a sufficiently large hypothesis space, the model can perform well on some new tasks in the future (solving cold start), provided that these tasks are of the same origin.
- As a form of regularization, constraining the model. The so-called inductive bias. Mitigating overfitting, reducing the model’s Rademacher complexity (the ability to fit noise, used to measure the model’s capacity).
MTL in Traditional Methods (linear models, kernel methods, Bayesian algorithms) mainly focuses on two points:
- Achieving sparsity between tasks through norm regularization
- Modeling the relationships between multiple tasks
1.1 Block-sparse regularization (mixed l1/lq norm)
Objective: To force the model to consider only a subset of features, under the premise that different tasks must be related.
Assuming K tasks share the same features and the same number of model parameters, a matrix A(DxK) is formed, where D is the parameter dimension and K is the number of tasks. The goal is for these tasks to use only some features, meaning some rows of A should be zero. (The simplest idea is to make it a low-rank matrix; or use L1 regularization, as L1 can constrain certain features to zero. If we want to make certain rows zero, we can first perform a row aggregation operation, then apply L1 to the aggregated result, for specifics refer to article [3]. Typically, using lq norm to constrain rows (each feature) first, then applying L1 norm for further constraints, is known as mixed l1/lq norm.
Development:
- group lasso [4]: l1/l2 norm, solving the non-convexity of l1/l2 norm through trace norm; subsequently, an upper bound for using group lasso in MTL was proposed [5].
- When there are few common features among multiple tasks, l1/lq norm may not perform as well as element-wise norm. Some proposed combining these two methods, decomposing the parameter matrix into A = S + B, applying lasso to S and l1/l_infinite to B. [6]
- distributed version of group-sparse regularization [7].
2.1 Regularization for Learning Task Relationships
When the correlation between tasks is weak, using the above methods may lead to negative transfer (i.e., adverse effects). In this scenario, we hope to introduce prior knowledge indicating that some tasks are related, while others are less so. This can be achieved by introducing task clustering to constrain the model. By penalizing the parameter vectors of different tasks and their variances, we can limit different models to converge towards their respective cluster mean vectors.
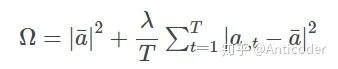
Similarly, in SVM, introducing Bayesian methods, we can pre-specify some clusters, aiming to maximize the margin while guiding different tasks towards their respective cluster centers; [8]
Once clusters are specified, we can constrain the model through clustering methods (intra-class, inter-class, and its own complexity).
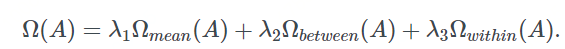
In some scenarios, tasks may not appear in the same cluster but may have similar underlying structures, such as group-lasso in tree-structured and graph-structured tasks.
2.2 Other Methods for Learning Task Relationships
- KNN methods for task clustering. [9]
- Semi-supervised learning for learning common structures of some related tasks. [10]
- Multi-task BNN, controlling the similarity of multiple tasks through priors, with a complex model that can use sparse approximation to greedily select samples [11]; Gaussian processes using the same covariance matrix and prior across different tasks (thereby reducing complexity) [12].
- Using Gaussian priors for each task-specific layer, a mixture distribution of a cluster (predefined) can be used to promote similarity among different tasks [13].
- Furthermore, sampling distributions through a Dirichlet process can establish the similarity between tasks and the number of clusters. Tasks in the same cluster use the same model [14].
- hierarchical Bayesian model, learning a latent task structure [15].
- MTL extension of the regularized Perceptron, encodes task relatedness in a matrix. It can then be constrained through different regularizations (e.g., rank) [16].
- Different tasks belong to different independent clusters, each cluster existing in a low-dimensional space, with tasks in each cluster sharing the same model. By alternating iterations, we can learn the distribution weights of different clusters and the model weights for each cluster. Assuming absolute independence between tasks may not be ideal [17].
- Assuming there is overlap between two tasks from different clusters, there exists a portion of latent basis tasks. Let the model parameters for each task be a linear combination of the latent basis tasks, constraining the latent basis tasks to be sparse. The overlapping part controls the degree of sharing [18].
- Learning a small set of shared hypotheses, then mapping each task to a single hypothesis [19].
MTL in DNN
Deep Relation Network [20]
In computer vision, convolutional layers are generally shared, followed by task-specific DNN layers. By setting priors on the task layers, the model learns the relationships between tasks.
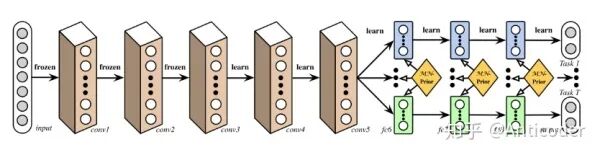
Fully-Adaptive Feature Sharing [21]
Starting from a simple structure, greedily and dynamically widening the model to cluster similar models. Greedy methods may not learn the globally optimal structure; each branch for a task may fail to learn the complex relationships between tasks.
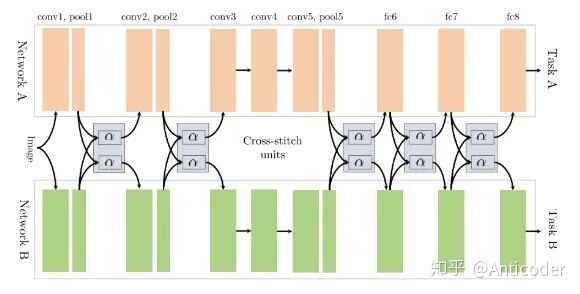
Cross-stitch Networks [22]
soft parameter sharing, learning the outputs of the previous layer through linear combinations, allowing the model to determine the degree of sharing between different tasks.
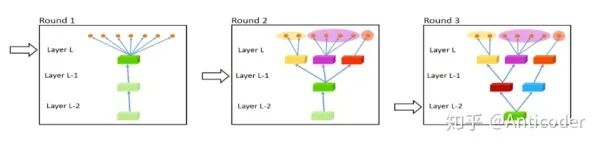
Low supervision [23]
Finding better multi-task structures, the lower layers of complex tasks should be supervised by the objectives of lower-level tasks (for example, in NLP, the first few layers learn an auxiliary task of NER or POS).
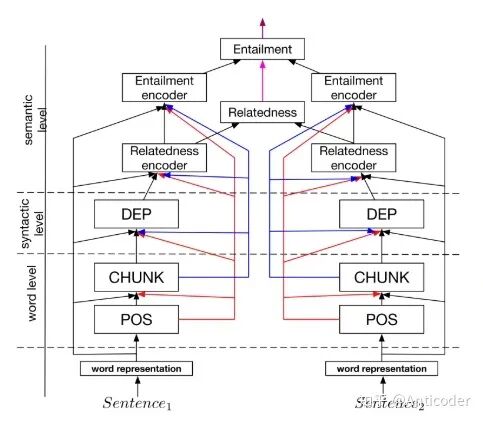
A Joint Many-task Model [24]
Pre-setting a hierarchical structure for multiple NLP tasks, followed by joint learning.
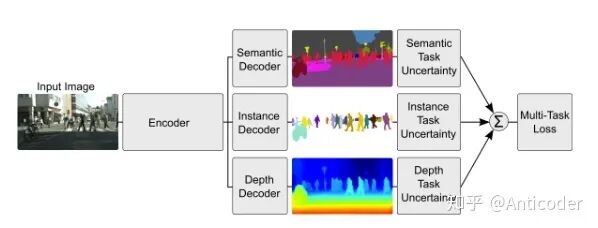
Weighting losses with uncertainty [25]
Not considering learning shared structures, but considering the uncertainty of each task. By optimizing loss (Gaussian likelihood with task-dependent uncertainty), adjusting the similarity between different tasks.
Tensor factorization for MTL [26]
Decomposing parameters for each layer into shared and task-specific.
Sluice Networks [27]
A mix of (hard parameter sharing + cross-stitch networks + block-sparse regularization + task hierarchy (NLP)), allowing the model to learn which layers and subspaces to share, and where to find the optimal representation of inputs.
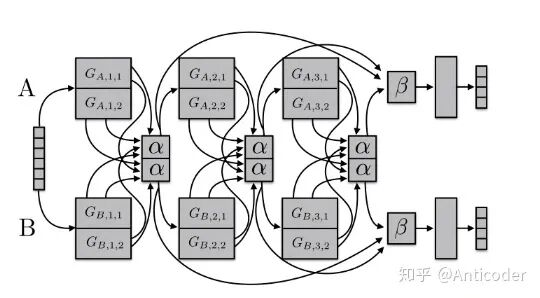
When the correlation between different tasks is high, sharing parameters is beneficial. But what about tasks with low or no correlation?
Early work involved pre-specifying which layers to share for each pair of tasks, which has poor scalability and a biased model structure; when task correlation decreases or different levels of reasoning are required, hard parameter sharing becomes ineffective.
Currently, a hot topic is learning what to share (outperforming hard parameter sharing); and learning the task hierarchy is also useful when tasks have multi-granularity factors.
Auxiliary Tasks
We focus only on the main task objective, but hope to benefit from other effective auxiliary tasks!
Currently, some methods for selecting auxiliary tasks include
- Related tasks: Conventional ideas (autonomous driving + road sign recognition; query classification + web search; coordinate prediction + object recognition; duration + frequency).
- Adversarial: In domain adaptation, related tasks may not be accessible, and adversarial tasks can be used as negative tasks (maximizing training error), for example, an auxiliary task predicting the input domain, leading the main task model to learn representations that cannot distinguish different domains.
- Hints: Some features may be difficult to learn in certain tasks, selecting auxiliary tasks for predicting features (in NLP, the main task is sentiment prediction, and the auxiliary task is whether the inputs contain positive or negative words; the main task is name error detection, and the auxiliary task is whether there are names in the sentence).
- Focusing attention: Making the model pay attention to parts that may be easily overlooked in the task (autonomous driving + road sign detection; facial recognition + head position recognition).
- Quantization smoothing: In some tasks, the training objective is highly discretized (manual scoring, sentiment scoring, disease risk levels), using auxiliary tasks with lower discretization may be helpful, as smoother objectives make tasks easier to learn.
- Predicting inputs: In some scenarios, certain features may not be selected due to their adverse effects on estimating the target, but these features can be helpful for model training. In such cases, these features can be treated as outputs rather than inputs.
- Using the future to predict the present: Some features only become available after a decision is made, for example, in autonomous driving, data about objects is only obtained when the vehicle passes by them; in medicine, the effects of a drug are only known after it has been used. These features cannot be used as inputs but can serve as auxiliary tasks to provide information to the main task during training.
- Representation learning: Auxiliary tasks often implicitly learn some feature representations, which are beneficial to the main task to some extent. They can also explicitly learn this (using an auxiliary task that learns to transfer feature representations, such as AE).
So, which auxiliary tasks are useful?
The assumption behind auxiliary tasks is that they should be somewhat related to the main task, aiding in its learning.
How to measure the similarity between two tasks?
Some theoretical studies:
- Using the same features for decision-making.
- Related tasks share the same optimal hypothesis space (having the same inductive bias).
- F-related: If the data for two tasks is obtained through a fixed distribution with some transformations [28].
- Classification boundaries (parameter vectors) are close.
Task similarity is not binary; the more similar the tasks, the greater the benefit. Learning what to share allows us to temporarily overlook theoretical shortcomings, as even tasks with poor correlation can still yield benefits. However, developing task similarity is absolutely helpful in selecting auxiliary tasks.
MTL Learning Tips
- Auxiliary tasks with compact and uniformly distributed labels are better (from POS in NLP) [29].
- The main task training curve stabilizes faster, while auxiliary tasks stabilize more slowly (not yet stabilized) [30].
- Different tasks may have different scales, optimal learning rates for tasks may vary.
- The output of a certain task can serve as input for some tasks.
- Some tasks may have different iteration cycles, requiring asynchronous training (posterior information; feature selection, feature derivation tasks, etc.).
- The overall loss may be dominated by certain tasks, necessitating dynamic adjustments to parameters throughout the cycle (by introducing some uncertainty, each task learns a noise parameter, unifying all losses [31]).
- Some estimates can serve as features (alternating training).
Conclusion
Over 20 years old, hard parameter sharing is still popular, and the current hot topic of learning what to learn is also valuable. Our understanding of tasks (similarity, relationship, hierarchy, benefits for MTL) remains limited, and we hope for significant developments in the future.
Research Directions
- Learning what to share.
- Measurement for similarity of tasks.
- Using task uncertainty.
- Introducing asynchronous tasks (feature learning tasks), adopting alternating iterative training.
- Learning abstract sub-tasks; learning task structures (similar to hierarchy learning in reinforcement learning).
- Parameter learning auxiliary tasks.
- More…
Note: The learning materials for this article are mainly from _An Overview of Multi-Task Learning in Deep Neural Networks, https://arxiv.org/abs/1706.05098
References
[1] A Bayesian/information theoretic model of learning to learn via multiple task sampling. http://link.springer.com/article/10.1023/A:1007327622663
[2] Learning from hints in neural networks. Journal of Complexity https://doi.org/10.1016/0885-064X(90)90006-Y
[3] Multi-Task Feature Learning http://doi.org/10.1007/s10994-007-5040-8
[4] Model selection and estimation in regression with grouped variables.
[5] Taking Advantage of Sparsity in Multi-Task Learning http://arxiv.org/pdf/0903.1468
[6] A Dirty Model for Multi-task Learning. Advances in Neural Information Processing Systems https://papers.nips.cc/paper/4125-a-dirty-model-for-multi-task-learning.pdf
[7] Distributed Multi-task Relationship Learning http://arxiv.org/abs/1612.04022
[8] Regularized multi-task learning https://doi.org/10.1145/1014052.1014067
[9] Discovering Structure in Multiple Learning Tasks: The TC Algorithm http://scholar.google.com/scholar?cluster=956054018507723832&hl=en
[10] A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data.
[11] Empirical Bayes for Learning to Learn.
[12] Learning to learn with the informative vector machine https://doi.org/10.1145/1015330.1015382
[13] Task Clustering and Gating for Bayesian Multitask Learning https://doi.org/10.1162/153244304322765658
[14] Multi-Task Learning for Classification with Dirichlet Process Priors.
[15] Bayesian multitask learning with latent hierarchies http://dl.acm.org.sci-hub.io/citation.cfm?id=1795131
[16] Linear Algorithms for Online Multitask Classification.
[17] Learning with whom to share in multi-task feature learning.
[18] Learning Task Grouping and Overlap in Multi-task Learning.
[19] Learning Multiple Tasks Using Shared Hypotheses.
[20] Learning Multiple Tasks with Deep Relationship Networks http://arxiv.org/abs/1506.02117
[21] Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification http://arxiv.org/abs/1611.05377
[22] Cross-stitch Networks for Multi-task Learning https://doi.org/10.1109/CVPR.2016.433
[23] Deep multi-task learning with low level tasks supervised at lower layers.
[24] A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks http://arxiv.org/abs/1611.01587
[25] Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics http://arxiv.org/abs/1705.07115
[26] Deep Multi-task Representation Learning: A Tensor Factorisation Approach https://doi.org/10.1002/joe.20070
[27] Sluice networks: Learning what to share between loosely related tasks http://arxiv.org/abs/1705.08142
[28] Exploiting task relatedness for multiple task learning. Learning Theory and Kernel Machines https://doi.org/10.1007/978-3-540-45167-9_41
[29] When is multitask learning effective? Multitask learning for semantic sequence prediction under varying data conditions http://arxiv.org/abs/1612.02251
[30] Identifying beneficial task relations for multi-task learning in deep neural networks http://arxiv.org/abs/1702.08303
[31] Multitask learning using uncertainty to weigh losses for scene geometry and semantics.
Important! The Yizhen Natural Language Processing – Academic WeChat Group has been established
You can scan the QR code below to join the group for discussions.
Please modify your note to [School/Company + Name + Direction] when adding.
For example – HIT + Zhang San + Dialogue System.
We kindly ask business accounts to refrain from joining. Thank you!
Recommended Reading:
【Detailed Explanation】From Transformer to BERT Model
Sail Translation | Understanding Transformer from Scratch
Seeing is Believing! A Step-by-Step Guide to Building a Transformer with Python