
Nothing will work unless you do. ——Maya Angelou

Initial Thoughts
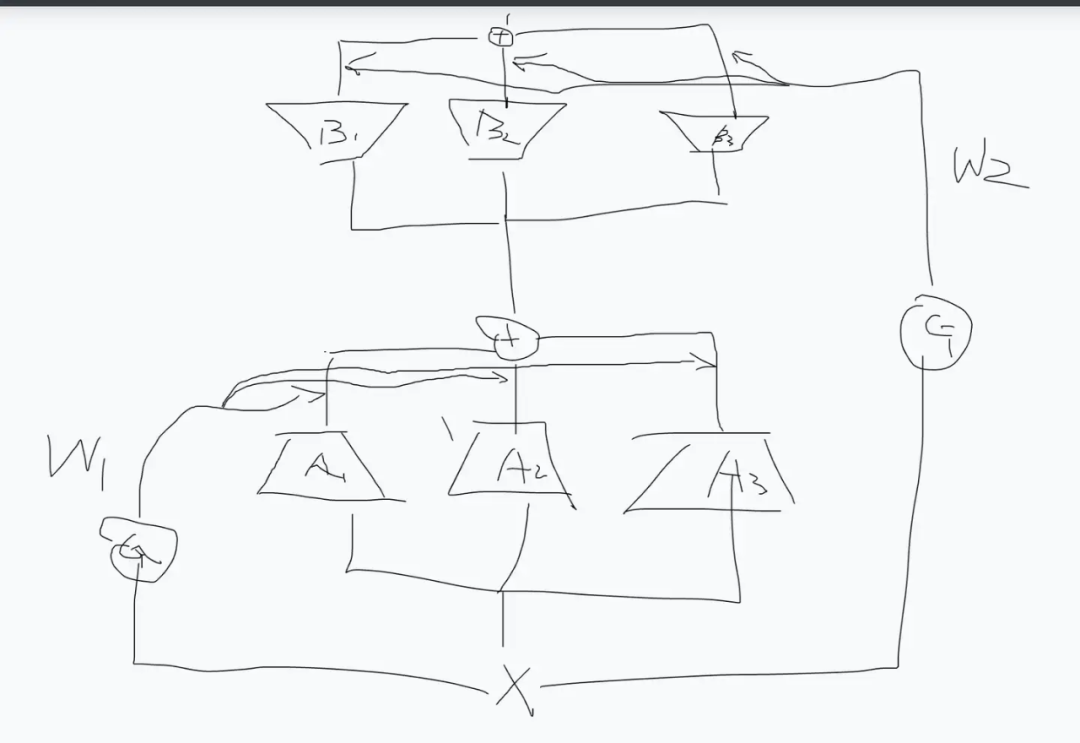
Removing the Gate, Going Directly
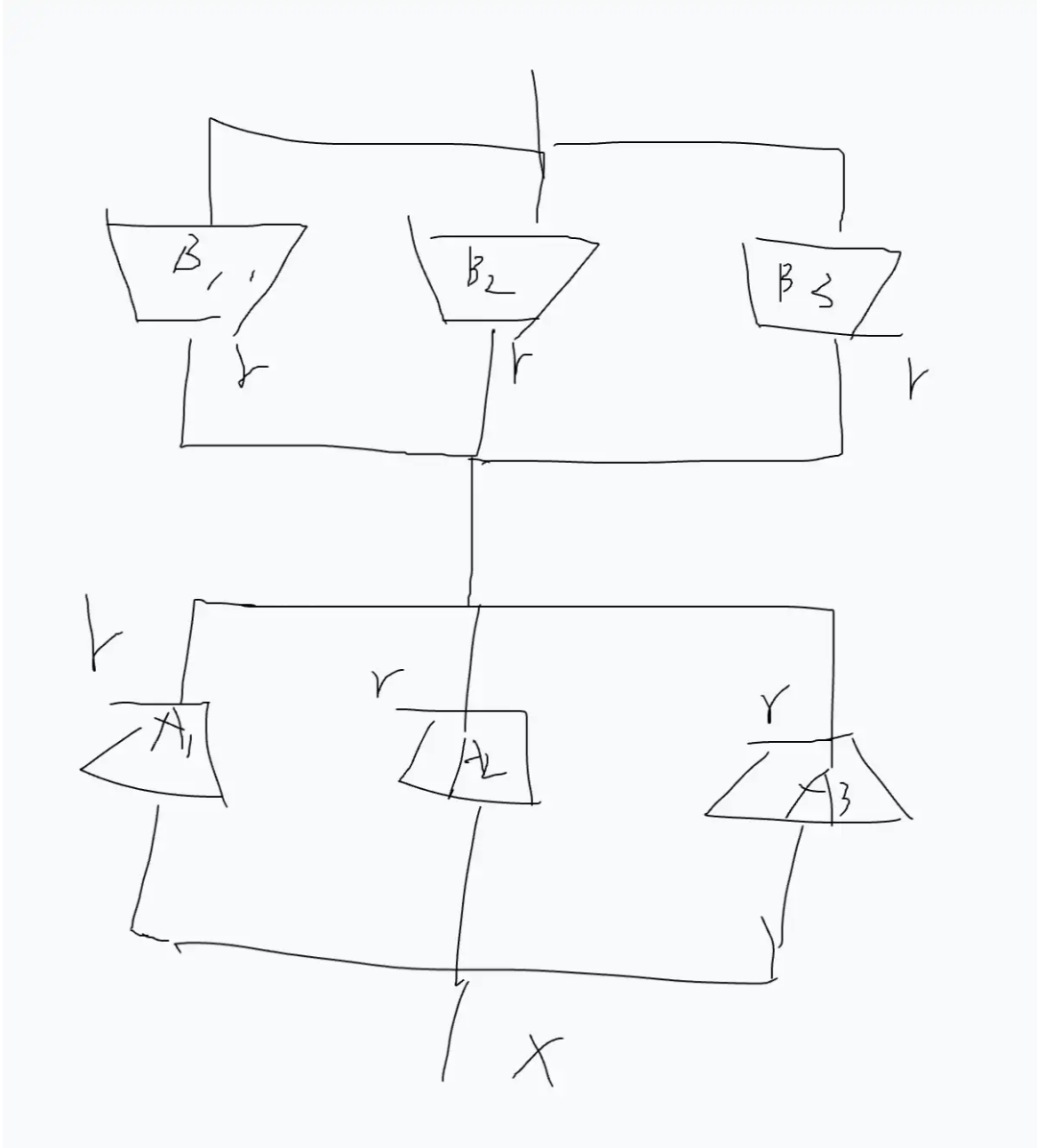
From the Perspective of ‘Multi-Head Attention’
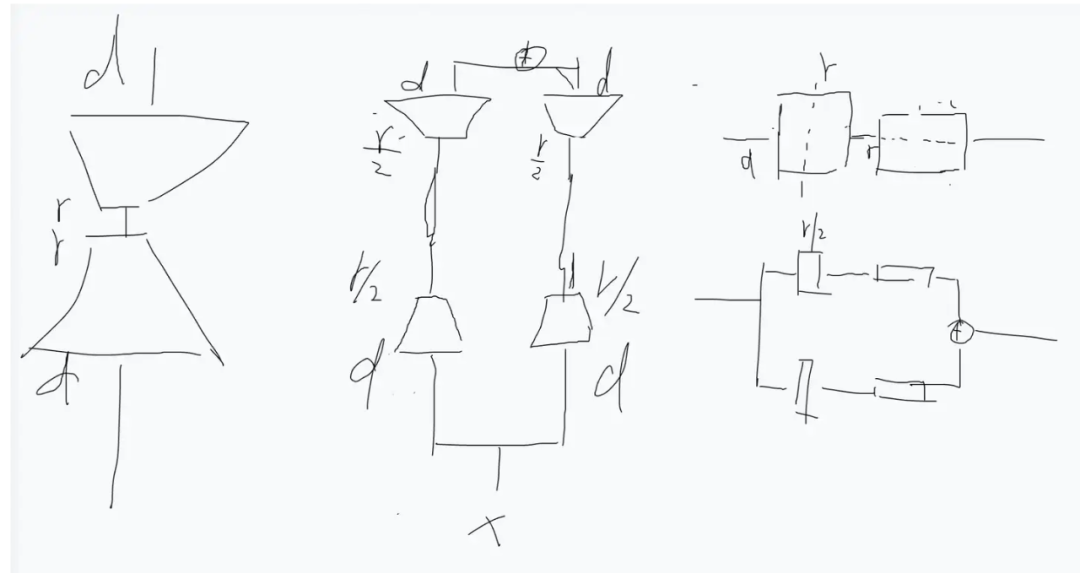
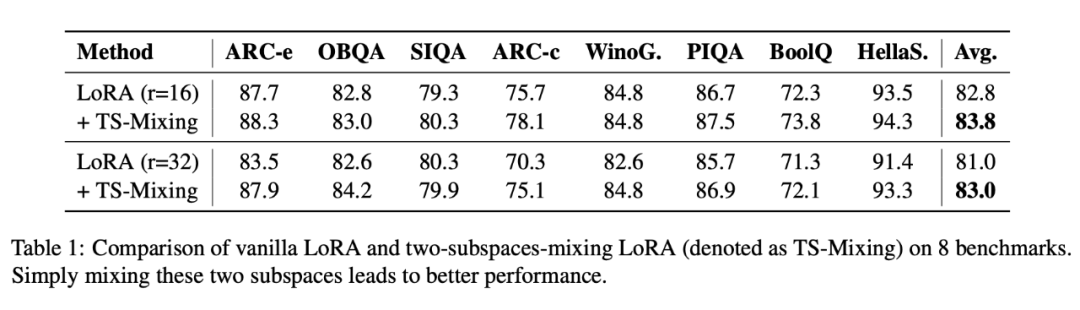

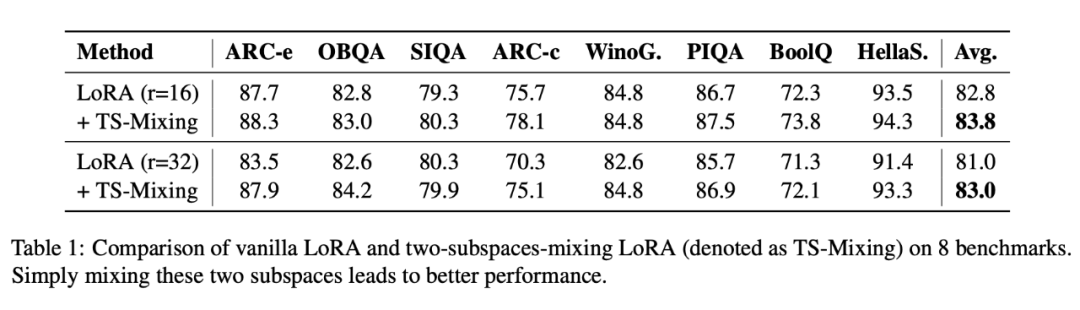
Phase Results, But Not Enough
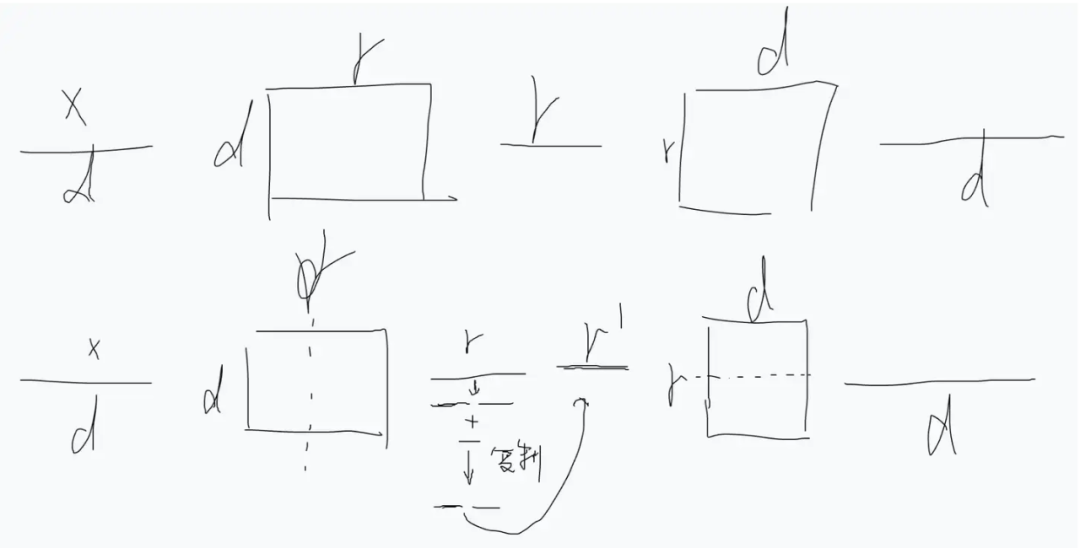
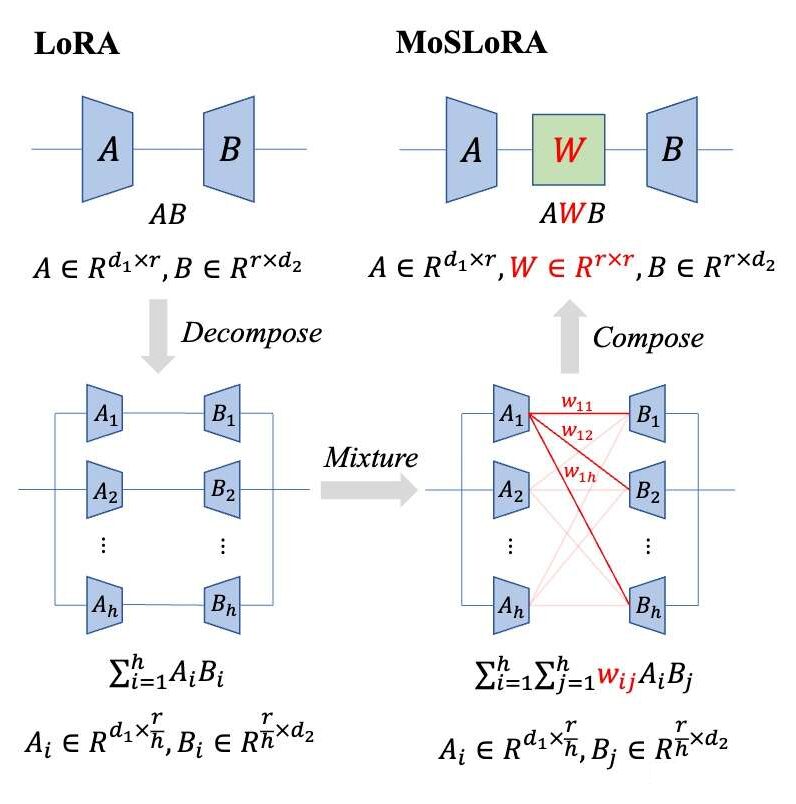
Introducing the Mixing Matrix
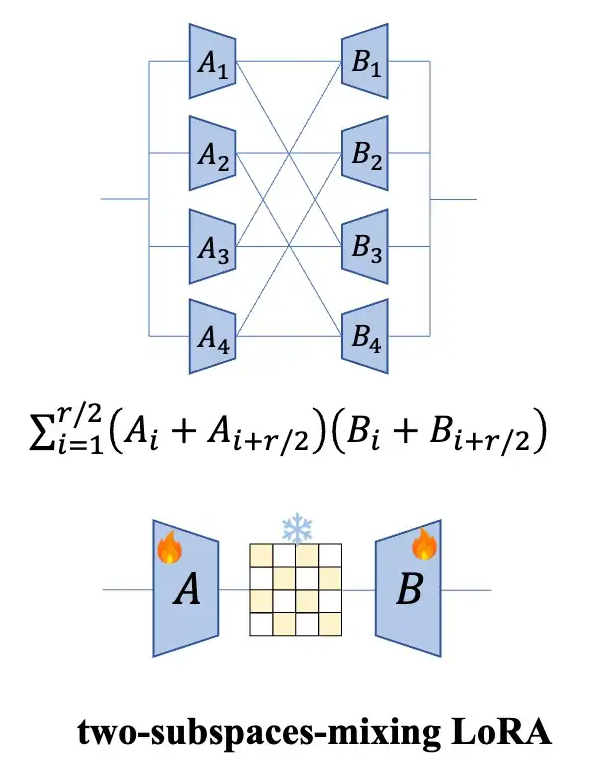
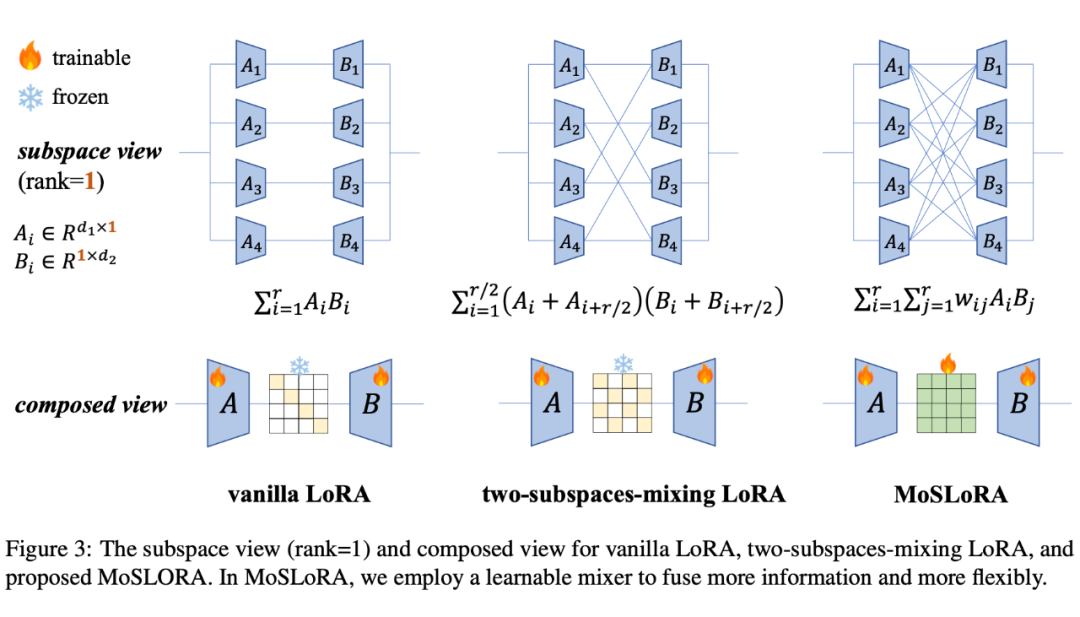
Note 1: This form is quite similar to AdaLoRA, but in AdaLoRA, the middle part is a feature value from SVD decomposition, and both front and back matrices have orthogonalization constraints added.
Note 2: While writing the paper, I discovered an excellent concurrent work on Arxiv: FLoRA: Low-Rank Core Space for N-dimension, which approaches the problem from the perspective of Tucker decomposition. Their thought process is clever and elegant; those interested can also check out their paper and interpretations.
Returning to the MoE Perspective
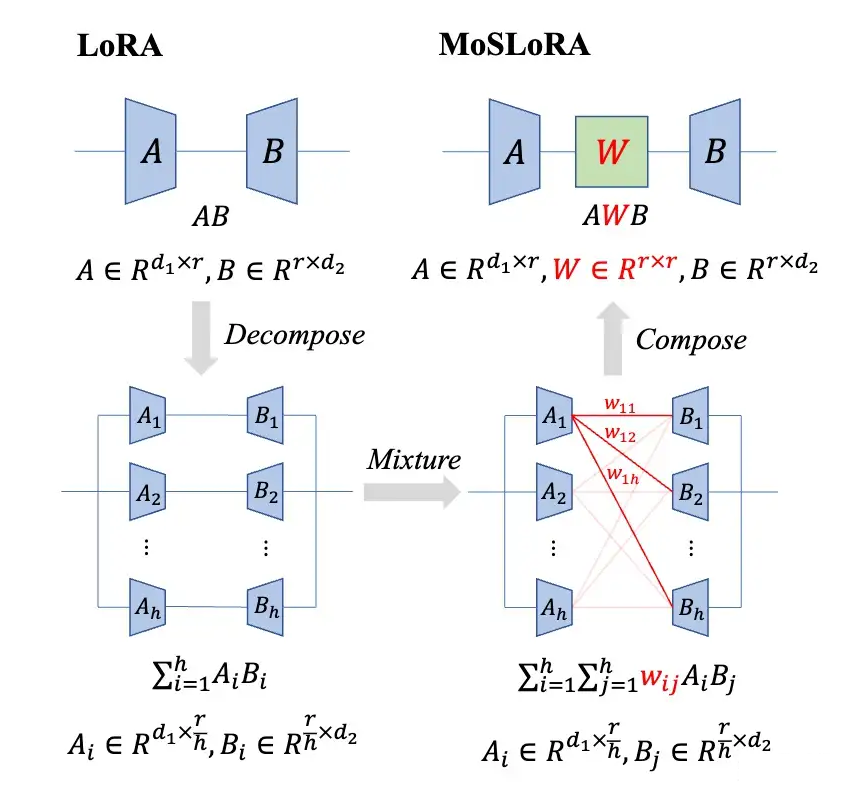
-
This weight is independent of the input, ensuring mergeability. -
This weight is dense, meaning all experts are utilized, rather than the top-k selection of MoE. -
The original vanilla LoRA can be viewed as having this Mixer matrix fixed to the identity matrix.
[Multiple parallel LoRA branches select top-k outputs and then sum] This conventional LoRA+MoE design essentially means the Mixer possesses: i) each row is the same element ii) some rows are all zero iii) non-zero rows’ elements are determined by the input iv) non-mergeable properties.
Postscript
Supplementary Proof
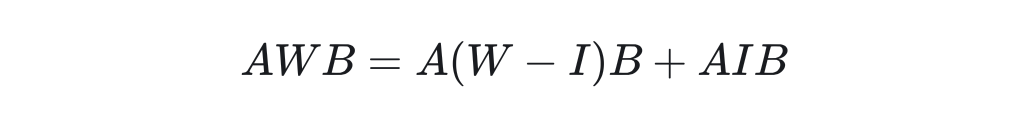


Scan the QR code to add the assistant WeChat
About Us
