
Abstract:
This article introduces a new approach for deploying large models, called LoRA, which reduces the number of parameters needed for model adaptation using low-rank matrices. Through a simple linear design, we can merge the trainable matrices with frozen weights during deployment, which does not introduce inference latency compared to fully fine-tuning the model.©️【Deep Blue AI】compiled

A significant paradigm in natural language processing is using general domain data to train large-scale pre-trained models and applying these pre-trained models to specific tasks and domains.
However, if we want to pre-train larger models and fully fine-tune them while retaining all model parameters, it becomes impractical. Taking the 175 billion parameter (175B) GPT-3 as an example, independently deploying the fine-tuned GPT-3 model while retaining all 175B parameters incurs enormous costs. This article proposes low-rank adaptation—LoRA, which involves freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the Transformer architecture, significantly reducing the number of training parameters for downstream tasks. Compared to fine-tuning GPT-3 with Adam, LoRA can reduce the parameter count by 10,000 times and decrease GPU memory requirements by three times. On RoBERTa, DeBERTa, GPT-2, and GPT-3, despite fewer trainable parameters, LoRA achieves higher training throughput, and unlike adapters, LoRA does not introduce additional inference latency, resulting in better model quality than fine-tuning.

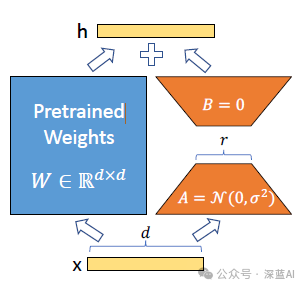
Many applications in natural language processing rely on adapting a large-scale pre-trained model by modifying the pre-trained weights for various downstream applications. This adaptation is often achieved through fine-tuning, which updates all parameters of the pre-trained model. One drawback of fine-tuning is that the new model retains the same number of parameters as the original model. As larger models need to be trained every few months, this is merely an inconvenience for models like GPT-2 or RoBERTa, but it poses a critical deployment challenge for GPT-3 with 175 billion trainable parameters.
Many solutions attempt to alleviate this issue by either reducing the number of parameters for fine-tuning or learning additional modules for new tasks. While these methods can significantly improve operational efficiency during deployment by storing and loading only a small number of task-specific parameters, they currently expand model depth or reduce the usable sequence length, leading to additional inference latency. More importantly, the quality of the deployed model obtained through these methods cannot reach the benchmark quality of the fine-tuned model, exposing the trade-off between efficiency and model quality.
This article is inspired by others’ research: learned over-parameterized models actually reside in lower intrinsic dimensions. We assume that the changes in weights during model adaptation also exhibit a low “intrinsic rank,” and thus we propose the low-rank adaptation (LoRA) method. LoRA allows us to indirectly train certain dense layers in neural networks by optimizing the rank decomposition matrices of dense network layers during the adaptation process while keeping the pre-trained weights frozen, as shown in Figure 1. Taking GPT-3 as an example, we find that even with a full rank (i.e., d) of up to 12,288, a very low rank (i.e., r in Figure 1, which can be 1 or 2) is sufficient, making LoRA both space-efficient and time-efficient.

Although our method is independent of the training objectives, we take language modeling as our incentive objective. Below we briefly introduce the language modeling problem, particularly the issue of maximizing conditional probabilities under specific task prompts.
Assuming we have a pre-trained autoregressive language model, using to parameterize it. For example, can represent a general multi-task learner like GPT, which is primarily based on the Transformer architecture. If we want to adapt this pre-trained model to downstream conditional text generation tasks, such as text summarization, machine reading comprehension (MRC), and natural language SQL (NL2SQL), each downstream task is represented by a dataset of text-target pairs:, where and are symbol sequences. For instance, in the NL2SQL task, is the natural language query sequence, while corresponds to the SQL command. In the text summarization case, is the content of an article, and is the summary of the article.
During full fine-tuning, the model is first initialized with pre-trained weights and then continuously repeats the operation of following the deep learning gradient updating method.
For any downstream task, there is a significant drawback when using the full fine-tuning mode. Specifically, we learn a different set of parameters, which has a dimension equal to. Therefore, if the pre-trained model is very large (e.g., GPT-3, which corresponds to), storing or deploying numerous instances of the fine-tuned model will be a huge challenge.
This article adopts a more efficient approach, where the parameter increments related to specific tasks are encoded by a smaller parameter set, here. Ultimately, the task of finding becomes the optimization of.

 ▲Figure 2|Relationship between adapters and sequence length ©️【Deep Blue AI】compiled
▲Figure 2|Relationship between adapters and sequence length ©️【Deep Blue AI】compiledThe problem we aim to solve is not novel; since the advent of self-transfer learning, dozens of studies have attempted to improve the parameter and computational efficiency of model adaptation. For instance, in language modeling, mainstream solutions adopt two strategies for efficient transformation: adding adapter layers or optimizing the form of input layer activations. However, these strategies have limitations, especially in large-scale and latency-sensitive production scenarios.
●Adapter layers introduce inference latency:There are currently many variants of adapters, and this article only discusses the original adapter design, which includes two adapter layers in each Transformer block, or one adapter layer and one layer normalization layer in each Transformer block. Although an adapter can reduce overall latency by pruning network layers or using a multi-task setting, there is no direct way to avoid additional computations in the adapter layers. However, the adapter layers have very few parameters, so the additional computations caused by the adapter layers are not a problem. However, large models use hardware parallelism to maintain low latency, and the adapter layers require sequential processing. Therefore, if running inference on a single GPU without hardware parallelism, for example, running GPT-2 with adapters will introduce significant latency.
In particular, when we need to contribute model weights, this issue becomes more severe because the additional weight computations require more GPU synchronization operations, such as AllReduce and Broadcast.
●Direct optimization of prompts is challenging:We observe that direct optimization of the model is very difficult, and its performance changes do not correspond to the training parameters. More fundamentally, if we want to retain a portion of the sequence for adaptation, we must reduce the length of the retained sequence to fit the downstream tasks, which leads to degraded performance of the adapted model.

This section mainly describes the design of LoRA and its actual impact. Although we focus only on weights in Transformer language models, the principles of LoRA can apply to any dense layer in deep learning models.
■5.1 Low-Rank Parameterized Update Matrices

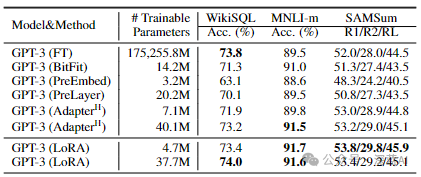
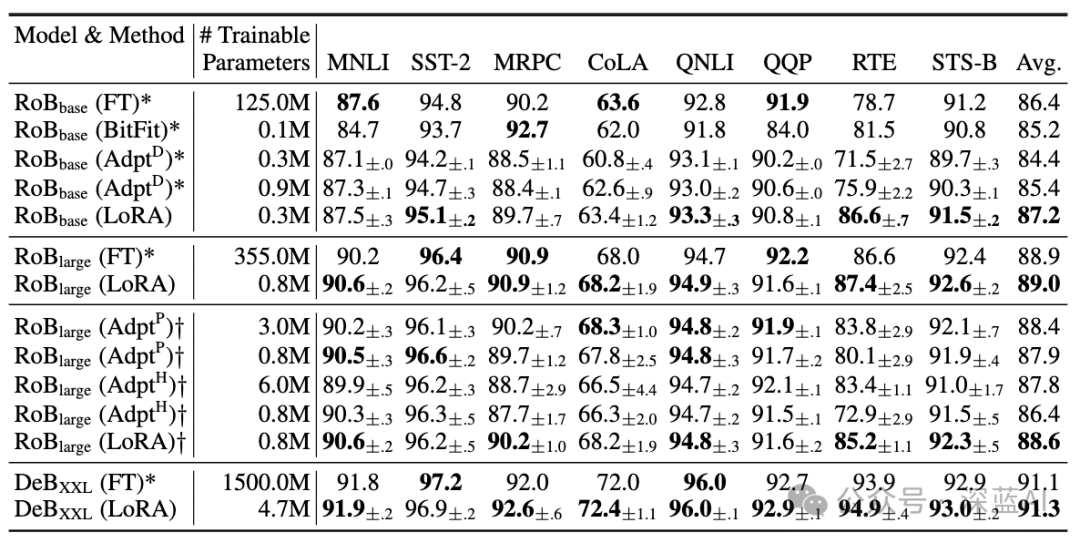
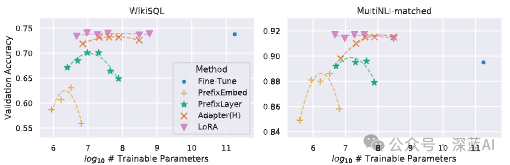
We used LoRA on RoBERTa, DeBERTa, and GPT-2 and adapted them to different downstream tasks, validating their performance results. Our experiments designed various tasks, from natural language understanding (NLU) to natural language generation (NLG). Notably, we validated RoBERTa and DeBERTa on the GLUE dataset.
■6.1 Baseline Comparison
To extensively compare the performance of different baseline networks, we reused relevant settings from previous work; however, this means that some baseline network experimental results are incomplete.
Fine-tuning is a common method for altering models. In the fine-tuning process, the model is first initialized with pre-trained model weights and biases, and then the parameters are continuously updated during training. A simple variant of this method is to only update a portion of the parameters while freezing others.
 ▲Figure 3|Experimental results of different adaptation methods ©️【Deep Blue AI】compiled
▲Figure 3|Experimental results of different adaptation methods ©️【Deep Blue AI】compiledBias-only or BitFit is a baseline network where we only train the bias vector of this network while freezing other parameters.
Prefix embedding fine-tuning (PreEmbed) inserts special identifiers into input labels. These special identifiers have trainable word embeddings and are generally not part of the model’s vocabulary, so where to insert these identifiers in the model can significantly impact performance. We use to denote the number of prefix identifiers, and the number of trainable parameters can be represented as.
Prefix layer fine-tuning (PreLayer) is an extension of prefix embedding fine-tuning. Instead of merely learning word embeddings for specific identifiers, we learn the activation values after each Transformer layer. The number of trainable parameters is represented as, where is the number of Transformer layers.
Adapter fine-tuning inserts adapter layers between the self-attention module and subsequent residual connections, where the adapter layers consist of two fully connected layers, and a non-linear operation is included between the fully connected layers; such adapter layers are called. Recently, a more efficient use of adapter layers is to add adapter layers after the multi-layer perceptron and a regularization layer, referred to as, in addition to and. In all cases, we can denote the adapter layers as, where is the number of adapter layers.
 ▲Figure 4|Experimental results of GPT-2 using different adaptation methods ©️【Deep Blue AI】compiled
▲Figure 4|Experimental results of GPT-2 using different adaptation methods ©️【Deep Blue AI】compiled■6.2 RoBERTa Base/Large
RoBERTa first proposed optimizations for pre-trained models in BERT, enhancing BERT’s performance without introducing excessive training parameters. Although RoBERTa is an older optimization technique, it still retains a significant advantage due to its parameter scale. To ensure relatively fair experimental comparisons, we made two changes to LoRA. First, we used the same batch size for all tasks and uniformly used a sequence length of 128. Second, we initialized different models using the original pre-trained model rather than using weights from a fine-tuned model.
■6.3 DeBERTa XXL
DeBERTa is a recent variant of BERT, trained on larger datasets and exhibiting superior performance. We conducted experiments comparing LoRA with DeBERTa, and the results indicate that LoRA has comparable performance.
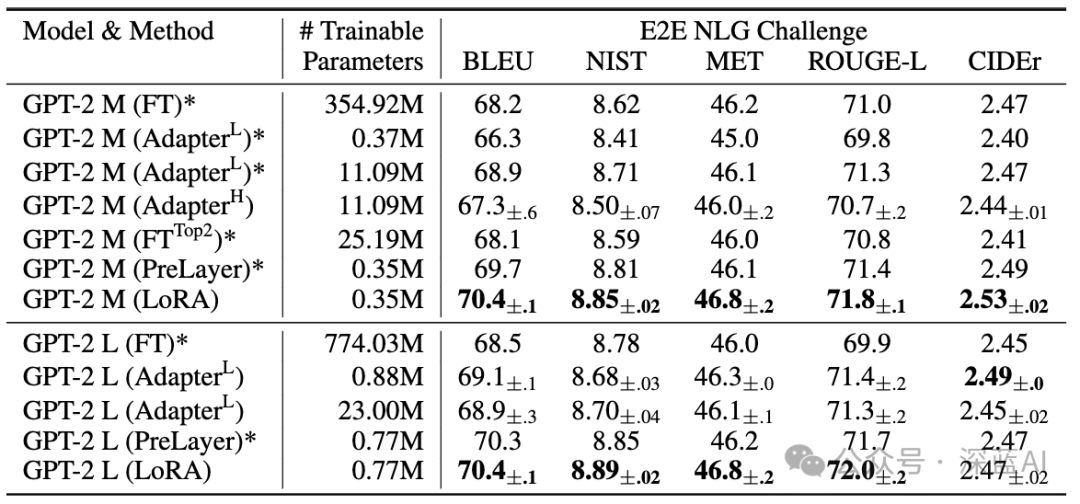
■6.4 GPT-2 Medium/Large
The aforementioned experiments demonstrate that LoRA performs excellently on general models, and we hope to know whether LoRA also excels on large models, such as GPT-2. Due to space constraints, we only present the results from the E2E competition, which indicate that LoRA maintains excellent performance advantages on large models.
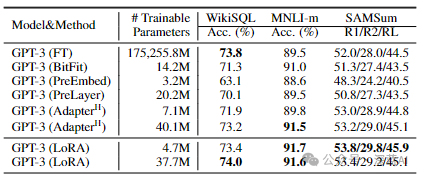
■6.5 Extending to GPT-3 175B
To further test the performance of LoRA, we conducted extended experiments on GPT-3 175B. Due to the enormous training costs, we only present typical standard deviation results for various tasks. As shown in Figure 5, LoRA outperformed the fine-tuning baseline model’s performance. We found that when we used more than 256 special identifiers, performance would drop.

Tuning large language models incurs high hardware costs and storage/switching costs for hosting independent instances for different tasks. The proposed LoRA is an efficient adaptation strategy that does not introduce inference latency, does not reduce input sequence length, and maintains high model quality. Importantly, it allows for quick task switching during deployment by sharing the vast majority of model parameters. While we focus on Transformer language models, the proposed method is also applicable to any neural network with dense layers.
