Abstract: The authors introduce a Multi-Modality Driven Low-Rank Adaptation (MMD-LoRA) method that utilizes low-rank adaptation matrices to achieve efficient fine-tuning from the source domain to the target domain, addressing the Adverse Condition Depth Estimation (ACDE) problem. It consists of two core components: Prompt-based Domain Alignment (PDDA) and Visual-Text Consistency Contrastive Learning (VTCCL). Through extensive experiments, this method highlights its robustness and efficiency in adapting to various adverse environments.
©️【Deep Blue AI】Compiled
Paper Link:https://arxiv.org/pdf/2412.20162

Autonomous driving systems aim to handle various real-world conditions. Among them, the main challenge is to solve numerous corner case scenarios where driving safety becomes crucial under adverse conditions (such as nighttime, fog, rain, and snow). These adverse conditions not only limit the vehicle’s ability to perceive the environment but also increase the risk of accidents, making robust depth estimation in such scenarios essential for safe autonomous driving.
One of the main difficulties in addressing this issue is the lack of high-quality real-world images from these adverse conditions, and collecting such data is a challenging task. Additionally, the high cost of annotating these real-world images makes it impractical to rely solely on traditional data collection and annotation methods. Thus, alternative methods are sought without the need for large-scale annotated data.
To this end, a technology for depth estimation under different adverse weather conditions (ACDE) has become a current research hotspot, estimating depth information under unseen weather conditions without relying on a large number of annotated samples. Although previous methods (such as md4all) have made significant progress, they primarily rely on generative models to convert images captured under clear weather into images representing adverse weather. However, these generative methods depend on sufficient target images to build well-trained models (e.g., ForkGAN). On the other hand, some methods utilize learnable parameters for feature enhancement to adapt to the target domain, resulting in increased model complexity and tuning efforts. Furthermore, unlike CLIP-based methods, depth estimation models lack sufficient alignment to match text and visual spaces, hindering coherent understanding under adverse conditions.
In this paper, the authors propose a new method: MMD-LoRA, which combines low-rank adaptation (LoRA) technology with contrastive learning to address the Adverse Condition Depth Estimation (ACDE) task. Specifically, by designing a Multi-Modality Driven Low-Rank Adaptation (MMD-LoRA), it aims to solve the domain gap from the source domain to the target domain as well as the misalignment between visual and textual representations. The core innovation of MMD-LoRA lies in two main components: Prompt-based Domain Alignment (PDDA) and Visual-Text Consistency Contrastive Learning (VTCCL).
The specific contributions are as follows:
-
The authors propose MMD-LoRA, a new ACDE method that effectively addresses domain gaps and multi-modal misalignment by combining low-rank adaptation (LoRA) technology with contrastive learning.
-
The authors also introduce Prompt-based Domain Alignment (PDDA), which employs a trainable low-rank adaptation matrix in the image encoder, guided by text embeddings. This component captures accurate target domain visual features without requiring additional target images. Meanwhile, Visual-Text Consistency Contrastive Learning (VTCCL) aims to achieve robust multi-modal alignment by separating embeddings of different weather conditions while bringing similar embeddings closer together, thus enhancing consistent representations.
-
Extensive experiments show that MMD-LoRA excels in depth estimation under adverse environmental conditions on two popular benchmarks (including the nuScenes dataset and the Oxford RobotCar dataset).
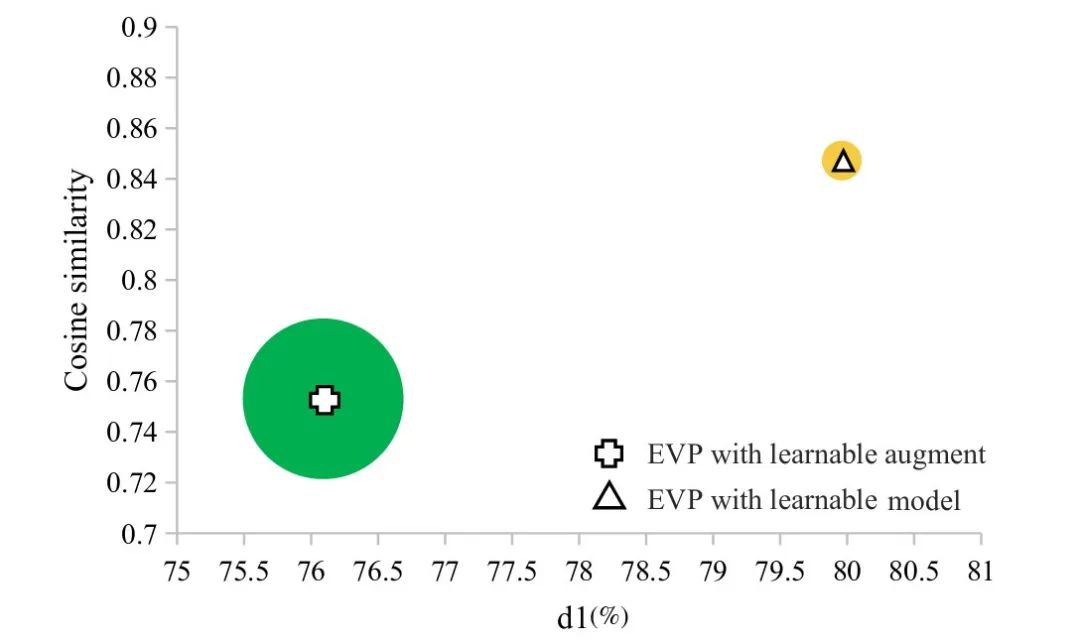
▲Figure 1 | Comparison of depth estimation results based on LoRA and enhancement methods ©️【Deep Blue AI】Compiled

■2.1. Depth Estimation Under Adverse Conditions
Adverse weather conditions can lead to measurement errors in LiDAR sensors, particularly due to reflections caused by water accumulation on roads during rainy days and the effects of non-textured areas under nighttime illumination.These factors hinder accurate depth estimation in pixel correspondences. So far, only a limited number of studies have explored depth estimation under adverse weather conditions.
Recently, progress in depth estimation under adverse weather conditions has been made through image enhancement-based methods and style transfer-based methods. These image enhancement-based methods focus solely on addressing issues related to inadequate lighting and reflections. However, these methods often fail to establish a unified framework to provide more robust and general solutions. To address this limitation, style transfer-based methods have been proposed to construct a unified framework that addresses various adverse weather conditions. For instance, md4all diversifies source domain images by utilizing generative models like ForkGAN to convert images captured under clear weather into images depicting adverse weather. Similarly, Fabio et al. utilized advanced text-to-image diffusion models to generate new user-defined scenes and their associated depth information.
■2.2. Zero-Shot Depth Estimation
Zero-shot depth estimation is a significant challenge task that requires effectively generalizing a depth estimator trained on source domain images to unknown target domains during inference.For example, Zoedepth achieved impressive generalization performance by pre-training on multiple datasets, combining relative and metric depth, and using a lightweight decoder to fine-tune the model with metric depth information. Ranftl et al. proposed a robust training objective invariant to depth range and scaling variations by combining data from different sources to improve generalization performance. Recently, Depth Anything improved the model’s generalization ability by expanding the training set to approximately 62 million images. Despite these efforts enhancing zero-shot inference capabilities, there remains an urgent need for more high-quality synthetic real-world images.
■2.3. Multi-Modal Alignment Strategy
Multi-modal alignment enhances the model’s scene perception ability and captures fine-grained representations of real-world scenes.For instance, Alec Radford et al. pioneered the use of natural language as a supervisory signal for image representations, achieving alignment between visual and textual encoders. Yu et al. developed an instance-language matching network that uses visual prompts learning and cross-attention within the CLIP backbone to facilitate the matching of instance and text embeddings. Zhou et al. introduced pseudo-labeling and self-training processes to achieve pixel-text alignment for semantic segmentation tasks in the absence of annotations.
Unlike these pre-aligned CLIP-based methods, depth estimation models lack sufficient alignment between multi-modal features, hindering coherent understanding under adverse conditions. The misalignment between text encoders and image encoders inevitably undermines LoRA’s generalization ability under adverse conditions, leading to suboptimal results.

■3.1. Prompt-Driven Domain Alignment
■3.2. Visual-Text Consistency Contrastive Learning
■3.3. Training Architecture
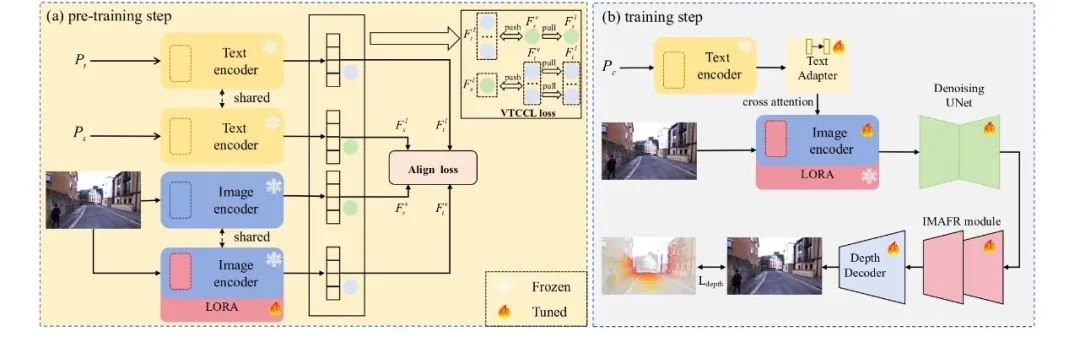
▲Figure 2 | Overview of MMD-LoRA framework process ©️【Deep Blue AI】Compiled

■4.1. Datasets and Evaluation Metrics
The experimental datasets are: nuScenes and Oxford RobotCar. For the nuScenes dataset, it is a challenging large-scale dataset containing 1000 scenes with diverse weather conditions and LiDAR data. The authors adopt the partition recommended by md4all, which includes 15129 training images and 6019 validation images. It is noteworthy that the training images only include clear daytime images without adverse weather images, while the validation images are divided into clear, nighttime, and daytime rainy conditions. For the Oxford RobotCar dataset, it contains a mix of daytime and nighttime scenes. The authors similarly adopt the partition recommended by md4all, which includes 16563 training images (including clear weather and excluding nighttime weather) and 1411 validation images (including clear weather and nighttime weather).
■4.2. Experimental Details
MMD-LoRA is trained through PDDA and VTCCL during the pre-training step. The benchmark depth estimator (i.e., EVP) is trained using frozen MMD-LoRA during the training step. In the pre-training step, images are randomly cropped into 15 batches of 400 × 400, with a base learning rate set to 0.001, using the AdamW optimizer to train MMD-LoRA for 4000 iterations with a batch size of 4. The weight types are then set to Wq, Wk, Wv, Wproj, and the rank r=8 is set in MMD-LoRA to adapt to the unseen target domain (i.e., adverse weather). In VTCCL, the weight coefficients are set as λ0: λ1: λ2 = 1:0.1:1 for the nuScenes dataset, while λ0: λ1 = 1:0.05 for the Oxford RobotCar dataset, as the contrastive learning weight coefficients under different weather conditions. During the training step, the EVP depth estimator is chosen as the benchmark, while the other training settings in the MMD-LoRA method adopt the settings in EVP.
■4.3. Experimental Comparisons
The comparison results on the nuScenes dataset are shown in Table 1. The MMD-LoRA method outperforms all previous methods, achieving the best results on most metrics. Compared to the recent state-of-the-art method md4all-DD, the MMD-LoRA method shows significant advantages. For instance, under clear weather conditions, MMD-LoRA surpassed previous state-of-the-art methods by 8.43% (from 88.03% to 96.46%), improved by 4.63% at nighttime (from 75.33% to 79.96%), and increased by 12.55% under rainy conditions (from 82.82% to 95.37%). These comparison results demonstrate the effectiveness of MMD-LoRA. Unlike the works of md4all and Fabio et al., which rely on generative models to convert clear weather conditions into adverse weather and further capture target domain visual representations, MMD-LoRA becomes more direct and robust in capturing target domain visual features. As shown in Figure 3, the MMD-LoRA method is capable of identifying key elements of scenes under nighttime and clear weather conditions, with a higher degree of distinction between adjacent objects or the same objects. For example, MMD-LoRA correctly captures the entire obstacle, clearly distinguishing between two columns and recovering the “hole” in the car.

▲Table 1 | Comparison of experimental results on nuScenes©️【Deep Blue AI】Compiled

▲Figure 3 | Qualitative experimental results comparison (nuScenes)©️【Deep Blue AI】Compiled
To demonstrate the robustness of MMD-LoRA, the performance of MMD-LoRA was evaluated on the RobotCar dataset. The results are shown in Table 2, where MMD-LoRA also surpasses all previous methods. Compared to previous state-of-the-art methods, the MMD-LoRA method successfully improved d1 during the day from 87.17% to 92.56%, and during the night from 83.68% to 89.33%. As shown in Figure 4, MMD-LoRA clearly estimates the depth of standing pillars and heads in nighttime and clear weather images in the first and second rows. The comparisons on the RobotCar dataset further validate the effectiveness of MMD-LoRA in depth estimation under adverse conditions. Tables 1 and 2 also show that MMD-LoRA can obtain visual representations in real scenarios during rainy days and nighttime, which are robust to any unseen target domains.
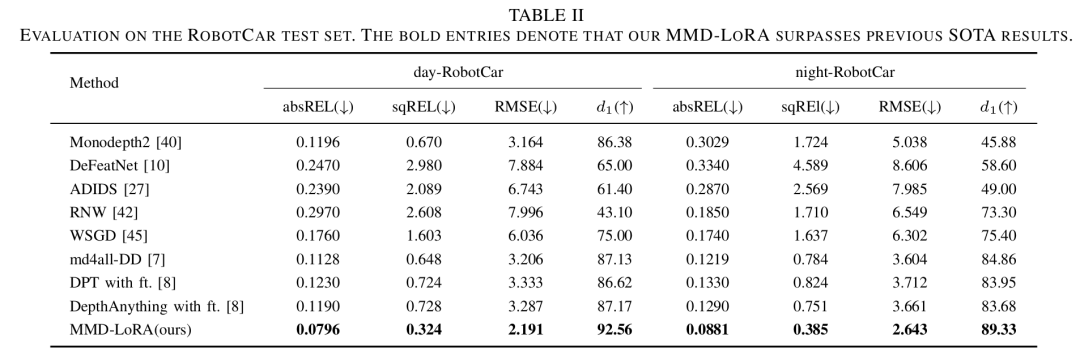
▲Table 2 | Comparison of experimental results on RobotCars©️【Deep Blue AI】Compiled
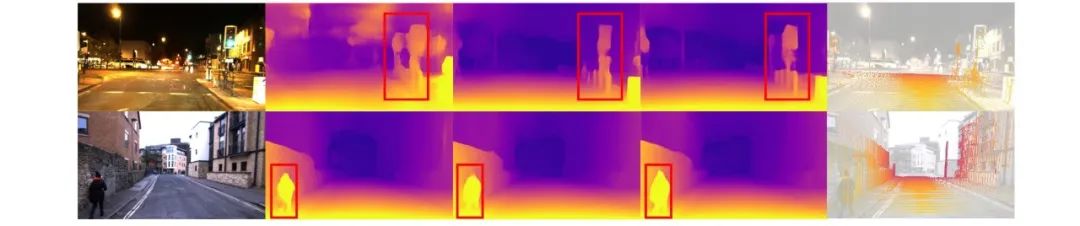
▲Figure 4 | Qualitative experimental results comparison (Robotcar)©️【Deep Blue AI】Compiled
■4.4. Ablation Experiments
As shown in Table 3, although EVP performs well under adverse conditions, the performance of MMD-LoRA with PDDA still surpasses EVP by 0.39% and 5.97% in d1 during daytime and nighttime, respectively. The reason for this improvement lies in the fact that MMD-LoRA with PDDA can indeed capture the visual features of the target domain without additional target domain images. As shown in the second and third columns of Figure 5, EVP tends to produce depth artifacts when estimating the depth of object boundaries. Compared to EVP, MMD-LoRA with PDDA achieves clear boundaries and eliminates background noise. Additionally, by introducing VTCCL into MMD-LoRA, MMD-LoRA achieves 96.46% in d1, and the error remains comparable or significantly improved compared to using PDDA alone. This is because VTCCL achieves robust multi-modal alignment, enhancing consistent representations.
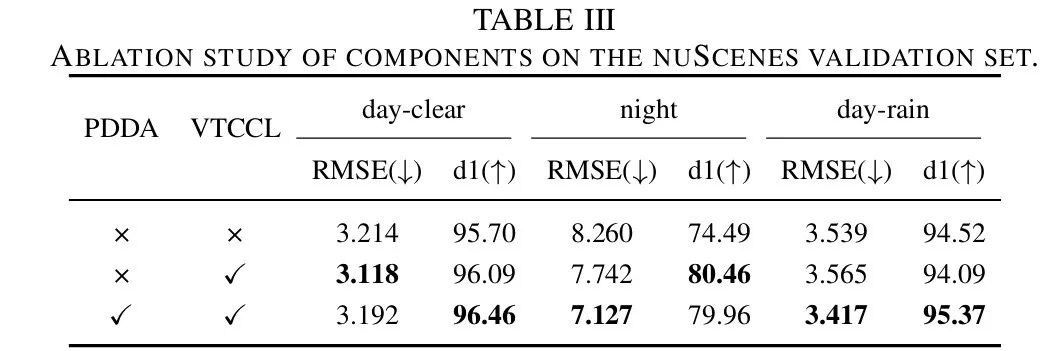
▲Table 3 | Ablation experimental results comparison (nuScenes)©️【Deep Blue AI】Compiled
As shown in the third and fourth columns of Figure 5, VTCCL further achieves clearer contours and pixel-level accurate depth estimation, with clear object boundaries (e.g., tree boundaries, complete trucks), and produces depth artifacts as indicated by the red boxes.

▲Figure 5 | Ablation experimental results of MMD-LoRA with PDDA and VTCCL©️【Deep Blue AI】Compiled
As shown in Table 4, the performance of learning-based enhancement methods and learning-based model methods (i.e., MMD-LoRA) in depth estimation under adverse conditions. While learning-based enhancement methods and learning-based model methods brought improvements of 1.60% and 5.47% at nighttime, and 0.22% and 0.85% under daytime rainy conditions, both significantly exceeded the baseline. Compared to learnable enhancement methods, learning-based model methods achieved superior depth estimation performance with almost no increase in the number of parameters (only an increase of 0.035M). The authors conducted ablation experiments to find the suitable rank r for the specific layers of self-attention in the image encoder. Table 5 shows the comparison of depth estimation performance using different ranks r. When the rank r is set to 8, MMD-LoRA achieves excellent d1 and comparable error metrics, performing well as r gradually increases. Notably, depth estimation performance does not always improve by increasing the rank r. This can be explained by the fact that setting a larger threshold r > 8 may lead to overfitting of the predicted unseen target domain representations to the corresponding text descriptions, deviating from the features in the real world.
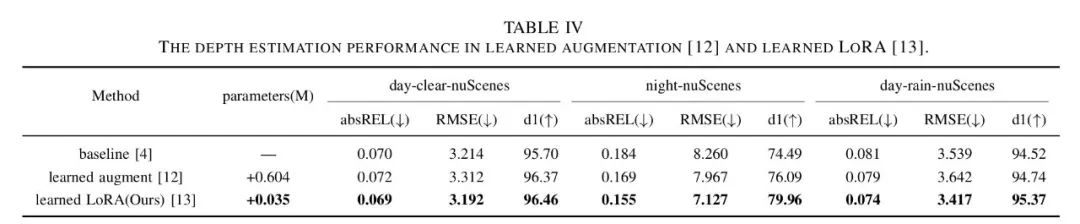
▲Table 4 | Comparison of depth estimation results between enhancement and LoRA©️【Deep Blue AI】Compiled
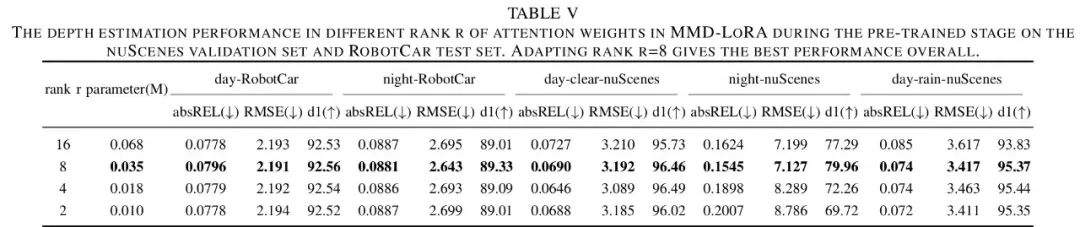
▲Table 5 | Comparison of depth estimation results under different r values©️【Deep Blue AI】Compiled

In conclusion, existing adverse condition depth estimation methods often require additional target images and depth estimators, but they fail to achieve sufficient alignment between multi-modal features. The authors propose the MMD-LoRA method, which addresses these limitations through parameter-efficient fine-tuning techniques and contrastive learning paradigms. Specifically, Prompt-based Domain Alignment (PDDA) effectively captures visual features from unseen target domains using a trainable low-rank adaptation matrix guided by text embeddings. Subsequently, Visual-Text Consistency Contrastive Learning (VTCCL) separates embeddings of different weather conditions while pulling similar embeddings closer together, ensuring robust multi-modal alignment and enhancing MMD-LoRA’s generalization ability in diverse adverse scenarios. Comprehensive quantitative and qualitative experiments validate the effectiveness of MMD-LoRA. Future work will explore extending this method to video-based applications.
However, the MMD-LoRA method relies on predefined text descriptions for the source and target domains, which is assumed to be known in most applications. Additionally, the experiments assume consistent brightness during clear weather, even under adverse weather conditions (e.g., rainfall during rainy days or visibility at nighttime). This assumption may not hold under slight variations in weather conditions.
Multi-Modality Driven LoRA for Adverse Condition Depth Estimation
Compiled by
Translated by|Babata
Reviewed by|apr
· Planned cycle: Deep Blue Academy will establish a “community of like-minded individuals” for engineers & academic researchers every 3 months
· Coverage direction: Robotics (bipedal, quadrupedal, robotic arms), embodied intelligence, end-to-end, autonomous driving, large models, drones, visual CV, medical AI……16 popular fields
· Sharing content: Regular weekly sharing in the group including but not limited to industry dynamics, interview questions, cutting-edge academic papers, recruitment opportunities……
Scan to add Alang, and choose the discussion group you want to join
(Invitations will be sent in the order of submission, please choose as soon as possible)
👇

Discussion group see👋🏻
Revealing Netflix’s latest technology: Seeing sound, generating images from audio!
Domestic robots are too competitive! The world’s first explosion-proof robot, the fastest “machine beast” is born……