Abstract——The rapid development of foundational models——large-scale neural networks trained on diverse and extensive datasets——has revolutionized artificial intelligence, driving unprecedented advancements in fields such as natural language processing, computer vision, and scientific discovery. However, the enormous parameter counts of these models, often reaching billions or even trillions, pose significant challenges in adapting them to specific downstream tasks. Low-Rank Adaptation (LoRA), as a very promising method, has become an effective means to alleviate these challenges, providing a parameter-efficient mechanism to fine-tune foundational models with minimal computational overhead. This review comprehensively examines low-rank adaptation technology for the first time, covering not only research on large-scale language models but also its applications in foundational models, encompassing the technical foundations, cutting-edge advancements, and applications of low-rank adaptation in various fields. Finally, this paper discusses key challenges and future research directions regarding theoretical understanding, scalability, and robustness. This review provides valuable resources for scholars and practitioners engaged in efficient foundational model adaptation research and practice.
Keywords——Foundational models, large-scale language models, low-rank adaptation, parameter-efficient fine-tuning, multi-task learning
Foundational models represent a paradigm shift in artificial intelligence, where large-scale neural network architectures pretrained on extensive and diverse datasets establish a generalizable representation framework that can adapt to a wide range of downstream applications [1], [2]. These models span multiple domains, including natural language processing (e.g., GPT-3.5 [3], LLaMA [4]), computer vision (e.g., Swin Transformer [5], MAE [6], SAM [7]), speech processing (e.g., Wav2vec2 [8], Whisper [9]), multimodal learning (e.g., Stable Diffusion [10], DALL·E 2 [11]), and scientific applications (e.g., AlphaFold [12], ChemBERTa [13], ESM-2 [14]).
The hallmark of foundational models is their unprecedented scale, with parameter counts reaching billions or even trillions, and they exhibit emergent properties—abilities that arise spontaneously without explicit training [1]. These architectures have become fundamental building blocks of modern AI systems, driving breakthrough advancements across multiple domains [1], [2]. Despite these models showcasing extensive capabilities, fine-tuning for task-specific optimization remains a necessary means to enhance model generalization [15], promote algorithmic fairness [16], achieve customization [17], and adhere to ethical and societal standards [18], [19]. However, their scale brings significant computational challenges, particularly regarding the computational resources required for training and fine-tuning [20].
Although traditional fine-tuning methods (which involve updating all parameters) have proven effective across various tasks [21], [22], their computational demands often render their application in foundational models impractical [23], [24]. Consequently, Parameter-Efficient Fine-Tuning (PEFT) methods have emerged as solutions to address these computational challenges [17], [24], [25], [26], [27], [28]. These methods significantly reduce computational demands without sacrificing task performance by minimizing the number of trainable parameters. Among these methods, Low-Rank Adaptation (LoRA) [17] and its variants have garnered widespread attention due to their simplicity, empirical effectiveness, and broad applicability across various model architectures and domains, as illustrated in Figure 1.
LoRA is based on two key insights: during fine-tuning, weight updates typically reside in a low-dimensional subspace [29], [30], and task-specific adaptations can be effectively captured through low-rank matrices [17]. By optimizing these low-rank matrices while freezing the original model parameters, LoRA achieves efficient adaptation and can combine multiple task-specific adaptations without increasing inference latency [17], [31].
Contributions. This review provides the first comprehensive examination of LoRA technology beyond the realm of large-scale language models (LLMs) [32], extending the analysis to a broader field of foundational models. Our primary contributions include:
Abstract——The rapid development of foundational models——large-scale neural networks trained on diverse and extensive datasets——has revolutionized artificial intelligence, driving unprecedented advancements in fields such as natural language processing, computer vision, and scientific discovery. However, the enormous parameter counts of these models, often reaching billions or even trillions, pose significant challenges in adapting them to specific downstream tasks. Low-Rank Adaptation (LoRA), as a very promising method, has become an effective means to alleviate these challenges, providing a parameter-efficient mechanism to fine-tune foundational models with minimal computational overhead. This review comprehensively examines low-rank adaptation technology for the first time, covering not only research on large-scale language models but also its applications in foundational models, encompassing the technical foundations, cutting-edge advancements, and applications of low-rank adaptation in various fields. Finally, this paper discusses key challenges and future research directions regarding theoretical understanding, scalability, and robustness. This review provides valuable resources for scholars and practitioners engaged in efficient foundational model adaptation research and practice.
Keywords——Foundational models, large-scale language models, low-rank adaptation, parameter-efficient fine-tuning, multi-task learning
Foundational models represent a paradigm shift in artificial intelligence, where large-scale neural network architectures pretrained on extensive and diverse datasets establish a generalizable representation framework that can adapt to a wide range of downstream applications [1], [2]. These models span multiple domains, including natural language processing (e.g., GPT-3.5 [3], LLaMA [4]), computer vision (e.g., Swin Transformer [5], MAE [6], SAM [7]), speech processing (e.g., Wav2vec2 [8], Whisper [9]), multimodal learning (e.g., Stable Diffusion [10], DALL·E 2 [11]), and scientific applications (e.g., AlphaFold [12], ChemBERTa [13], ESM-2 [14]).
The hallmark of foundational models is their unprecedented scale, with parameter counts reaching billions or even trillions, and they exhibit emergent properties—abilities that arise spontaneously without explicit training [1]. These architectures have become fundamental building blocks of modern AI systems, driving breakthrough advancements across multiple domains [1], [2]. Despite these models showcasing extensive capabilities, fine-tuning for task-specific optimization remains a necessary means to enhance model generalization [15], promote algorithmic fairness [16], achieve customization [17], and adhere to ethical and societal standards [18], [19]. However, their scale brings significant computational challenges, particularly regarding the computational resources required for training and fine-tuning [20].
Although traditional fine-tuning methods (which involve updating all parameters) have proven effective across various tasks [21], [22], their computational demands often render their application in foundational models impractical [23], [24]. Consequently, Parameter-Efficient Fine-Tuning (PEFT) methods have emerged as solutions to address these computational challenges [17], [24], [25], [26], [27], [28]. These methods significantly reduce computational demands without sacrificing task performance by minimizing the number of trainable parameters. Among these methods, Low-Rank Adaptation (LoRA) [17] and its variants have garnered widespread attention due to their simplicity, empirical effectiveness, and broad applicability across various model architectures and domains, as illustrated in Figure 1.
LoRA is based on two key insights: during fine-tuning, weight updates typically reside in a low-dimensional subspace [29], [30], and task-specific adaptations can be effectively captured through low-rank matrices [17]. By optimizing these low-rank matrices while freezing the original model parameters, LoRA achieves efficient adaptation and can combine multiple task-specific adaptations without increasing inference latency [17], [31].
Contributions. This review provides the first comprehensive examination of LoRA technology beyond the realm of large-scale language models (LLMs) [32], extending the analysis to a broader field of foundational models. Our primary contributions include:
-
Systematic Analysis of Technical Foundations: We provide a structured analysis of recent technical advancements in LoRA, including parameter-efficient strategies, rank adaptation mechanisms, training process improvements, and emerging theoretical perspectives.
-
Extensive Survey of Emerging Frontiers: We explore emerging research frontiers, including advanced architectures that integrate multiple LoRA components and expert mixture methods, as well as approaches for continual learning, forgetting, federated learning, long-sequence modeling, and efficient service infrastructures.
-
Comprehensive Review of Applications: We present a review of practical applications across multiple domains, including natural language processing, computer vision, speech recognition, scientific discovery, as well as specialized applications in code engineering, recommendation systems, graph learning, and spatiotemporal prediction.
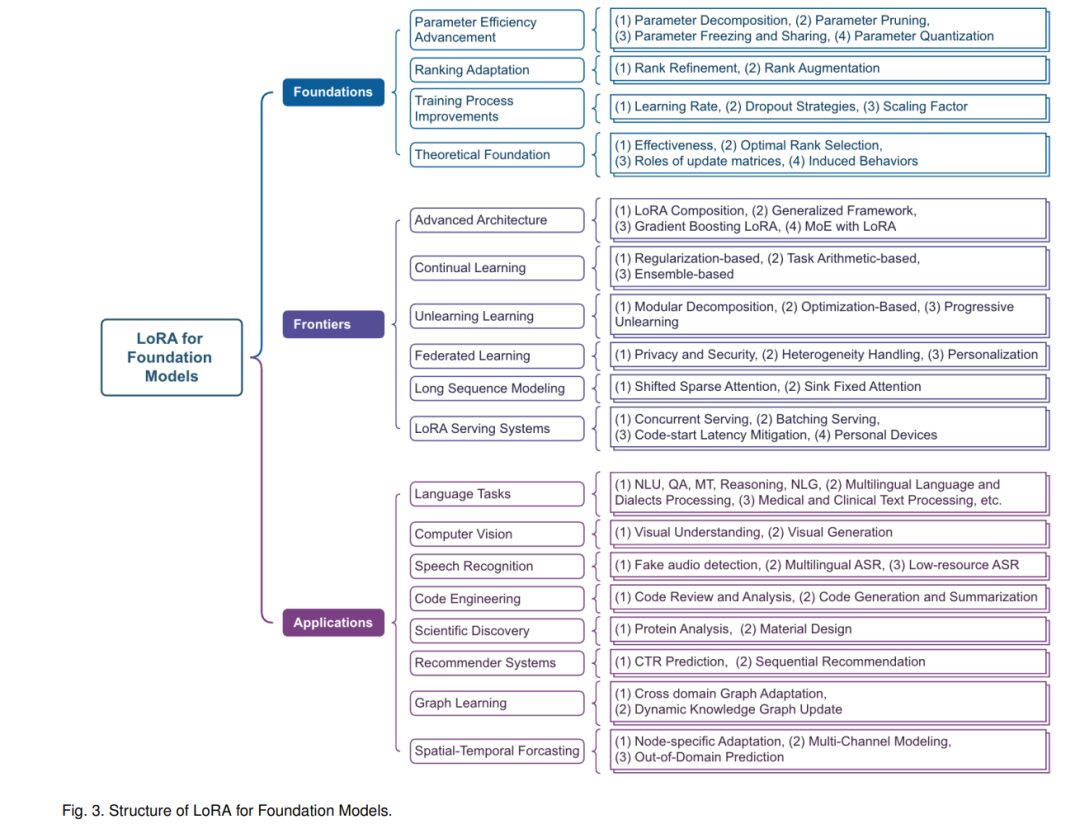
This review organizes existing LoRA research through Figure 3, identifying key challenges and future research directions in Section 6, providing valuable resources for researchers and practitioners in this field.
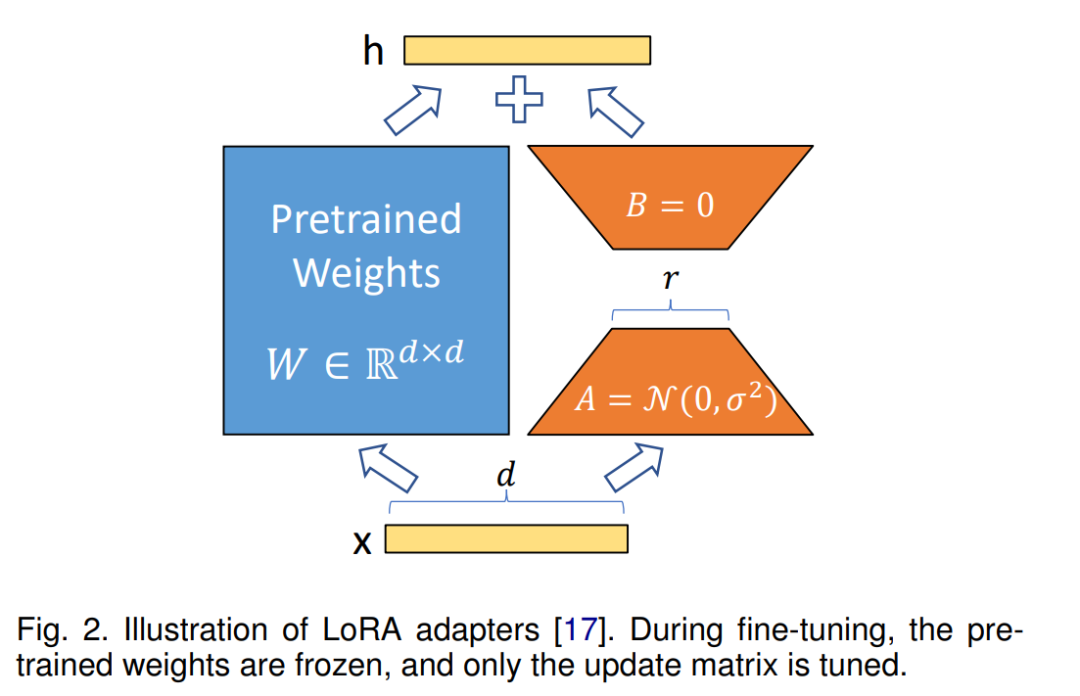
LoRA [17] is a significant advancement in the field of parameter-efficient fine-tuning (PEFT). Although originally developed for large-scale language models (LLMs), subsequent research has demonstrated its excellent performance across various foundational models. The core idea of LoRA’s mathematical formulation is to constrain the update matrix ∆W to be low-rank during fine-tuning, as illustrated in Figure 2, achieved through matrix decomposition:
Parameter Initialization Strategy LoRA employs specific initialization strategies to ensure training stability and efficiency. Matrix A is typically initialized with values drawn from a random Gaussian distribution, while matrix B is initialized to zero, ensuring that at the start of training, ∆W = BA is effectively a zero matrix.
Fine-Tuning Process In LoRA, the fine-tuning process follows these key principles:
-
The original pretrained weights W₀ are kept frozen and do not receive gradient updates during training.
-
The low-rank matrices A and B are the only trainable parameters used to capture task-specific adjustments.
-
W₀ and ∆W act on the input vector x, combining their outputs.
-
The output ∆W x is scaled by α/r.
-
The final output vector is summed element-wise:

where α/r is a scaling factor used to control the magnitude of low-rank updates. When using Adam [33] optimization, adjusting the scaling factor α is roughly equivalent to adjusting the learning rate [17], provided that appropriate scaling is done at initialization. In practice, the value of α can be set according to the rank r, thus eliminating the need for extensive hyperparameter tuning.
Advantages of LoRA Compared to Full Fine-Tuning LoRA provides several key advantages when applied to large-scale foundational models compared to full fine-tuning:
-
Parameter Efficiency: LoRA introduces a minimal set of trainable parameters through low-rank decomposition, typically reducing the number of task-specific parameters by several orders of magnitude. This approach is particularly beneficial in resource-constrained environments and multi-task scenarios where multiple adaptations of the foundational model are needed.
-
Enhanced Training Efficiency: Unlike traditional full fine-tuning, which updates all model parameters, LoRA only optimizes the low-rank adaptation matrices. This significantly reduces computational costs and memory requirements, especially in models with billions of parameters. The reduced parameter space often leads to faster convergence during training.
-
No Inference Latency: LoRA does not introduce additional inference latency, as the update matrix ∆W can be explicitly combined with the original frozen weights W. This integration ensures that the adapted model remains efficient during deployment and inference.
-
Flexible Modular Adaptation: LoRA enables the creation of lightweight, task-specific adapters that can be interchanged without modifying the foundational model architecture. This modularity facilitates efficient multi-task learning and task switching, significantly reducing storage requirements compared to maintaining independent model instances for each task.
-
Robust Knowledge Retention: By retaining the pretrained weights, LoRA effectively mitigates the problem of catastrophic forgetting, a common challenge in traditional fine-tuning. This approach allows for the acquisition of task-specific capabilities while preserving the foundational knowledge of the model.
-
Diverse Deployment Options: The compactness of LoRA adaptations aids in efficient deployment and system integration. Multiple adapters can be conveniently combined or switched between different tasks or domains, offering greater flexibility compared to traditional fine-tuning methods.
In this section, we will explore the fundamental technical aspects of LoRA from four key dimensions: parameter efficiency enhancement, rank adaptation strategy, training process improvements, and theoretical foundations. These components constitute the technical foundation of LoRA’s effectiveness.
3.1 Parameter Efficiency Enhancement
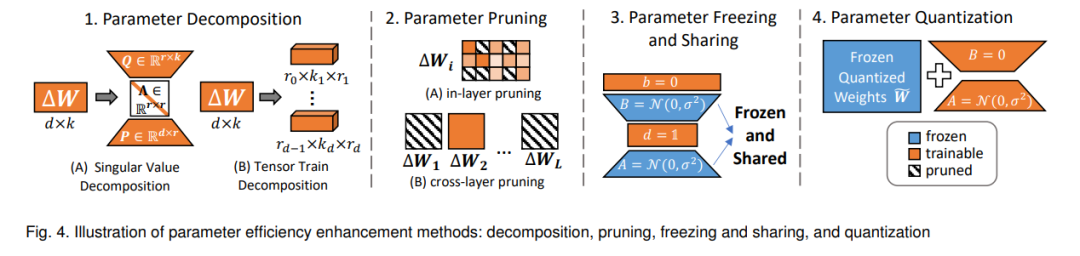
Although LoRA and its projection matrices A (project-down) and B (project-up) achieve parameter efficiency, the method still requires a significant number of trainable parameters. For instance, applying LoRA to the LLaMA-2-70B model [4] necessitates updating over 16 million parameters [34], a figure that exceeds the total parameter count of some BERT architectures [35]. Current research addresses this challenge through four main methods: parameter decomposition, pruning, freezing and sharing, and quantization. Figure 4 illustrates examples of these techniques.
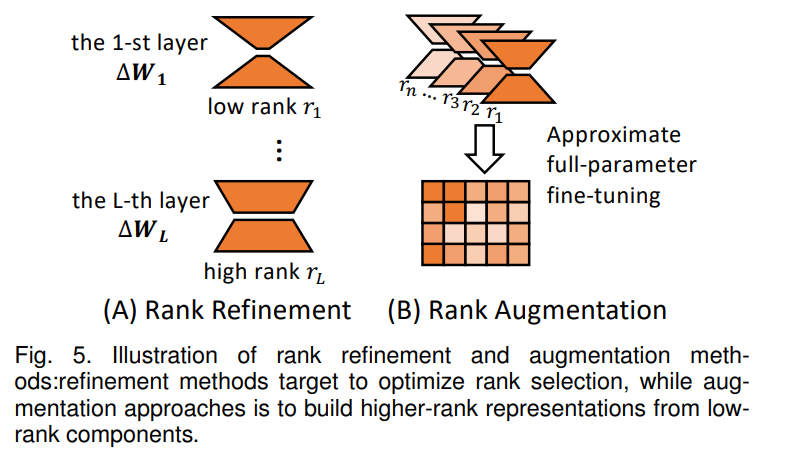
 Rank is a key parameter in LoRA that directly affects the model’s adaptability and the number of trainable parameters. The original LoRA method employs a fixed low rank across all layers, which may not be optimal for different downstream tasks and model architectures. To address these limitations, recent research has proposed various methods to optimize rank allocation in LoRA, broadly categorized into two main aspects: rank refinement and rank enhancement. Figure 5 illustrates these two methods.
3.3 Training Process Improvements
Although LoRA has achieved significant success in parameter-efficient fine-tuning, optimizing its training dynamics remains crucial for maximizing adaptation performance. In this section, we will discuss recent advancements aimed at improving the training process, particularly regarding learning rates, dropout strategies, and scaling factors.
Rank is a key parameter in LoRA that directly affects the model’s adaptability and the number of trainable parameters. The original LoRA method employs a fixed low rank across all layers, which may not be optimal for different downstream tasks and model architectures. To address these limitations, recent research has proposed various methods to optimize rank allocation in LoRA, broadly categorized into two main aspects: rank refinement and rank enhancement. Figure 5 illustrates these two methods.
3.3 Training Process Improvements
Although LoRA has achieved significant success in parameter-efficient fine-tuning, optimizing its training dynamics remains crucial for maximizing adaptation performance. In this section, we will discuss recent advancements aimed at improving the training process, particularly regarding learning rates, dropout strategies, and scaling factors.
4 Cutting-Edge Developments
Building on the technical foundations mentioned above, this section explores cutting-edge developments that extend the capabilities of LoRA. These developments leverage and combine the fundamental principles of LoRA to achieve new functionalities, tackle more complex tasks, and address challenges in model adaptation.
4.1 Advanced Architectures
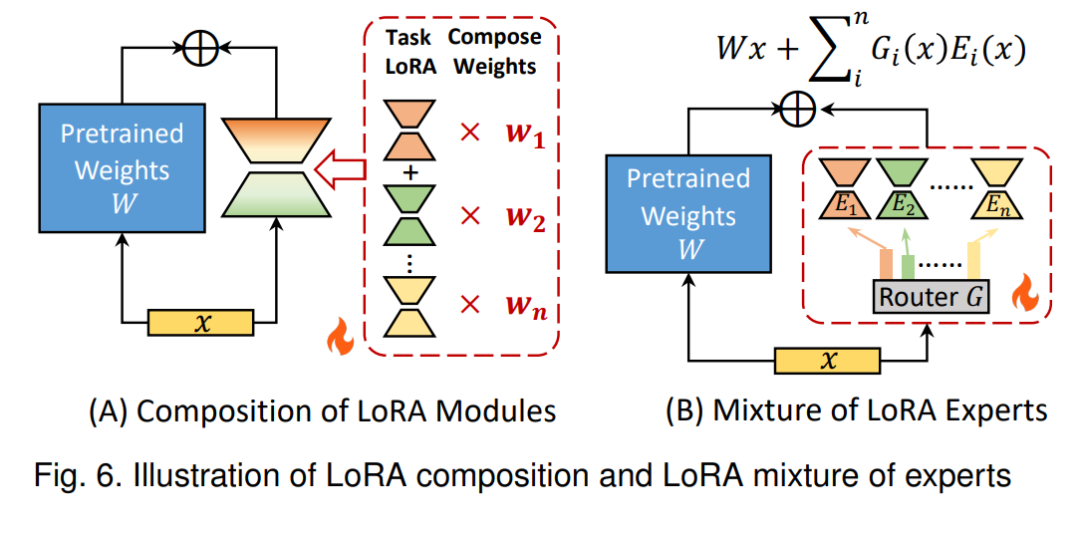
Although the original LoRA method significantly improves fine-tuning efficiency and demonstrates performance comparable to full fine-tuning, it has limitations in flexibility, generalization, and handling diverse tasks simultaneously. To address these limitations, researchers have developed advanced LoRA architectures to further enhance performance, parameter efficiency, and generalization capabilities.
4.2 Application of LoRA in Continual Learning
The parameter-efficient characteristics of LoRA make it possible to incrementally update models on new tasks while effectively mitigating the problem of catastrophic forgetting [98], [99]. There are several key advantages to using LoRA for continual learning (CL): (1) reduced computational costs compared to full fine-tuning; (2) natural isolation of task-specific knowledge; (3) flexible combination of task-specific adaptations. Existing continual learning methods based on LoRA can be broadly categorized into three approaches: regularization methods, task arithmetic methods, and ensemble methods.
4.3 Application of LoRA in Forgetting
LoRA enables targeted removal of specific knowledge from foundational models without extensive retraining. Here are three main categorized methods for achieving forgetting using LoRA:
-
Modular Decomposition Methods: Achieve localized adjustments or removals of specific knowledge by modularizing the adaptation components of the model without affecting overall performance.
-
Optimization-Based Methods: Remove or forget specific knowledge by optimizing particular parameters or subsets, with the optimization process typically focusing on reducing the influence related to specific tasks.
-
Progressive Forgetting Pipelines: Gradually update the model’s knowledge base to incrementally remove unnecessary knowledge during the model training process while ensuring stability and performance.
4.4 Application of LoRA in Federated Learning
In an era where data privacy issues are increasingly pressing, Federated Learning (FL) offers a promising approach to leverage collective knowledge while protecting individual data privacy. The combination of LoRA with Federated Foundation Models (FFM) makes foundational models more accessible on resource-constrained devices, particularly in edge computing scenarios, with the potential to revolutionize the Internet of Things (IoT) and mobile applications.
4.5 Application of LoRA in Long Sequence Modeling
The ability to handle long sequences is crucial for many tasks processed by foundational models【125】【126】【127】. However, standard foundational models are often limited by maximum context lengths due to the quadratic computational complexity of self-attention mechanisms relative to sequence length. To address this limitation, several LoRA-based methods have been proposed to extend the context window of foundational models.
Efficiently serving multiple LoRA models is equally critical. Recent advancements include improved GPU memory management [129], efficient batching techniques [130], CPU-assisted strategies to mitigate cold-start delays [131], and adaptive methods for resource-constrained personal devices [132].
The effectiveness and efficiency of LoRA in fine-tuning foundational models have led to its widespread application across various domains, including language processing, computer vision, speech recognition, multimodal, code engineering, scientific discovery, recommendation systems, graph learning, and spatiotemporal prediction.
In this review, we conducted a systematic analysis of LoRA, exploring its theoretical foundations, technical advancements, and various applications in adapting foundational models. The widespread application of LoRA across multiple domains—from natural language processing and computer vision to speech recognition and scientific computing—highlights its versatility and effectiveness. LoRA enables significant reductions in computational and storage demands while maintaining model performance, making it particularly valuable for adaptations in resource-constrained environments and specific domains.
Despite these achievements, several key challenges remain. The theoretical framework for LoRA’s effectiveness needs further development, especially in understanding the interactions between low-rank adaptation and model capabilities. Additionally, issues regarding scalability, robustness, and secure deployment in production environments remain important directions for current research.
For convenient access to specialized knowledge, visit the link below or click the bottom “Read Original”
https://www.zhuanzhi.ai/vip/9c3500ea31d6183df496f79afdf172ff

Click “Read Original” to view and download this article