Introduction
LoRA (Low-Rank Adaptation of Large Language Models) is a very practical fine-tuning framework for large models. Before the emergence of LoRA, I used to manually modify parameters, optimizers, or layer counts to “refine” models, which was extremely blind. However, the LoRA technique allows for quick fine-tuning of parameters. If the results after LoRA fine-tuning are unsatisfactory, one can switch to modifying the optimizer or module instead. Adjusting parameters is the most labor-intensive step, and since the parameters of large models are counted in the hundreds of millions, manually tuning them becomes quite impractical. LoRA provides a solution to this problem!
LoRA achieves model fine-tuning by training only low-rank matrices and then injecting these parameters into the original model. This method not only reduces computational requirements but also significantly decreases the training resources needed compared to directly training the original model, making it very suitable for use in resource-limited environments.
Mainstream Fine-Tuning Methods
Currently, mainstream low-cost fine-tuning methods for large models include Adapter Tuning proposed by Houlsby et al. in 2019, LoRA proposed by Microsoft in 2021, Prefix-Tuning proposed by Stanford, Prompt Tuning proposed by Google, and P-tuning v2 proposed by Tsinghua University in 2022.
LoRA outperforms several other methods. Each of the other methods has its own issues:
-
Adapter Tuning increases the model’s layer count, introducing additional inference latency.
-
Prefix-Tuning is difficult to train, and the reserved sequence for prompts occupies the input sequence space for downstream tasks, affecting model performance.
-
P-tuning v2 easily leads to the forgetting of old knowledge, with the fine-tuned model performing significantly worse on previous tasks.
LoRA’s Starting Point
Fine-tuning large-scale language models for specific domains and tasks is one of the important topics in natural language processing. However, as the scale of models continues to grow, the feasibility of fine-tuning all parameters (full fine-tuning) becomes increasingly low. Taking GPT-3’s 175 billion parameters as an example, every time a new domain is added, a new model needs to be fully fine-tuned, which is costly and resource-intensive.
Features of LoRA
-
Advantages: Low training and computational costs, parallelizable, does not introduce inference latency.
-
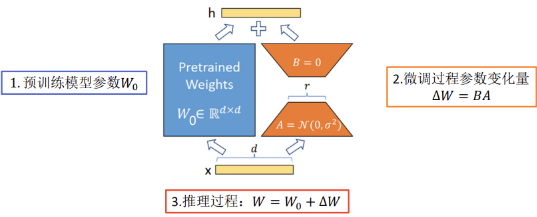
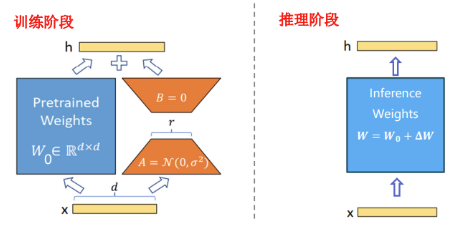
A parallel low-rank branch is introduced next to each transformer block, with the branch’s input being the input of the transformer block. The outputs are then added to the outputs of the transformer block, allowing the branch to learn task-specific knowledge while keeping the main pretrained model parameters fixed, thus completing specific tasks.
Motivation
-
LoRA adjusts a small number of parameters without changing the model’s inference structure.
-
The change in parameters ΔW is usually redundant, and low-rank approximation can express it well.
-
Highly versatile, can fine-tune linear layers in any model.
Algorithm Process

Experimental Conclusions
The LORA paper experiments show
Compared to Other Fine-Tuning Methods
-
LoRA increases the parameter count without causing performance degradation.
-
Performance is on par with or even exceeds that of full parameter fine-tuning.
Rank Selection
Experimental results indicate that for general tasks, r=1,2,4,8 is sufficient. However, for tasks with significant domain differences, a larger r may be required.
Additionally, increasing the r value does not necessarily enhance fine-tuning effectiveness, which may be due to the increased parameter count requiring more data.
Hands-On Practice
Currently, LoRA has been integrated into the PEFT (Parameter-Efficient Fine-Tuning) codebase by HuggingFace. LoRA fine-tuning requires setting two parameters: one is r, which is the matrix rank, and alpha, which is a scale parameter.
pip install peftBy using the get_peft_model to wrap the base model and PEFT configuration, the model is prepared for training using PEFT methods (such as LoRA). For the bigscience-mt0-large model, only 0.19% of the parameters need to be trained!
from transformers import AutoModelForSeq2SeqLMfrom peft import get_peft_config, get_peft_model, LoraConfig, TaskTypemodel_name_or_path = "bigscience/mt0-large"tokenizer_name_or_path = "bigscience/mt0-large"peft_config = LoraConfig( task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)model = get_peft_model(model, peft_config)model.print_trainable_parameters()The result is as follows:
"trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"As you can see, only 0.19% of the parameters need to be trained.
Loading a PEFT Model for Inference:
from peft import AutoPeftModelForCausalLMfrom transformers import AutoTokenizerimport torchmodel = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora").to("cuda")tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")model.eval()inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])Result:
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."Extension: Differences Between QLoRA and LoRA
The performance comparison between QLoRA and LoRA usually depends on multiple factors, including task type, dataset, model architecture, hardware environment, etc. Here are some possible aspects of performance comparison:
Parameter Count and Training Efficiency
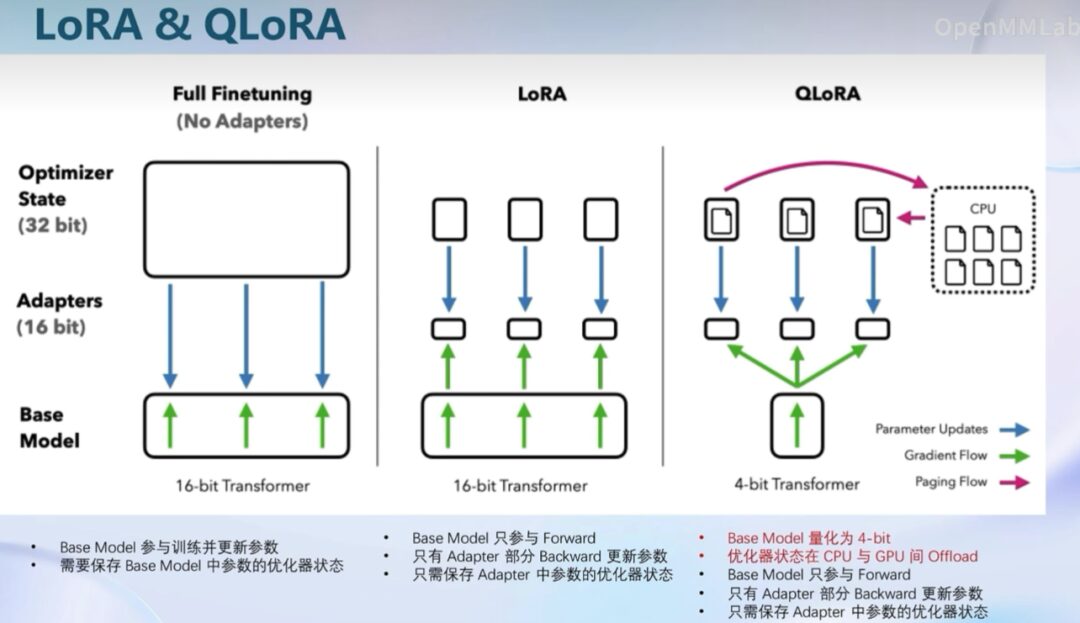
LoRA: By using low-rank matrices, LoRA significantly reduces the number of parameters that need to be fine-tuned, which typically means faster training speeds and lower memory requirements.
QLoRA: Further reduces parameter size through quantization, so on the same hardware, QLoRA may offer higher training efficiency, especially in resource-constrained environments.
“Parameter quantization” refers to the process in machine learning and deep learning of converting model parameters (typically weights and biases) from floating-point numbers (such as 32-bit floats) to lower-precision representations, such as 16-bit, 8-bit, or even fewer bits. The main purpose of this is to reduce the model’s storage requirements and computational complexity, thereby improving the model’s operational efficiency on hardware, especially on hardware that does not support or is not adept at handling floating-point operations.
Parameter quantization can bring the following benefits:
1. Reduced Model Size: Quantized models occupy less storage space, making them easier to deploy on resource-constrained devices.
2. Lower Computational Costs: Quantized models require less computational power during computation, reducing energy consumption and improving processing speed.
3. Improved Hardware Compatibility: Quantized models can run more efficiently on hardware that does not support floating-point operations.
However, parameter quantization may also present some challenges, such as a decrease in model accuracy, as the quantization process may lead to information loss. Therefore, quantization techniques need to find a balance between model efficiency and accuracy.
Accuracy and Model Performance
LoRA: Maintains floating-point precision, typically providing performance comparable to or close to full model fine-tuning, especially when the parameters are fewer and the task is similar to the original pre-training task.
QLoRA: Quantization may introduce some accuracy loss, which could lead to a slight drop in model performance. However, this loss is usually minimal, especially when using 4-bit or higher quantization.
Inference Speed and Resource Consumption
LoRA: During inference, LoRA can improve inference speed and reduce resource consumption due to the reduced number of parameters.
QLoRA: Due to parameter quantization, QLoRA may be even more efficient during inference, especially on hardware that does not support floating-point operations or where floating-point operations are less efficient.
Specific Performance Comparison
On Standard Hardware: The performance of LoRA and QLoRA may be very close, but QLoRA may have an advantage on hardware that uses low-precision operations.
On Mobile or Embedded Devices: QLoRA typically outperforms LoRA, as it is more suitable for resource-constrained environments.
On Specific Tasks: For certain tasks, quantization may have a minimal impact on model performance, so QLoRA may achieve performance close to or even matching that of LoRA.
Considerations in Practical Applications
Training Time: QLoRA may further reduce training time, especially when training on CPU or low-power hardware.
Model Size: Models generated by QLoRA are typically smaller, making them more suitable for deployment in storage-constrained environments.
Ease of Use: LoRA may be easier to implement and deploy, as it does not require handling the complexities introduced by quantization. When deciding between using QLoRA or LoRA, the best practice is to experiment for specific tasks and hardware environments to determine which method offers the best resource efficiency while maintaining the required performance. Generally, both QLoRA and LoRA are effective techniques that can be chosen based on specific needs.
Imagine you have a huge toy, and now you want to modify this huge toy. However, making comprehensive changes to the entire toy would be very expensive.
① Therefore, you find a method called LoRA: only modify certain parts of the toy instead of making comprehensive changes to the entire toy.
② QLoRA is an improvement of LoRA: if all you have is a rusty screwdriver, you can still modify your toy.
Extension: Flash Attention and DeepSpeed ZeRO
Flash Attention
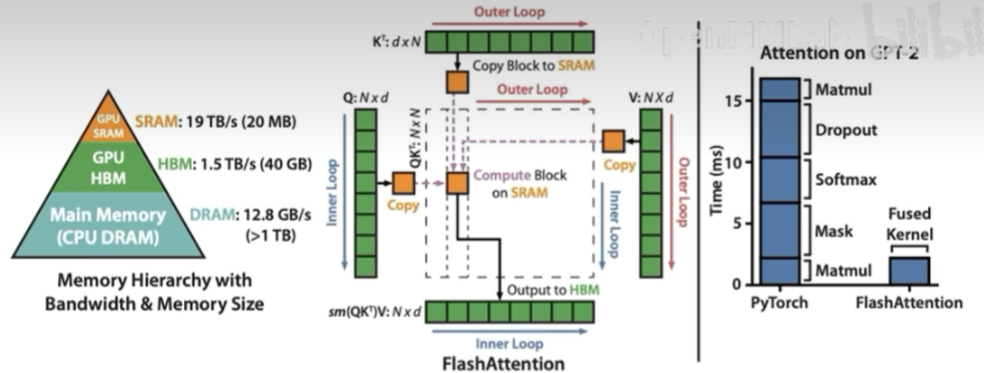
Flash Attention parallelizes the attention computation, avoiding the memory usage of Attention Score NxN during the computation process (N is usually quite large during training).
DeepSpeed ZeRO
ZeRO optimization saves parameters, gradients, and optimizer states during the training process by slicing them, significantly saving memory during multi-GPU training. In addition to slicing the intermediate states during training, DeepSpeed uses FP16 weights, which can significantly save memory on a single GPU compared to PyTorch’s AMP training.
This is not automatically enabled and requires adding –deepspeed deepspeed zero3
QLoRA followed by –deepspeed deepspeed zero2
xtuner train internlm_20b_qlora__oasst1_512_e3 --deepspeed deepspeed zero3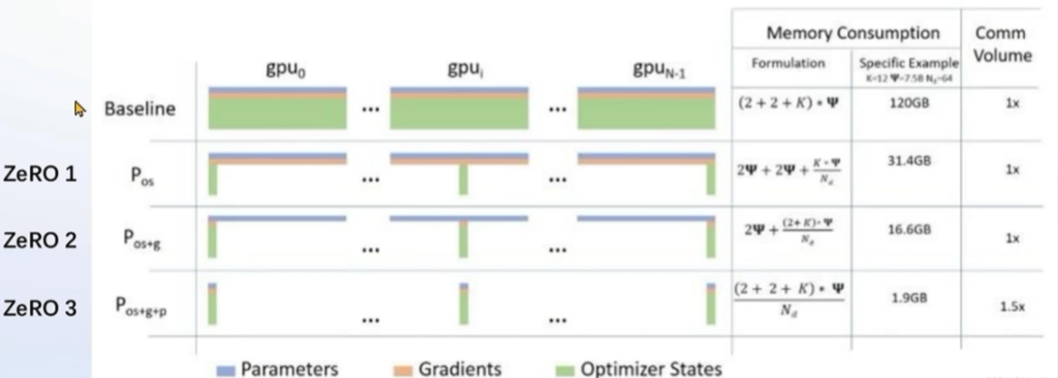
Recruitment Requirements
Complete the production of robot-related videos that meet the requirements.
The total duration must exceed 3 hours.
The video content must be high-quality courses, ensuring professionalism and quality.
Instructor Rewards
Enjoy course revenue sharing.
Receive 2 courses from Guyue Academy’s premium courses (excluding training camps).
Contact Us
Add staff WeChat: GYH-xiaogu




