Today, I tested the pinnacle of open-source local digital human system generation technology on Linux: Heygem.Testing environment: GPU: 4060ti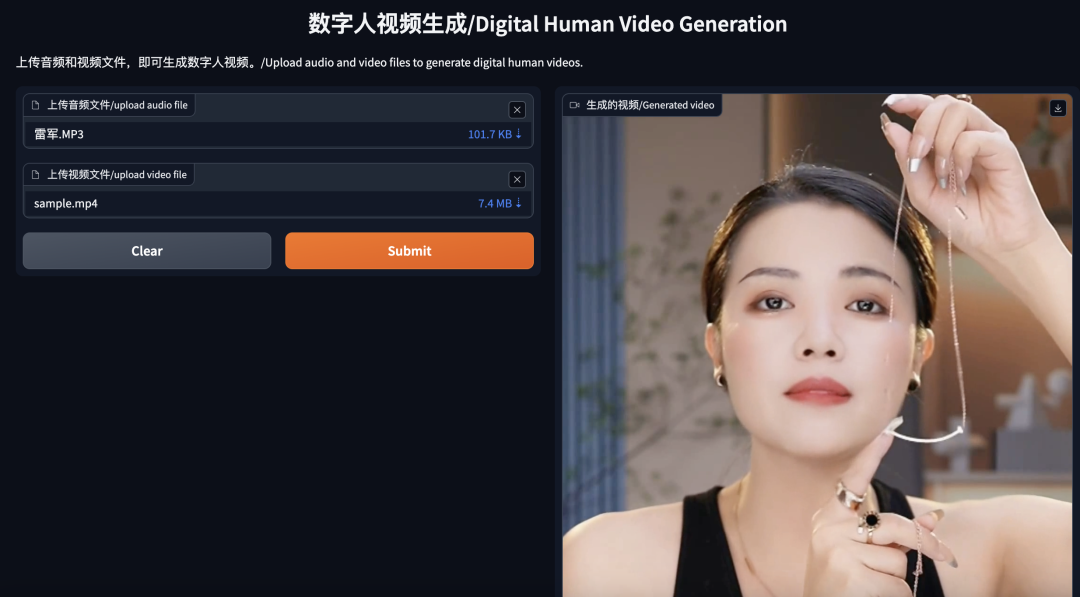 First, I conducted a round of tests using regular audio and video,with a 7-second audio inference taking 21 seconds.Here are the results:It is indeed much better than other current open-source technologies.Next, I will test with some real human videos to see the effect.The results are impressive, I give it a big thumbs up!Next, I will give it some challenges, using unprocessed singing as a driver:The results were not good; although the lip movements were relatively natural,the mouth did not sync properly, indicating that Heygem’s ceiling limit is singing.However, the synthesis speed is still decent, with a 40-second audio inference time taking 100 seconds.Now, let’s test it in English:The English results are also very good.When uploading images, Heygem could not synthesize, and the screen went completely black.Next, I will test with a more open and free video character; this video is challenging due to large turns and significant forward and backward movements:The test results indicate that there are some flaws in certain areas, but overall the effect is acceptable. Out of 100, it can score above 80, which is quite good.Now, let’s see the effect with a high-difficulty video of a person opening their mouth widely:Alright, today’s testing ends here, but further testing is not over. However, the test cases I provided are based on long-standing challenges with existing technologies; these cases are difficult for other technologies but are almost non-existent in Heygem. I truly love it, and I will continue to research deeply. Please follow the website:https://www.mindtechassist.com/
First, I conducted a round of tests using regular audio and video,with a 7-second audio inference taking 21 seconds.Here are the results:It is indeed much better than other current open-source technologies.Next, I will test with some real human videos to see the effect.The results are impressive, I give it a big thumbs up!Next, I will give it some challenges, using unprocessed singing as a driver:The results were not good; although the lip movements were relatively natural,the mouth did not sync properly, indicating that Heygem’s ceiling limit is singing.However, the synthesis speed is still decent, with a 40-second audio inference time taking 100 seconds.Now, let’s test it in English:The English results are also very good.When uploading images, Heygem could not synthesize, and the screen went completely black.Next, I will test with a more open and free video character; this video is challenging due to large turns and significant forward and backward movements:The test results indicate that there are some flaws in certain areas, but overall the effect is acceptable. Out of 100, it can score above 80, which is quite good.Now, let’s see the effect with a high-difficulty video of a person opening their mouth widely:Alright, today’s testing ends here, but further testing is not over. However, the test cases I provided are based on long-standing challenges with existing technologies; these cases are difficult for other technologies but are almost non-existent in Heygem. I truly love it, and I will continue to research deeply. Please follow the website:https://www.mindtechassist.com/