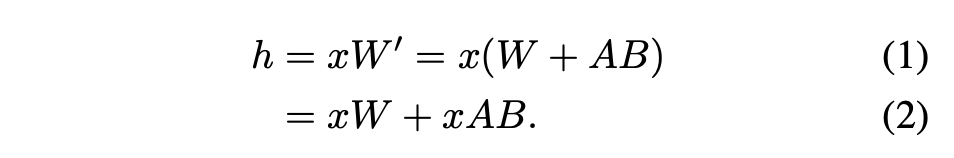Originally from PaperWeekly
Author: Dan Jiang
Affiliation: National University of Singapore
Generally speaking, the deployment of large language models follows the “pre-training – then fine-tuning” model. However, when fine-tuning a base model for numerous tasks (such as personalized assistants), the training and service costs can become very high. Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning method that is typically used to adapt a base model to multiple tasks, resulting in a large number of LoRA adapters derived from a single base model.
This approach provides numerous opportunities for batch inference during the service process. Research on LoRA has shown that fine-tuning only the adapter weights can achieve performance comparable to full weight fine-tuning. Although this method allows for low-latency inference for a single adapter and serial execution across adapters, it significantly reduces overall service throughput and increases total latency when servicing multiple adapters simultaneously. In summary, the challenge of how to serve these fine-tuned variants at scale remains unsolved.
In a recent paper, researchers from UC Berkeley, Stanford, and other universities proposed a new fine-tuning method called S-LoRA.

Paper Title:
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
https://arxiv.org/pdf/2311.03285.pdf
https://github.com/S-LoRA/S-LoRA
S-LoRA is a system designed for the scalable serving of numerous LoRA adapters, storing all adapters in main memory and transferring the adapters used for the current running queries to GPU memory.
S-LoRA proposes a technique called “Unified Paging,” which uses a unified memory pool to manage dynamically varying adapter weights of different levels and KV cache tensor lengths. Additionally, S-LoRA employs new tensor parallel strategies and highly optimized custom CUDA kernels to achieve heterogeneous batch processing for LoRA computations.
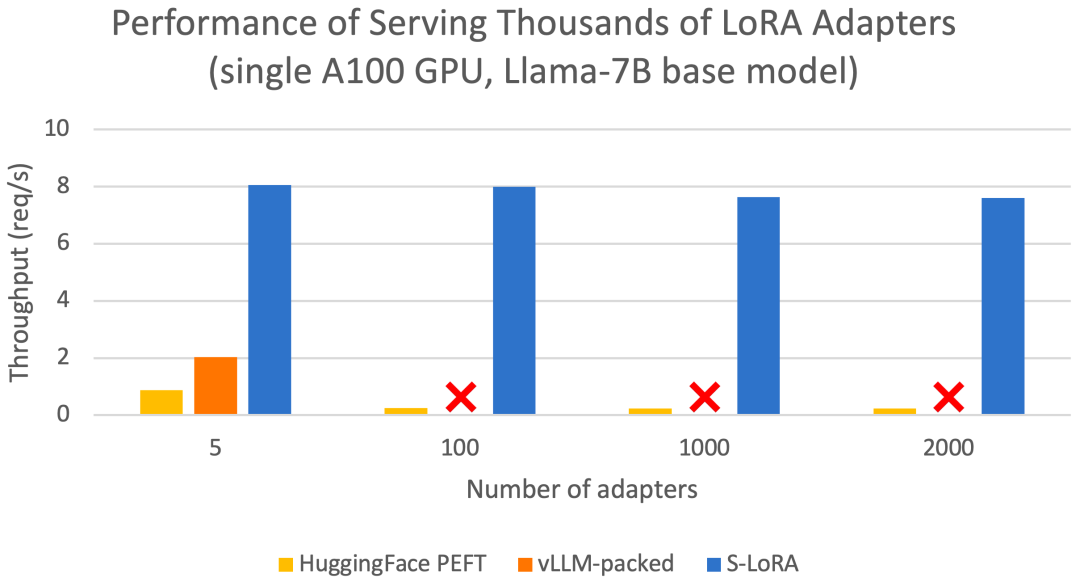
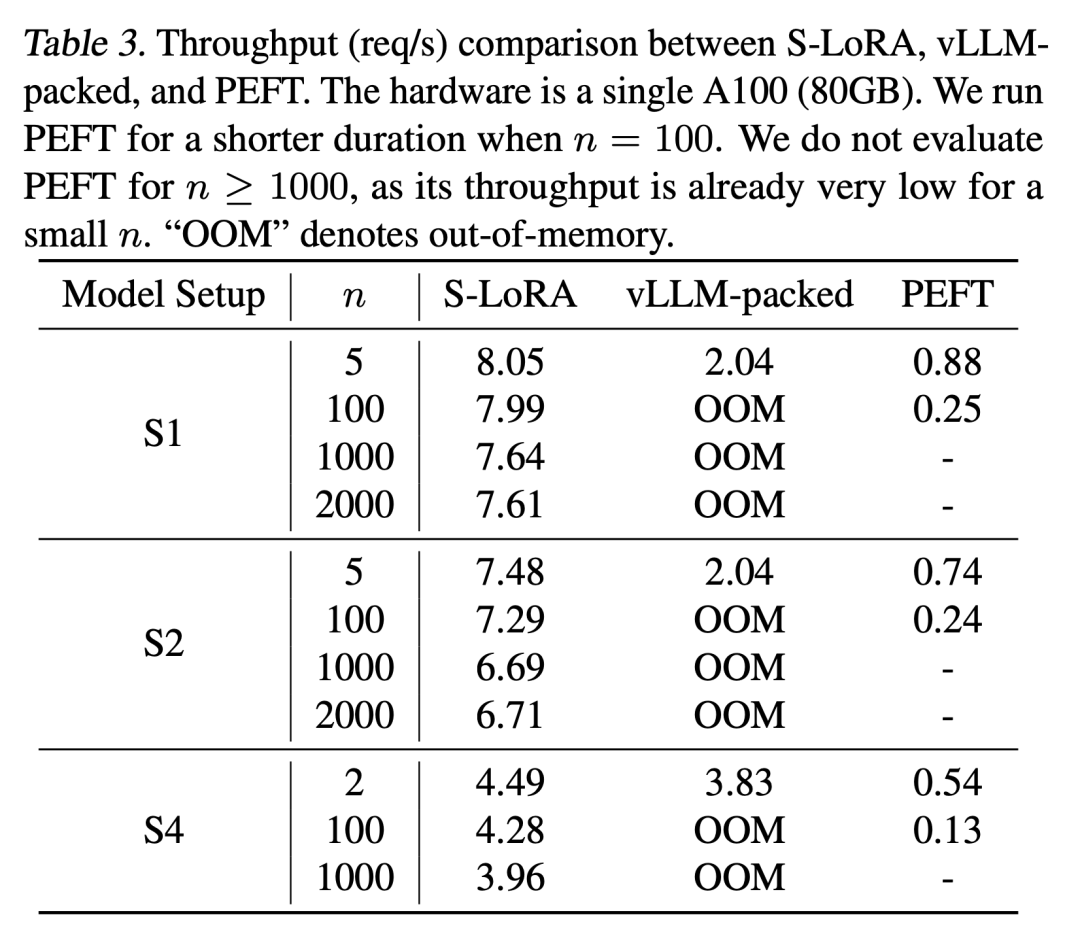
These features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or multiple GPUs (serving 2000 adapters simultaneously) with minimal overhead, reducing the increased LoRA computational costs to a minimum. In contrast, vLLM-packed requires maintaining multiple weight copies and can only serve fewer than 5 adapters due to GPU memory limitations.
Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (which only supports LoRA services), S-LoRA can increase throughput by up to 4 times and the number of served adapters by several orders of magnitude. Therefore, S-LoRA provides scalable service for many task-specific fine-tuned models and shows potential for large-scale customized fine-tuning services.
S-LoRA consists of three main innovative parts. Section 4 of the paper introduces a batching strategy that decomposes the computation between the base model and LoRA adapters. Additionally, the researchers address the challenges of demand scheduling, including adapter clustering and admission control. The batching capability across concurrent adapters presents new challenges for memory management.
In Section 5, the researchers extend PagedAttention to Unified Paging, supporting dynamic loading of LoRA adapters. This approach uses a unified memory pool to store KV caches and adapter weights in a paged manner, reducing fragmentation and balancing the dynamic variation sizes of KV caches and adapter weights. Finally, Section 6 introduces a new tensor parallel strategy that efficiently decouples the base model from LoRA adapters.
The following are key points:

Batch Processing
For a single adapter, the method recommended by Hu et al., 2021 is to merge the adapter weights into the base model weights to create a new model (see Equation 1). The benefit of this approach is that there are no additional adapter costs during inference, as the number of parameters in the new model is the same as that of the base model. In fact, this is also a prominent feature of the original LoRA work.
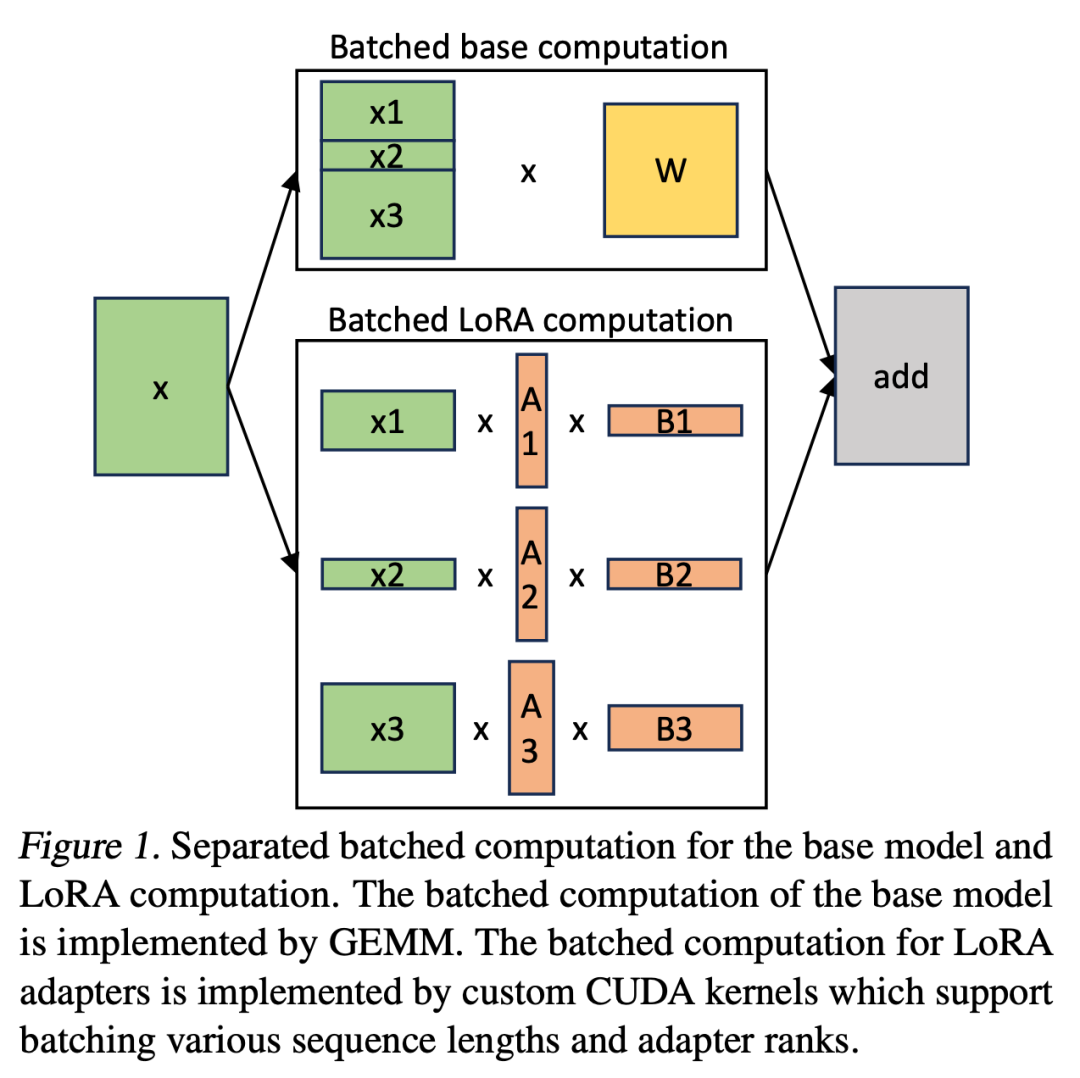
This paper points out that merging LoRA adapters into the base model is inefficient for high-throughput service settings with multiple LoRAs. Instead, the researchers recommend computing the LoRA computation xAB in real-time (as shown in Equation 2).
In S-LoRA, the computation of the base model is batched and then uses custom CUDA kernels to perform the additional xAB for all adapters separately. This process is illustrated in Figure 1. The researchers did not use padding and batch GEMM kernels in the BLAS library to compute LoRA but instead implemented custom CUDA kernels to achieve more efficient computation without padding, with implementation details in Section 5.3.
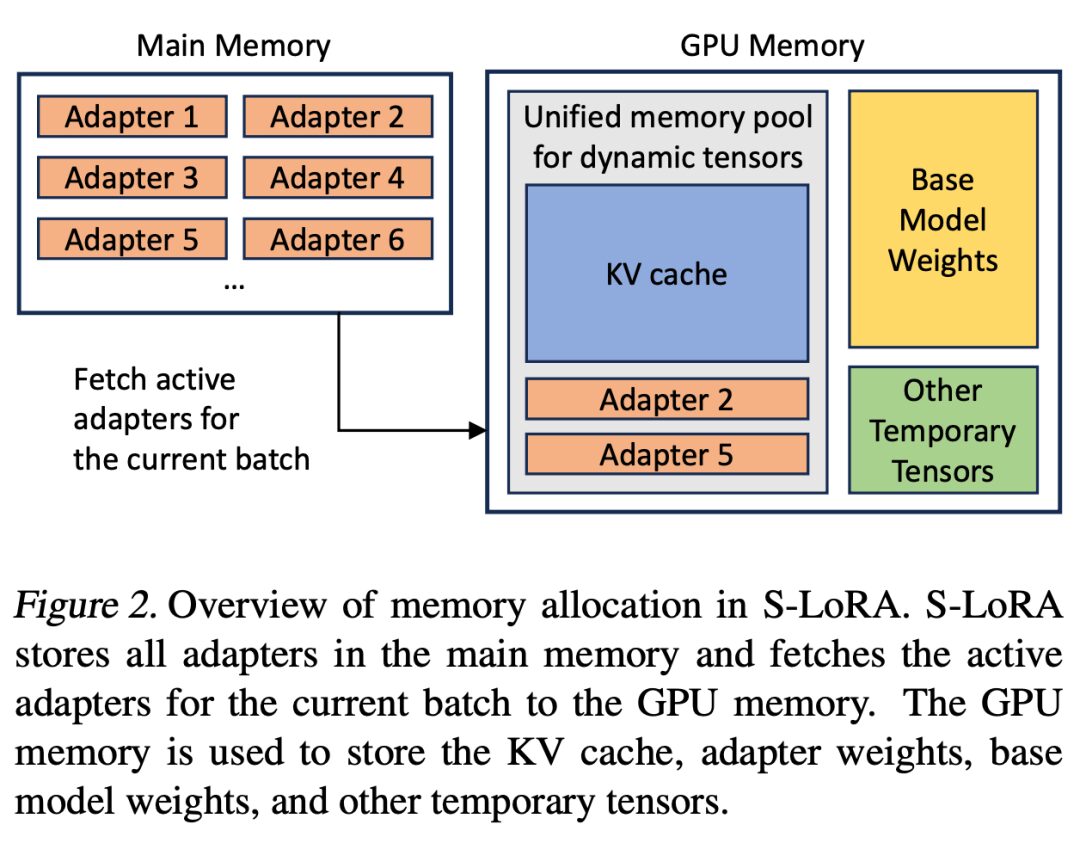
 If the LoRA adapters are stored in main memory, their number can be large, but the number of LoRA adapters required for the current running batch is manageable, as the batch size is limited by GPU memory. To leverage this advantage, the researchers store all LoRA adapter cards in main memory and only transfer the required LoRA adapter cards to GPU RAM for the current running batch during inference. In this case, the maximum number of servable adapters is limited by the size of the main memory. Figure 2 illustrates this process. Section 5 also discusses techniques for efficiently managing memory.
If the LoRA adapters are stored in main memory, their number can be large, but the number of LoRA adapters required for the current running batch is manageable, as the batch size is limited by GPU memory. To leverage this advantage, the researchers store all LoRA adapter cards in main memory and only transfer the required LoRA adapter cards to GPU RAM for the current running batch during inference. In this case, the maximum number of servable adapters is limited by the size of the main memory. Figure 2 illustrates this process. Section 5 also discusses techniques for efficiently managing memory.
Memory Management
Serving multiple LoRA adapter cards simultaneously presents new memory management challenges compared to serving a single base model. To support multiple adapters, S-LoRA stores them in main memory and dynamically loads the required adapter weights for the current running batch into GPU RAM.
In this process, there are two obvious challenges. The first is memory fragmentation, caused by the dynamic loading and unloading of adapter weights of different sizes. The second is the latency overhead incurred by loading and unloading adapters. To effectively address these issues, the researchers propose “Unified Paging” and overlap I/O with computation through prefetching adapter weights.
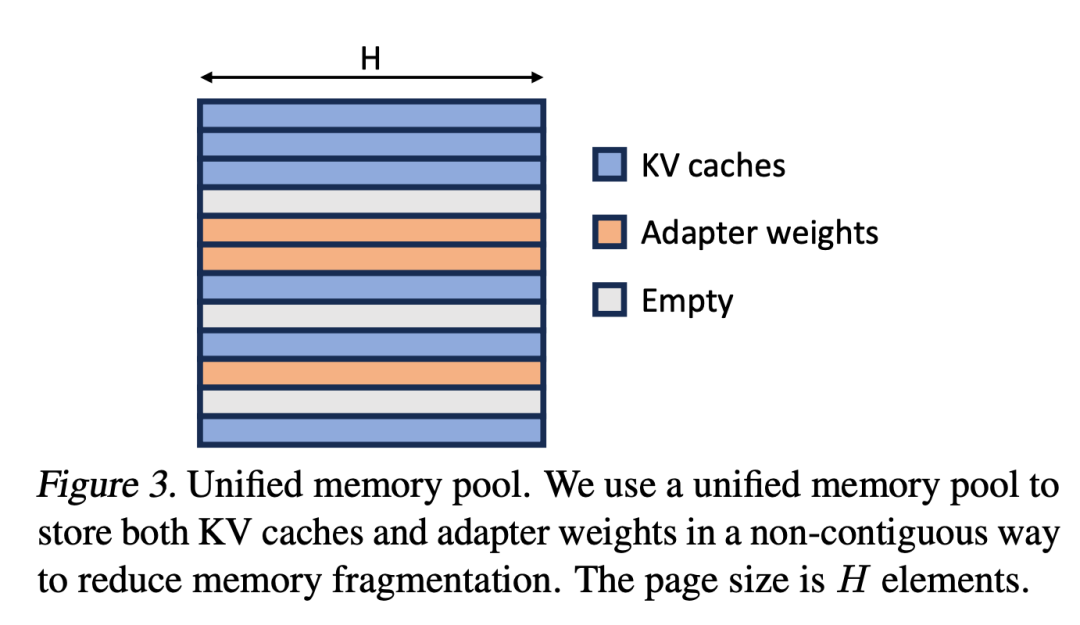
The researchers extend the idea of PagedAttention to Unified Paging, which manages both KV caches and adapter weights. Unified Paging uses a unified memory pool to jointly manage KV caches and adapter weights. To achieve this, they first statically allocate a large buffer for the memory pool, using all available space except for the space occupied by base model weights and temporary activation tensors. Both KV caches and adapter weights are stored in a paged manner in the memory pool, with each page corresponding to one H vector.
Thus, a KV cache tensor with sequence length S occupies S pages, while a LoRA weight tensor of level R occupies R pages. Figure 3 shows the layout of the memory pool, where KV caches and adapter weights are stored in an interleaved and non-contiguous manner. This approach greatly reduces fragmentation and ensures that adapter weights of different levels coexist with dynamic KV caches in a structured and systematic way.
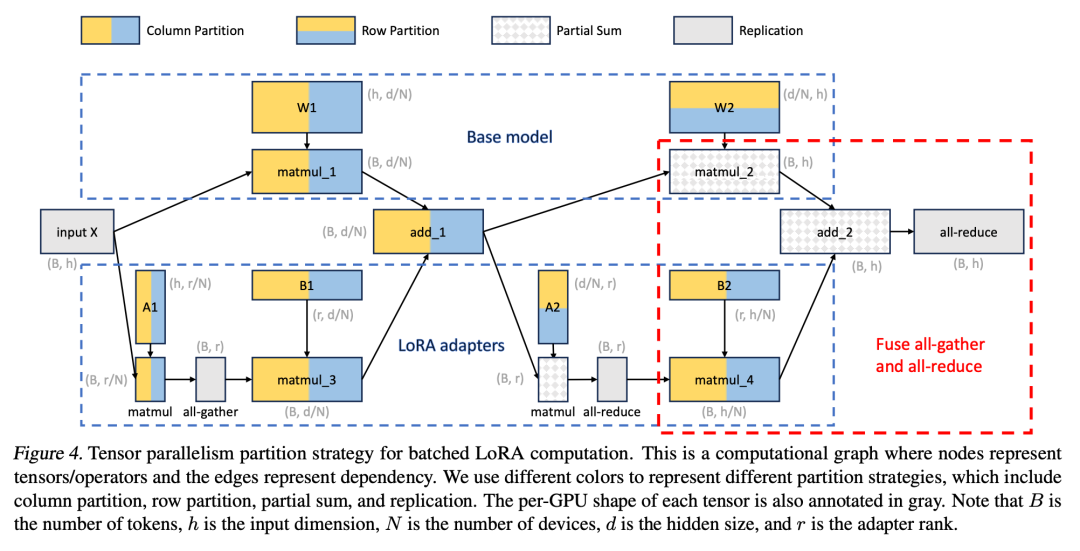
Tensor Parallelism
Additionally, the researchers designed a novel tensor parallel strategy for batch LoRA inference to support multi-GPU inference for large Transformer models. Tensor parallelism is the most widely used parallel method because its single-program multiple-data mode simplifies its implementation and integration with existing systems. Tensor parallelism can reduce memory usage and latency per GPU when serving large models. In this paper’s setup, additional LoRA adapters introduce new weight matrices and matrix multiplications, necessitating the development of new partitioning strategies for these new elements.
Evaluation
Finally, the researchers evaluate S-LoRA by serving Llama-7B/13B/30B/70B.
The results show that S-LoRA can serve thousands of LoRA adapters on a single GPU or multiple GPUs with very little overhead. Compared to the state-of-the-art parameter-efficient fine-tuning library Huggingface PEFT, S-LoRA can increase throughput by up to 30 times. Compared to high-throughput service systems like vLLM that support LoRA service, S-LoRA can quadruple throughput and increase the number of served adapters by several orders of magnitude.
For more research details, please refer to the original paper.