1. Introduction
The core of multi-sensor fusion technology in autonomous driving is to construct a comprehensive and highly reliable environmental perception system through the combination of “LiDAR + camera + millimeter-wave radar + ultrasonic radar,” providing accurate real-time traffic information for decision-making and control modules.
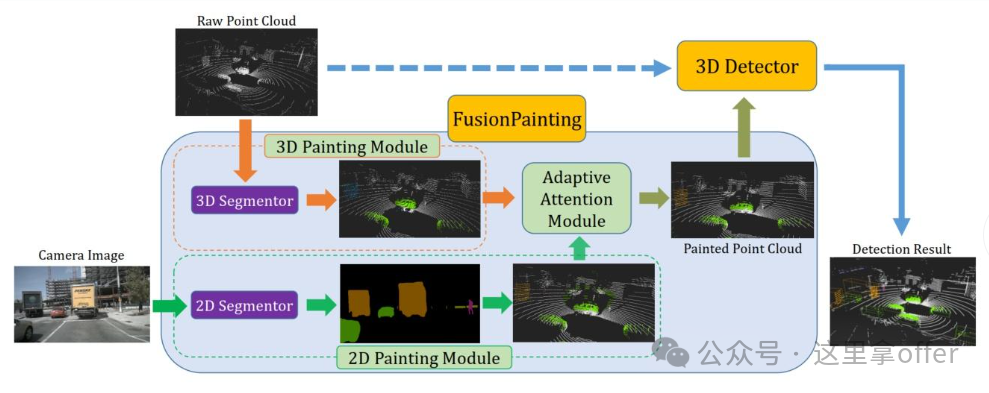
The previous chapters have introduced LiDAR, monocular/binocular cameras, millimeter-wave radar, and ultrasonic radar, so we will not elaborate on their principles here.
2. Basic Principles of Multi-Sensor Fusion
In autonomous driving systems, multi-sensor fusion technology simply integrates data collected from different types of sensors, allowing vehicles to perceive the environment more accurately and coherently.
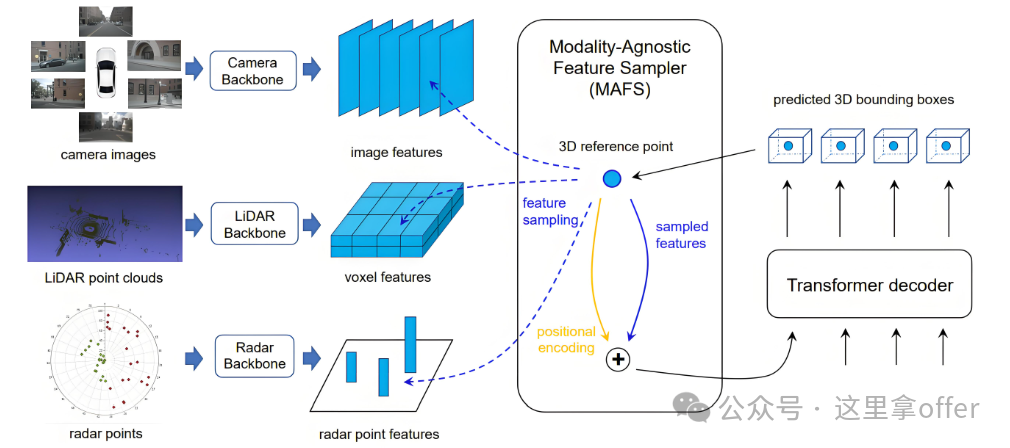
Commonly used sensors include cameras, LiDAR, millimeter-wave radar, and ultrasonic radar. Each has its characteristics:
-
Cameras can capture details such as color and texture of objects, but detection accuracy significantly decreases in poor lighting or bright light conditions;
-
LiDAR has high three-dimensional imaging accuracy, but in extreme weather conditions like heavy rain or dense fog, the laser signals can be scattered, greatly reducing effective detection range;
-
Millimeter-wave radar detects using electromagnetic waves, capable of identifying distant targets even in fog or heavy rain, but has weak capability for detail analysis;
-
Ultrasonic radar has a short detection range and is mainly used for close-range monitoring, often assisting in automatic parking systems.
The core of fusion technology is to calibrate the timestamps and spatial coordinates of each sensor consistently — for example, aligning the target position captured by the camera in the video with the corresponding position in the LiDAR’s three-dimensional coordinate system. This allows compensating for the perceptual shortcomings of individual sensors, enabling vehicles to make more accurate decisions in complex road environments, thereby enhancing driving safety.
The technical implementation must follow a closed-loop framework of “data input → preprocessing → information fusion → result output,” with key steps including:
-
Data collection and preprocessing standardize the raw data from multiple sensors, addressing the “data heterogeneity” issue, which is fundamental to fusion. Core tasks include:
-
Time synchronization: Aligning the sampling timestamps of different sensors (e.g., in autonomous driving, the sampling time difference between LiDAR, cameras, and millimeter-wave radar must be controlled within 1ms) using hardware clocks (like PTP protocol) or software interpolation to avoid fusion errors caused by timing discrepancies.
-
Spatial registration: Mapping the measurement data from different sensors to a unified spatial coordinate system (e.g., vehicle coordinate system, world coordinate system) through calibration (e.g., camera intrinsic/extrinsic calibration, radar-camera joint calibration) to solve the “observational perspective difference” issue (e.g., converting the 2D pixel coordinates of the camera to 3D world coordinates to align with LiDAR point clouds).
-
Noise suppression: Removing random noise and outliers from the raw data (e.g., raindrop interference in LiDAR, motion blur in cameras) through filtering (e.g., mean filtering, Gaussian filtering) or outlier detection (e.g., RANSAC algorithm).
-
Data association identifies information in different sensor data that corresponds to the “same target/feature” (e.g., whether the “car” detected by the camera is the same object as the “rectangular target” in the LiDAR point cloud), avoiding “duplicate counting” or “target misassociation.” Core algorithms include:
-
Distance-based association (e.g., Euclidean distance, Mahalanobis distance);
-
Feature-based association (e.g., matching target size, speed, shape features);
-
Probability-based association (e.g., Joint Probabilistic Data Association (JPDA), Multiple Hypothesis Tracking (MHT)).
-
State estimation and decision fusion integrate the associated information through mathematical models or algorithms based on the fusion level (data level, feature level, decision level), outputting the final state of the target (e.g., position, speed, category) or decision results (e.g., “Is there an obstacle?” “Is the target a pedestrian?”).
3. Multi-Sensor Fusion Methods
Multi-sensor fusion mainly includes two methods: early fusion and late fusion. Early fusion directly inputs data from multiple modalities into the model, aiming to improve target detection accuracy; its key is to allow the model to comprehensively understand information from the data source, enabling more accurate identification of vehicles, pedestrians, and obstacles on the road. In early fusion, key information useful for environmental perception must be extracted from each sensor to support more reliable decision-making.
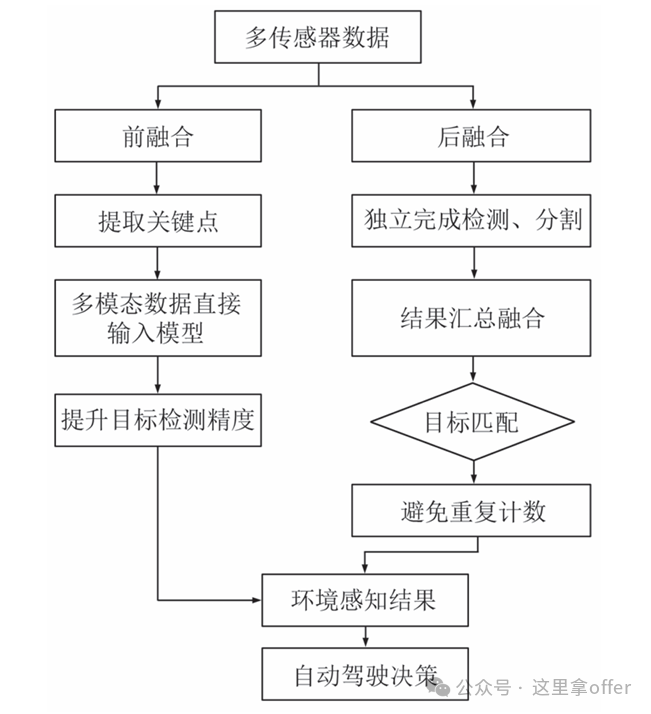
Late fusion, on the other hand, allows each modality to complete detection or segmentation tasks independently before the system aggregates and integrates these results. The main challenges of late fusion are how to effectively merge information from different sources and target matching — determining whether the targets detected by different sensors correspond to the same real object in the environment, avoiding duplicate counting or incorrect associations. The application process of multi-sensor fusion technology in autonomous driving can refer to the above image.
4. Introduction to Sensor Fusion Technology
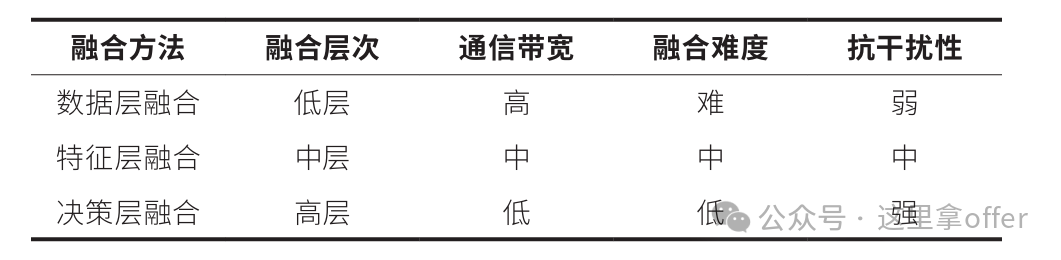
Multi-sensor fusion in autonomous driving typically progresses through the “data layer → feature layer → decision layer,” with different levels corresponding to varying technical difficulties and application scenarios. Currently, the mainstream approach isfeature layer fusion.

Multi-sensor fusion technology involves the collaborative operation of multiple different types of sensors, merging real-time data from various sensors to enhance the intelligent vehicle’s environmental perception and intelligent decision-making capabilities, effectively compensating for the limitations of single sensors in vehicles, thereby increasing the safety and reliability of intelligent vehicles and reducing safety risks for drivers and pedestrians.
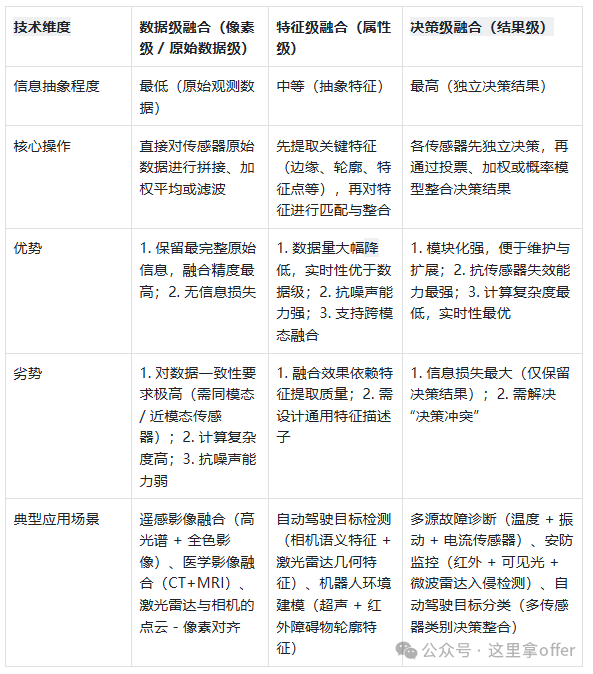
4.1 Data Layer Fusion
As the core technology of multi-sensor fusion perception, it directly performs statistical analysis on the original observational data, focusing on the spatiotemporal correlation of raw data from different sensors, preserving data details to the greatest extent.
Data layer fusion can completely retain the details of on-site data, providing underlying features for subsequent processing, and has strong fault tolerance for uncertainty, incompleteness, and noise interference in observational data.
However, data layer fusion requires processing massive amounts of raw data, which is computationally complex and has high latency, making it difficult to meet real-time requirements; when the spatiotemporal deviations of multi-source data are significant, complex alignment and calibration processes are needed.
Additionally, it is only suitable for homogeneous sensors (observing the same physical phenomenon), while heterogeneous sensors require feature-level or decision-level fusion.
Example of Data Layer Fusion:

First, RGB information is attached to each point in the point cloud based on the projection matrix. Then, based on the index of the maximum height point obtained, the RGB information of the point is also mapped to the BEV view, generating an image from the bird’s-eye view perspective. Combining the previously generated height, density, and intensity channel information, a total of six channels of BEV view are generated. The above image illustrates the data layer fusion, showing the image, original point cloud, and the fused point cloud, along with the BEV view generated from the fused point cloud.
4.2 Feature Layer Fusion
Due to the characteristic of point clouds being dense near and sparse far, the number of points for distant targets is relatively small, and the small target objects occupy a small space, making it more difficult to detect them when converted to the BEV view. Therefore, a multi-stage fusion model is used to merge image features with BEV features, supplementing the feature information of objects and improving detection capability.
The process is divided into two steps: first, preprocessing the multi-source raw data and extracting features (e.g., edges, speed, etc.), and then generating a joint feature vector through feature cascading or transformation for subsequent decision analysis.
Feature layer fusion retains key information while achieving dimensionality reduction, reducing computational load and improving efficiency, and the extracted features are directly related to decision objectives, providing discriminative information.
However, feature extraction may lose original data information, affecting system detection accuracy and robustness; feature engineering needs to be designed according to specific scenarios, increasing the complexity of algorithm development. In the fusion architecture, it serves as both an abstraction of the data-level fusion results and a foundational input for decision-level fusion.
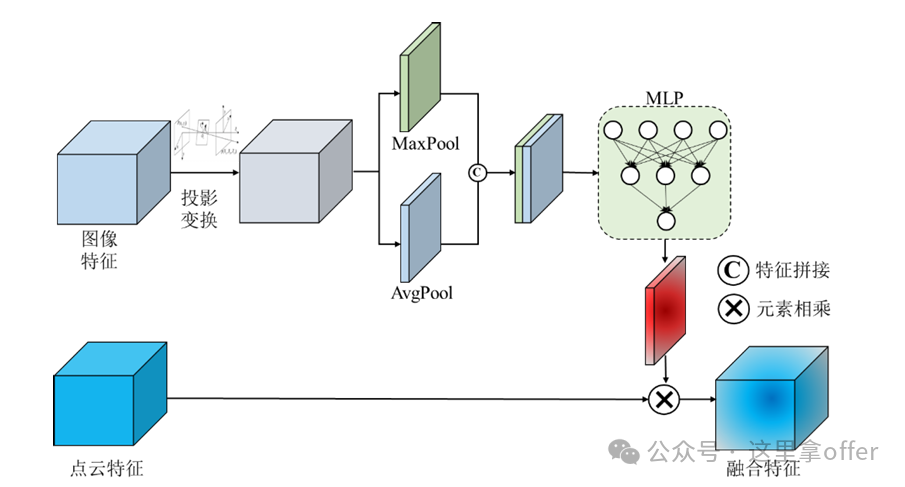
Example of Feature Layer Fusion:
The fusion module simultaneously receives image features extracted from the convolutional layer and point cloud features, first projecting the image features into the BEV space using coordinate relationships. Then, the image features are processed to obtain spatial weights of the feature map, normalized, and multiplied element-wise with the point cloud features. By multiplying the spatial attention with the input point cloud feature map, the image features and point cloud features are fused, enhancing the model’s performance.
4.3 Decision Layer Fusion
As a high-level fusion technology, the process is divided into two steps: first, each sensor generates local inference results based on its observational data, and then decision fusion algorithms analyze multiple local decisions to form a global conclusion.
The characteristics include high adaptability, strong robustness and fault tolerance, and low communication bandwidth requirements; it needs to be combined with specific decision tasks, utilizing the target features extracted from feature-level fusion and employing reasonable strategies to achieve this.
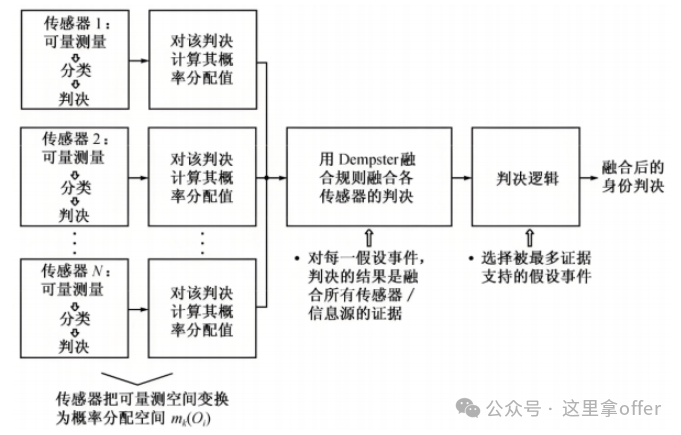
Additionally, it has advantages such as low data transmission volume, strong real-time performance, and the ability to handle asynchronous data and heterogeneous information. Common algorithms used in practical applications include D-S evidence theory, Bayesian inference, etc., which are important parts of multi-source fusion environmental perception, capable of integrating multi-sensor information in complex environments to provide comprehensive and accurate support for decision-making.
4.4 Summary
5. Multi-Sensor Fusion Algorithm System
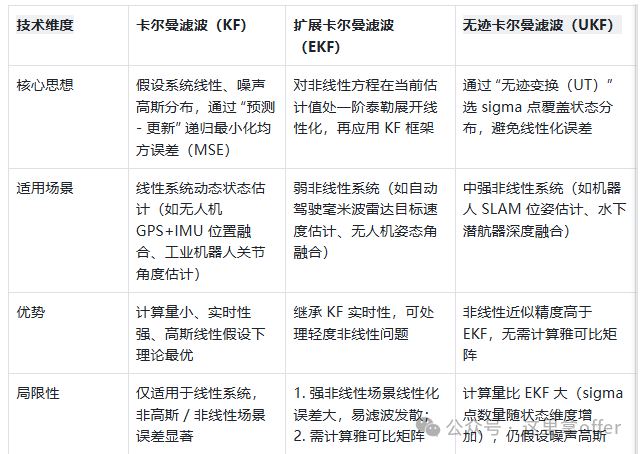
The fusion algorithm is the mathematical core for achieving “uncertainty suppression” and must be selected based on the system’s linear/non-linear characteristics, noise distribution types (Gaussian/non-Gaussian), and real-time requirements. Mainstream algorithms can be divided into three categories: “classical probabilistic filtering,” “uncertainty reasoning,” and “machine learning.””>
-
Classical Probabilistic Filtering (suitable for state estimation)
This type of algorithm is based on the “Bayesian estimation framework,” recursively updating the probability distribution of the target state to achieve state estimation of dynamic systems, and is the mainstream choice for linear/weakly non-linear systems.
Kalman Filter Pseudocode Implementation
// Initialize Kalman Filterfunction InitializeKalmanFilter(initialStateEstimate x0, initialCovarianceMatrix P0, stateTransitionMatrix F, measurementMatrix H, processNoiseCovariance Q, measurementNoiseCovariance R): x = x0 // Initial state estimate P = P0 // Initial covariance matrix Store F, H, Q, R// Prediction step: Predict the next state based on the system modelfunction Predict(): // Predict state estimate x_pred = F * x // Predict covariance matrix P_pred = F * P * F^T + Q return x_pred, P_pred// Update step: Correct the prediction using new measurementfunction Update(x_pred, P_pred, measurement z): // Calculate Kalman gain K = P_pred * H^T * (H * P_pred * H^T + R)^(-1) // Update state estimate using measurement x = x_pred + K * (z - H * x_pred) // Update covariance matrix P = (I - K * H) * P_pred return x, P// Main process of Kalman FilterMain Process: InitializeKalmanFilter(x0, P0, F, H, Q, R) For each time step t: Get measurement z_t // Prediction x_pred, P_pred = Predict() // Update (if there is a valid measurement) if z_t is valid: x, P = Update(x_pred, P_pred, z_t) else: x, P = x_pred, P_pred // Use prediction result when there is no measurement Output current state estimate x
-
Uncertainty Reasoning (suitable for decision fusion)
This type of algorithm focuses on handling “incomplete, ambiguous, or conflicting information,” integrating multi-sensor decisions through logical reasoning or probabilistic synthesis, and is primarily applied in decision-level fusion.
-
Bayesian Inference is based on Bayes’ theorem, treating the decision results of each sensor as “evidence” to update the posterior probability of the target event, ultimately selecting the decision with the highest probability. It is suitable for scenarios where sensor decisions have a clear probabilistic model.
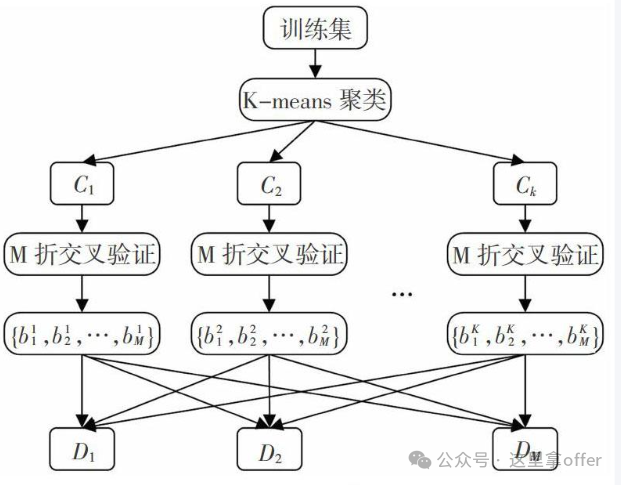
-
D-S Evidence Theory breaks through the limitation of Bayesian inference that requires known prior probabilities, describing information uncertainty through “Basic Probability Assignment (BPA),” “Belief Function (Bel),” and “Likelihood Function (Pl),” supporting the synthesis of multi-source evidence (e.g., handling decision conflicts caused by sensor failures). However, under high-conflict evidence, traditional D-S synthesis rules may yield counterintuitive results, requiring improvement.
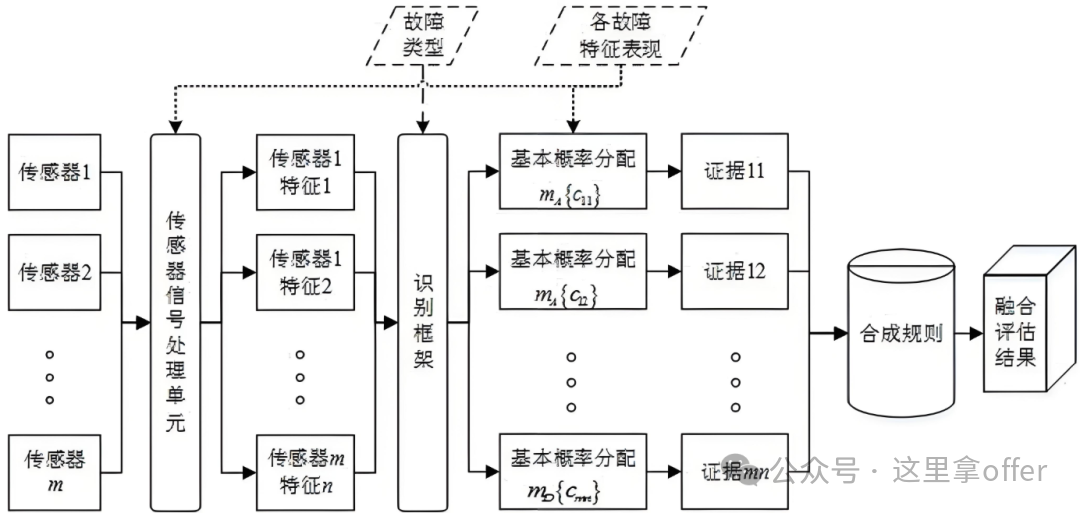
-
Fuzzy Logic addresses the “fuzziness” of sensor decisions (e.g., “target is far away,” “temperature is high”) by quantifying fuzzy information through fuzzy sets and membership functions, and implementing decision fusion through fuzzy rule bases (e.g., “If radar distance > 50m and camera clarity is low, then target credibility decreases”). It is suitable for scenarios with semantic ambiguity and where precise mathematical models are difficult to establish (e.g., smart home environmental perception, industrial equipment status assessment).

-
Machine Learning (suitable for complex non-linear fusion)
With the development of deep learning, data-driven fusion algorithms have gradually become mainstream, especially suitable for cross-modal and high-dimensional data fusion (e.g., fusion of camera images and LiDAR point clouds).
-
Convolutional Neural Networks (CNN) for cross-modal fusion design dual-branch or multi-branch CNNs, processing different sensor data separately (e.g., one branch processes RGB images, another processes bird’s-eye view (BEV) of LiDAR point clouds), and then achieving feature-level fusion through feature concatenation and attention mechanisms (e.g., Cross-Attention), ultimately outputting target detection or segmentation results (e.g., the BEVFormer algorithm in autonomous driving, which fuses camera and LiDAR for 3D target detection).
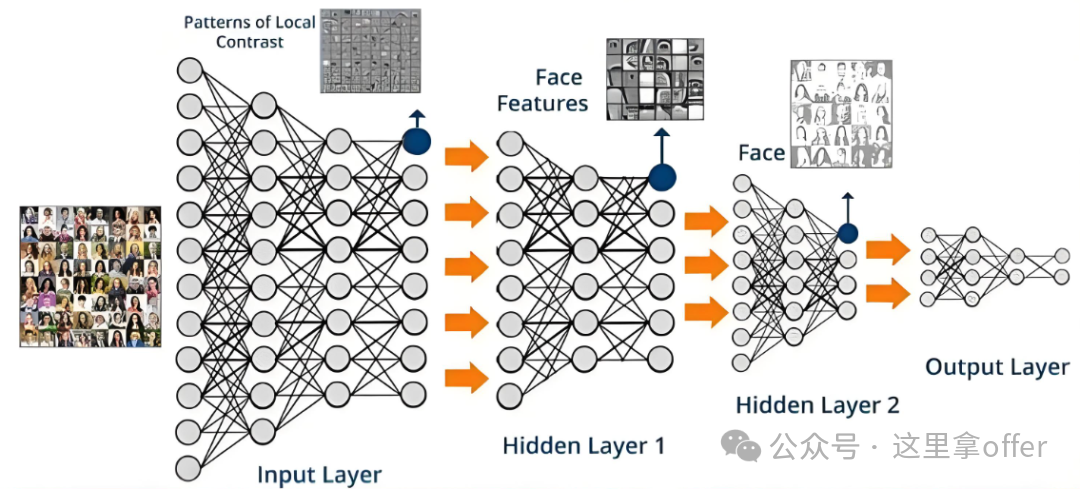
-
Transformer fusion utilizes the global attention mechanism of Transformers to break the boundaries of sensor modalities, mapping features from different sensors (e.g., camera pixel features, radar point cloud features) into a unified feature space, capturing cross-modal associations through self-attention and cross-attention, suitable for fusion in high-dynamic and complex scenarios (e.g., multi-sensor semantic segmentation, dynamic target tracking).
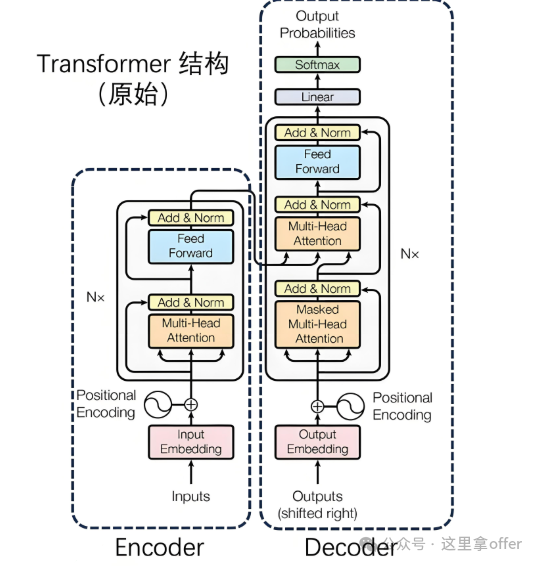
-
Reinforcement Learning (RL) fusion strategy optimization treats fusion strategies (e.g., sensor weight allocation, data association rules) as “actions,” and the accuracy/real-time performance of fusion results as “rewards,” training optimal fusion strategies through reinforcement learning, suitable for adaptive fusion in dynamic environments (e.g., dynamic adjustment of sensor weights in complex terrains).
6. Future Development Directions of Perception Fusion Technology
-
Multi-Modal Fusion Perception System
Although current sensor technology is mature, single sensors are easily interfered with in complex environments (e.g., LiDAR signal attenuation in fog, camera overexposure in bright light). By constructing a multi-sensor collaborative perception network and pairing it with dynamic data priority allocation strategies (e.g., increasing infrared sensor weight in fog, enhancing millimeter-wave radar data confidence in rain), the limitations and blind spots of single sensors can be overcome, improving perception robustness and accuracy. Multi-modal fusion will also become a core direction for intelligent vehicle environmental perception.
-
Sensor Technology Innovation
With the deep integration of AI and the Internet of Things, intelligent vehicle sensors are moving towards intelligent, integrated, and networked stages, with future capabilities for stronger cross-domain collaboration, supporting multi-dimensional information collection in complex scenarios. However, technological development faces ethical challenges such as data security and privacy protection, requiring simultaneous advancement of legal regulations and technical standards to ensure sustainable industry development.
-
Vehicle-Road Collaborative Perception Network
Currently, vehicles rely heavily on onboard sensors for environmental perception, which can lead to blind spots due to target occlusion or exceeding detection range. V2X collaborative perception leverages wireless communication to build a vehicle-to-vehicle, vehicle-to-road, and vehicle-to-person information exchange network, upgrading single-vehicle perception to global perception, significantly enhancing target detection and classification capabilities in complex scenarios; it can also turn vehicles into smart traffic information nodes, optimizing traffic flow through data sharing. In the future of intelligent transportation, V2X collaborative perception will be a key technology for achieving safe and efficient travel.