Paper Author | Li Chen
Editor | Heart of Autonomous Driving

This year’s CVPR Best Paper was awarded to end-to-end autonomous driving, which, in the eyes of automotive professionals, represents a consensus: end-to-end autonomous driving is the future of the industry. What motivates end-to-end autonomous driving? What are its roadmaps, methodologies, challenges, and future trends? Today, the Heart of Autonomous Driving presents an overview of the end-to-end autonomous driving field. The autonomous driving community has witnessed a rapid growth in the adoption of end-to-end algorithm frameworks that utilize raw sensor inputs to generate vehicle motion planning, rather than focusing on individual tasks such as detection and motion prediction. Compared to modular pipelines, end-to-end systems benefit from joint feature optimization of perception and planning. The field has flourished due to the availability of large-scale datasets, closed-loop evaluations, and the increasing demand for autonomous driving algorithms to perform effectively in challenging scenarios. In this survey, a comprehensive analysis of over 250 papers covering the motivations, roadmaps, methods, challenges, and future trends of end-to-end autonomous driving is conducted. Several key challenges are discussed, including multimodality, interpretability, causal confusion, robustness, and world models. Furthermore, recent advancements in foundational models and visual pre-training are discussed, along with how these technologies can be integrated into end-to-end driving frameworks.
1Introduction
Traditional autonomous driving systems adopt a modular deployment strategy, where each function, such as perception, prediction, and planning, is developed separately and integrated into the onboard vehicle. The planning or control module responsible for generating steering and acceleration outputs plays a crucial role in determining the driving experience. The most common planning methods in modular pipelines include complex rule-based designs, which often prove ineffective in addressing the multitude of situations encountered during driving. Therefore, there is an increasing trend to leverage large-scale data and use learning-based planning as a viable alternative.
End-to-end autonomous driving systems can be defined as fully differentiable processes that take raw sensor data as input and produce planning and/or low-level control actions as output. The diagrams below illustrate the differences between the classical paradigm and the end-to-end paradigm.
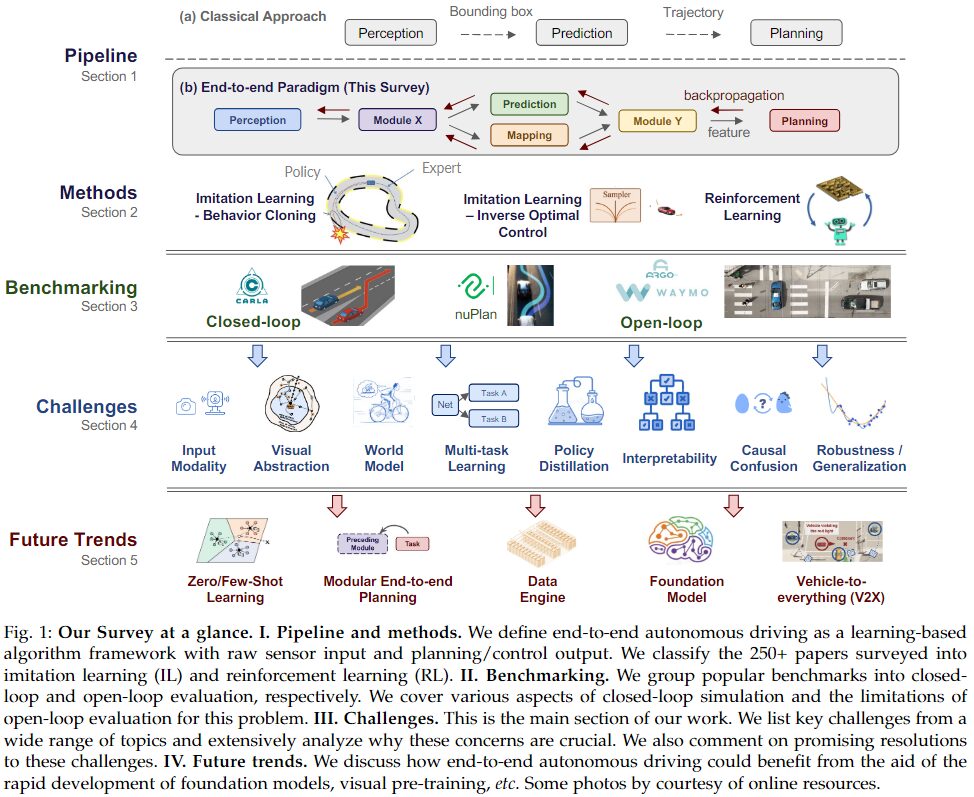
The classical paradigm directly inputs the outputs of each component (such as bounding boxes and vehicle trajectories) into subsequent units (dashed arrows). In contrast, the end-to-end paradigm propagates feature representations between components (solid gray arrows). The optimized function is set to, for example, planning performance, and the loss is minimized through backpropagation (red arrows). In this process, tasks are jointly and globally optimized.
This survey provides a broad review of this emerging topic. The above diagram outlines the work.
-
First, discuss the motivations and roadmaps for end-to-end autonomous driving systems;
-
End-to-end methods can be roughly divided into imitation learning and reinforcement learning, with a brief review of these methods;
-
Cover datasets and benchmarks for closed-loop and open-loop evaluations;
-
Summarize a series of key challenges, including interpretability, generalization, world models, causal confusion, etc.;
-
Discuss future trends that should be accepted by the community, incorporating recent developments from data engines, large foundational models, and V2X.
Motivations for End-to-End Systems
In the classical pipeline, each model serves an independent component and corresponds to a specific task (e.g., traffic light detection). Such designs are beneficial for interpretability, verifiability, and ease of debugging. However, due to the differing optimization objectives of each module, with detection in perception pursuing mean average precision (mAP) while planning targets driving safety and comfort, the entire system may fail to align with a unified goal (i.e., the ultimate planning/control task). As the sequential program progresses, the errors of each module may compound, leading to a loss of information in the autonomous driving system. Additionally, multi-task and multi-model deployments may increase computational burdens and potentially lead to suboptimal utilization of computation.
Compared to the classical paradigm, end-to-end autonomous driving systems offer several advantages.
-
They simply combine perception, prediction, and planning into a single model that can be jointly trained. -
The entire system, including intermediate representations, is optimized towards the ultimate task. -
Shared backbone networks enhance computational efficiency. -
Data-driven optimization has the potential to improve system capabilities by simply scaling up training resources.
Note that the end-to-end paradigm does not necessarily imply a black box with only planning/control outputs. It can be modular (as shown in the above diagram) with intermediate representations and outputs, similar to classical methods. In fact, some state-of-the-art systems propose modular designs while simultaneously optimizing all components for superior performance.
Roadmap
The diagram below depicts the temporal roadmap of key achievements in end-to-end autonomous driving, where each section indicates a significant paradigm shift or performance improvement.
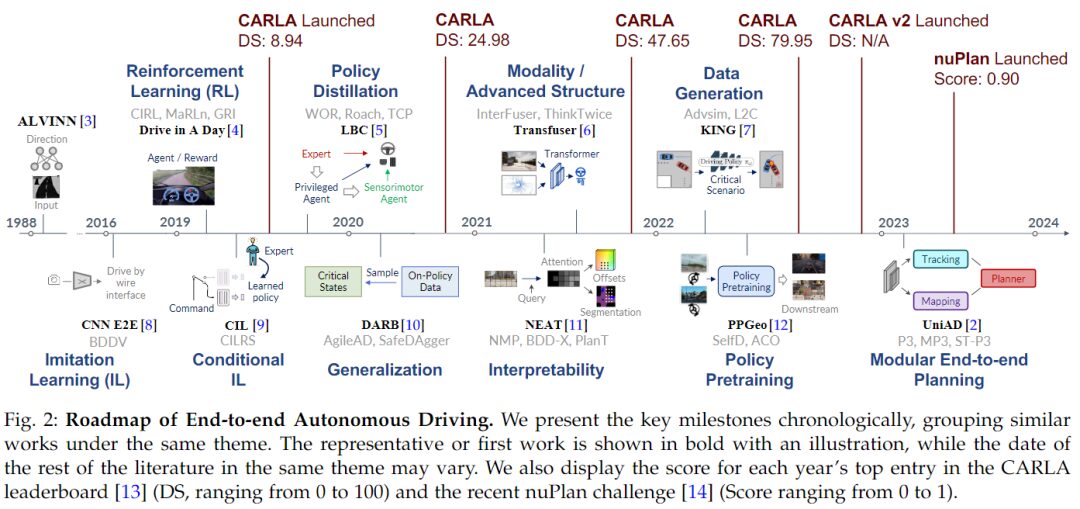
The history of end-to-end autonomous driving dates back to ALVINN in 1988, where the inputs were two “retinas” from cameras and laser range finders, and steering outputs were generated by a simple neural network. Bojarski et al. designed an end-to-end CNN prototype system for simulation and road testing, re-establishing this concept in the era of GPU computing. With the advancement of deep neural networks, significant progress has been made in both imitation learning and reinforcement learning. Strategies proposed in LBC and related methods significantly improve closed-loop performance by imitating well-behaved expert strategies. Due to the differences between expert strategies and learned strategies, several papers have suggested aggregating strategy data during training to improve generalization.
A significant turning point for end-to-end autonomous driving occurred in 2021. Within reasonable computational budgets and with various sensor configurations, attention has focused on combining more modalities and advanced architectures (e.g., Transformers) to capture global context and representative features, such as TransFuser and many variants. Coupled with deeper insights into simulation environments, these advanced designs have greatly enhanced performance on the closed-loop CARLA benchmark. To improve the interpretability and safety of autonomous driving systems, methods such as NEAT, NMP, and BDD-X explicitly incorporate various auxiliary modules to better supervise the learning process or utilize attention visualization. Recent work prioritizes generating safety-critical data, pre-training large foundational models or backbones for policy learning, and advocates for a modular end-to-end planning concept. Additionally, new and challenging CARLAv2 and nuPlan benchmarks have been introduced to promote research in this field.
Comparison with Related Surveys
This survey has distinct differences from previous related surveys. Some earlier surveys covered topics similar to those in this paper in the context of end-to-end systems. However, they did not address the new benchmarks and methods that have emerged with the recent significant transitions in the field and placed less emphasis on frontiers and challenges. The remaining previous work focused on specific themes within the field, such as imitation learning or reinforcement learning. In contrast, the authors’ survey provides up-to-date information on the latest developments and technologies in the field, covering a wide range of topics and delving into key challenges.
Contributions
In summary, this survey makes three key contributions:
-
It provides a comprehensive analysis of end-to-end autonomous driving for the first time, including high-level motivations, methods, benchmarks, etc. It advocates for designing the algorithm framework as a whole, with the ultimate goal of achieving safe and comfortable driving, rather than optimizing individual modules.
-
It extensively surveys the key challenges faced by parallel methods. Among the over 250 papers surveyed, the authors summarize major aspects and conduct in-depth analyses, including themes of generalizability, language-guided learning, causal confusion, etc.
-
It covers how to embrace the broader impacts of large foundational models and data engines.
This research roadmap and the provision of large-scale high-quality data can significantly advance the development of this field. To facilitate future research, the authors maintain an active repository that updates new literature and open-source projects.
2Methods
This section reviews the fundamental principles behind most existing end-to-end autonomous driving methods.
Imitation Learning
Imitation learning (IL), also known as learning from demonstrations, trains agents to learn optimal policies by mimicking expert behavior. IL requires a dataset that contains trajectories collected according to expert policy , where each trajectory is a sequence of state-action pairs . The goal of IL is to learn an agent policy π that matches . A significant and widely used category of IL is behavior cloning (BC), which simplifies the problem to supervised learning. Inverse optimal control (IOC), also known as inverse reinforcement learning (IRL), is another IL method that learns reward functions from expert demonstrations.
Behavior Cloning
In behavior cloning, the goal of matching the agent’s policy to the expert’s policy is achieved by minimizing the planning loss, which is a supervised learning problem on a selected dataset: . Here represents the loss function used to measure the distance between the agent’s actions and the expert’s actions.
Early applications of BC in driving tasks utilized end-to-end neural networks to generate control signals from camera inputs. Further enhancements have been proposed, such as multi-sensor inputs, auxiliary tasks, and improved expert designs, to enable BC-based end-to-end driving models to handle challenging urban driving scenarios. Behavior cloning has advantages due to its simplicity and efficiency, as it does not require handcrafted reward designs, which are crucial for RL. However, behavior cloning has some common issues. During training, behavior cloning treats each state as an independent and identically distributed sample, leading to a significant problem known as covariate shift. For general IL, several strategic approaches have been developed to address this issue. In the context of end-to-end autonomous driving, DAgger has been adopted. Another common problem with behavior cloning is causal confusion, where the imitator exploits and relies on spurious correlations between certain input components and output signals. This issue has been discussed in the context of end-to-end autonomous driving.
Inverse Optimal Control
Traditional IOC algorithms learn unknown reward functions R(s,a) in Markov decision processes (MDPs) from expert demonstrations, where the expert’s reward function can be expressed as a linear combination of features. However, in continuous high-dimensional autonomous driving scenarios, the definition of rewards is implicit and challenging to optimize.
Generative adversarial imitation learning (GAIL) is a specialized method in IOC that designs the reward function as an adversarial objective to distinguish between expert and learned policies, similar to the concept of generative adversarial networks (GANs). Recently, some works have proposed using auxiliary perception tasks to optimize cost metrics or cost functions. Since costs are an alternative representation of rewards, the authors classify these methods as belonging to the IOC domain. The cost learning framework is defined as follows: end-to-end methods combine other auxiliary tasks to learn reasonable costs c(·) and use simple non-learnable algorithms as trajectory samplers to select the cost-minimizing trajectory τ*, as shown in the diagram below.
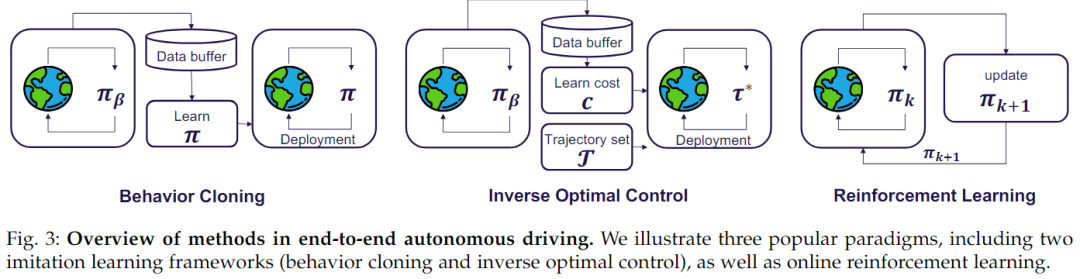
Thus, the cost learning paradigm consists of two aspects: how to design costs and how to sample trajectories for optimization in an end-to-end manner.
Regarding cost design, NMP utilizes learned cost metrics in bird’s eye view (BEV). It also conducts target detection in parallel but does not directly link costs to detection outputs. Wang et al. predict the future movements of all agents and use joint energy as interaction costs to generate final planning results. It is suggested to estimate a set of probabilistic semantic occupancy or freespace layers as intermediate representations, which provide clear cues on where vehicles should not maneuver to ensure safety. On the other hand, trajectories are typically sampled from a fixed set of expert trajectories or processed through parameter sampling of kinematic models. Then, like classical IOC methods, maximum margin loss is adopted, rewarding the lowest-cost expert demonstrations while penalizing others with higher costs.
Cost learning methods still face several challenges. In particular, to produce more realistic costs, it is often necessary to combine high-definition maps, auxiliary perception tasks, and multiple sensors, which increases the difficulty of learning and constructing multimodal multi-task framework datasets. To address this issue, MP3, ST-P3, and IVMP have abandoned the HD Map inputs used in previous works and leveraged predicted BEV maps to calculate costs based on traffic rules, such as staying close to the centerline and avoiding collisions with road boundaries. Generally, the aforementioned cost learning methods significantly enhance the safety and interpretability of autonomous vehicle decision-making, and the authors believe that industry-inspired end-to-end system design is a viable approach for real-world applications.
Reinforcement Learning
Reinforcement learning (RL) is a field of learning through trial and error. The success of deep Q-networks (DQN) in achieving human-level control on the Atari 2600 benchmark popularized deep reinforcement learning. DQN trains a neural network called the critic (or Q-network) that takes the current state and an action as input and predicts the future discounted reward of that action (when following the same policy afterward). The policy at that time is implicitly defined by selecting the action with the highest Q-value. RL requires an environment that allows for potentially unsafe operations, as it needs exploration (e.g., sometimes taking random actions during data collection). Moreover, compared to supervised learning, RL typically requires more data for training. Therefore, modern RL methods often parallelize data collection across multiple environments. Meeting these requirements in real-world vehicles poses significant challenges. Consequently, almost all papers using RL in autonomous driving have only studied simulation techniques. Most works have employed various extensions of DQN. So far, the community has not reached a consensus on specific RL algorithms.
Reinforcement learning has proven successful in learning lane-following on an empty street in a real vehicle. Despite early encouraging results, it is important to note that similar tasks were accomplished thirty years ago through imitation learning. To date, no reports have shown that results from using RL for end-to-end training are competitive with those from imitation learning. In a direct comparison conducted alongside the release of the CARLA simulator, reinforcement learning lagged far behind modular pipelines and end-to-end imitation learning. The reason for this failure may be that the gradients obtained through RL are insufficient to train the deep perception architectures required for driving (ResNet scale). The modules used in successful Atari and similar benchmarks are relatively shallow, consisting of only a few layers.
When combined with supervised learning, reinforcement learning has been successfully applied to autonomous driving. Implicit affordances and GRI both utilize supervised learning and auxiliary tasks such as semantic segmentation and classification to pre-train the CNN encoder portions of their architectures. In the second phase, the pre-trained encoder is frozen, and a shallow policy head is trained on the implicit affordance from the frozen image encoder using modern versions of Q-learning. At the time of writing, both works reported state-of-the-art performance on the CARLA leaderboard. Reinforcement learning has also been successfully applied to fine-tune complete architectures on CARLA that were pre-trained using imitation learning.
RL has effectively been applied to planning or control tasks where the network can access privileged simulator information. In the same spirit, RL has been applied to manage autonomous driving datasets. Roach trained RL methods on BEV semantic segmentation and used that policy to automatically collect datasets for training downstream imitation learning agents. WoR adopted Q-functions and tabular dynamic programming to generate additional or improved labels for static datasets.
The future challenge for the field is to transfer findings from simulation to the real world. In RL, objectives are represented as reward functions, and most algorithms require these reward functions to be dense and provide feedback at each environmental step. Current works often use simple objectives such as moving forward and avoiding collisions, and linearly combine them. These overly simplistic reward functions have been criticized for encouraging risky behaviors. Designing or learning better reward functions remains an open question. Another direction is to develop RL algorithms capable of handling sparse rewards, thus directly optimizing relevant metrics. RL can be effectively combined with world models, although this poses specific challenges. Current autonomous driving RL solutions heavily rely on low-dimensional representations of scenes.
3Benchmarks
Autonomous driving systems require comprehensive evaluation of their reliability to ensure safety. To accommodate this, researchers must benchmark these systems using appropriate datasets, simulators, and metrics. This section describes two large-scale benchmarking approaches for end-to-end autonomous driving systems: (1) online or closed-loop evaluations in simulation, and (2) offline or open-loop evaluations on human driving datasets. The authors particularly focus on the more principled online setups and briefly summarize the integrity of offline evaluations.
Online Evaluation (Closed-Loop)
Testing autonomous driving systems in the real world is costly and carries significant risks. To address this challenge, simulation is a viable alternative. Simulators assist in rapid prototyping and testing, enabling quick iterations of ideas and providing low-cost access to a wide range of scenarios. Additionally, simulators offer reliable tools to measure performance accurately. However, their main drawback is that results obtained in simulated environments may not necessarily generalize to the real world.
Closed-loop evaluation involves building a simulated environment that mimics real-world driving conditions. Evaluating driving systems requires deploying the system in a simulated environment and measuring its performance over time. The system must safely navigate simulated traffic while progressing toward a specified target location. Developing such evaluation simulators primarily involves three sub-tasks: parameter initialization, traffic simulation, and sensor simulation. The authors briefly introduce these sub-tasks below and summarize currently available closed-loop benchmark open-source simulators.
Parameter Initialization
Simulation provides the benefit of high control over the environment, including weather and lighting conditions, maps, and 3D resources, as well as low-level attributes such as the arrangement and pose of simulated entities in traffic scenes. Although powerful, the number of these parameters is vast, leading to a challenging design problem. Current simulators address this issue in two ways:
Procedural Generation: Traditionally, initial parameters are manually adjusted by 3D artists and engineers, known as procedural generation. Each prop is typically sampled from a probability distribution with manually set parameters, which is a time-consuming process requiring substantial expertise. Nevertheless, this remains one of the most commonly used initialization methods. Procedural generation algorithms combine rules, heuristics, and randomization to create diverse road networks, traffic modalities, lighting conditions, and simulation layouts.
Data-Driven: Data-driven methods for simulation initialization aim to learn the required parameters. Arguably, the simplest data-driven initialization method is to sample directly from real-world driving data logs. In this approach, parameters such as road maps or traffic modalities are extracted directly from pre-recorded datasets. The advantage of log sampling is that it can capture the natural variations present in real-world data, resulting in more realistic simulated scenarios than procedural generation. However, it may not include rare or extreme situations that are crucial for testing the robustness of autonomous driving systems. Initial parameters can be optimized to increase the representation of such scenarios. Another advanced data-driven initialization method is generative modeling, which leverages machine learning algorithms to learn the underlying structure and distribution of real-world data. These algorithms can then generate new scenarios that resemble the real world but are not included in the original data.
Traffic Simulation
Traffic simulation involves generating and positioning virtual entities in an environment with realistic motion. These entities typically include vehicles (such as trucks, cars, motorcycles, bicycles, etc.) and pedestrians. Traffic simulators must consider the effects of speed, acceleration, braking, obstacles, and the behavior of other entities. Additionally, the states of traffic lights must be updated regularly to simulate real urban driving. The authors will describe two popular traffic simulation methods below.
Rule-Based: Rule-based traffic simulators use predefined rules to generate the motion of traffic entities. This approach is straightforward to implement but may produce less realistic motion. The most prominent implementation of this concept is the Intelligent Driver Model (IDM). IDM is a following model that calculates the acceleration of each vehicle based on its current speed, the speed of the vehicle ahead, and the desired safety distance. Although widely used, IDM may not capture the complex interactions present in urban environments.
Data-Driven: Real human traffic behavior is highly interactive and complex, involving lane changes, merging, sudden stops, etc. To model such behavior, data-driven traffic simulation leverages data collected from real-world driving. These models can capture more nuanced and realistic behaviors but require a substantial amount of labeled data for training. Various learning-based techniques have been developed for this task.
Sensor Simulation
Sensor simulation is crucial for evaluating end-to-end autonomous driving systems. This involves generating simulated raw sensor data, such as camera images or LiDAR scans that the driving system will receive from different viewpoints in the simulator. This process must consider noise and occlusion to accurately assess the performance of the autonomous driving system. The literature on sensor simulation has two branches, as described below.
Graphics-Based: Recent computer graphics simulators use 3D models of the environment, along with models of vehicles and traffic entities, to generate sensor data through approximations of the physical rendering process in sensors. For example, when simulating camera images, this can account for occlusions, shadows, and reflections present in real-world environments. However, the realism of graphics-based simulation is often poor or comes at the cost of extremely heavy computation, making parallelization highly meaningful. It is closely related to the quality of 3D models and the approximations used in sensor modeling. A comprehensive review of graphics-based driving data rendering is provided in.
Data-Driven: Data-driven sensor simulation utilizes and adjusts real-world sensor data to create a new simulation where the movements of the self-vehicle and background traffic may differ from those in the original data. A popular approach is to use neural radiance fields (NeRF), which can generate new views of a scene by learning implicit representations of scene geometry and appearance. These methods can produce more realistic sensor data than graphics-based methods, but they have limitations, such as long rendering times or the need for independent training for each reconstructed scene. Another data-driven method for sensor simulation is domain adaptation, which aims to minimize the distribution shift between real and graphics-based simulated sensor data. Machine learning techniques, such as GANs or style transfer, can be used to enhance realism.
Benchmarks
The authors briefly summarize the latest driving benchmarks in Table 1.

In 2019, the original benchmark released by CARLA addressed the issue with near-perfect scores. The subsequent NoCrash benchmark involved training on a CARLA town (Town01) under specific weather conditions and testing for generalization to another town and a set of weather conditions. The Town05 benchmark involved training on all available towns in CARLA rather than a single town, while reserving Town05 for testing. Similarly, Town02 and Town05 were reserved for testing to increase the diversity of test routes. Roach expanded to an environment with three test towns, although all were seen during training and did not include safety-critical scenarios used in Town05 and LAV. Finally, the Longest6 benchmark used six test towns. Two online submission servers for CARLA agents are called leaderboards (v1 and v2), available on. The leaderboard ensures fair comparisons by keeping evaluation routes confidential. The leaderboard v2 is particularly challenging due to its long route lengths (averaging over 8 km compared to 1-2 km for v1) and a variety of new traffic scenarios. No methods have been benchmarked yet.
Due to the lack of publicly available sensor data and corresponding sensor simulation aspects, end-to-end systems currently do not have access to the nuPlan simulator. However, there are two existing benchmarks where agents can directly input available maps and simulation properties through nuPlan’s data-driven parameter initialization. The Val14 proposed uses the publicly accessible validation split of nuPlan. The leaderboard is a submission server tested on a private test set for the 2023 nuPlan challenge. Unfortunately, this is no longer publicly available for submissions.
Offline Evaluation (Open-Loop)
Open-loop evaluation involves assessing the performance of the system based on pre-recorded expert driving behavior. This method requires an evaluation dataset that includes (1) sensor readings, (2) target positions, and (3) corresponding future driving trajectories, typically obtained from human drivers. Given sensor inputs and target positions from the dataset, the performance is measured by comparing the predicted future trajectories of the system with the trajectories of humans in driving logs. The evaluation of the system is based on the degree of alignment between its trajectory predictions and human ground truth, as well as auxiliary metrics such as collision probabilities with other agents. The advantage of open-loop evaluation is that it is easy to implement and does not require a simulator, allowing access to real traffic and sensor data. However, a critical drawback is that it cannot measure the system’s performance in the actual test distribution encountered during deployment. During testing, the driving system may deviate from the expert driving lane, and validating the system’s ability to recover from such drift is crucial. Additionally, the distance between predicted trajectories and observed trajectories is not an appropriate metric for performance in multimodal scenarios. For instance, in the case of merging into a turning lane, both immediate and delayed merging options are equally valid, but open-loop evaluation penalizes options not observed in the data. Similarly, predicted trajectories may depend on observations that are only available in the future, such as stopping at a traffic light that is still green but will soon turn red, which cannot be evaluated with a single ground truth trajectory.
This method requires a comprehensive simulation dataset. For this purpose, the most popular datasets include nuScenes, Argoverse, Waymo, and nuPlan. All these datasets contain a wealth of annotated trajectories from real-world driving environments with varying degrees of difficulty. However, due to the aforementioned drawbacks, open-loop results do not provide conclusive evidence of improvements in driving behavior in closed-loop settings. Overall, if feasible and applicable, it is recommended to adopt realistic closed-loop benchmarks in future research.
4Challenges
Input Modalities
Multi-Sensor Fusion
Despite early works [3, 8] successfully accomplishing simple autonomous driving tasks, such as using monocular tracking for lane following, this single input modality is insufficient for handling complex scenarios. Therefore, a variety of sensors have been introduced and equipped on recent autonomous vehicles, as shown in the diagram below.
In particular, RGB images from cameras naturally replicate how humans perceive the world through rich semantic visual information; LiDAR or stereo cameras provide precise 3D spatial knowledge. Moreover, additional inputs such as speed and acceleration from odometers and IMUs, as well as high-level navigation commands, serve to guide end-to-end systems. However, the various sensors have different perspectives and data distributions, and the significant gap between them poses a tremendous challenge for effectively fusing them to complement autonomous driving. Multi-sensor fusion has primarily been discussed in perception-related domains, such as simulated detection, tracking, and semantic segmentation, typically categorized into three groups: early, mid, and late fusion. End-to-end autonomous driving algorithms explore similar fusion schemes. Early fusion means combining inputs before feeding the perceptual information into a feature extractor. Connections are common ways to fuse various inputs, such as images and depth, BEV point clouds and HD maps, etc., and then processed using a shared feature extractor. Points are drawn on BEV to match the size of perspective images and are combined as inputs. To address view discrepancies, some works have attempted to project point clouds onto 2D images or add an additional channel to each LiDAR point by predicting semantic labels in the image beforehand. On the other hand, late fusion schemes combine multiple results from multimodal inputs. Due to their poorer performance, they are rarely discussed.
In contrast to these methods, mid-fusion achieves multi-sensor fusion within the network by encoding inputs separately and then combining them at the feature level. Simple concatenation is often used to fuse features from different modalities. Recently, some works have adopted Transformers to model interactions between feature pairs. Transfuser uses two independent convolutional encoders to process image and LiDAR inputs, interconnecting each feature solution with a Transformer encoder, achieving four-stage feature fusion. Self-attention layers are used to focus on sensor tokens, attend to regions of interest, and update information from other modalities. MMFN further combines OpenDrive maps and radar inputs on top of the Transformer. A level-one Transformer encoder architecture is adopted to fuse various features after the last encoder block. Attention mechanisms have shown great effectiveness in aggregating contextual information from different sensor inputs and achieving safer end-to-end driving performance.
Different modalities often increase the field of view and perception accuracy, but fusing them to extract key information for end-to-end autonomous driving requires further exploration. Crucially, modeling these modalities in a unified space, such as BEV, identifying context relevant to policies, and discarding irrelevant perceptual information are essential. Additionally, fully leveraging powerful Transformer architectures remains a challenge. Self-attention layers interconnect all tokens to freely model regions of interest, but they incur significant computational costs and do not guarantee useful information extraction. More advanced Transformer-based multi-sensor fusion mechanisms in the perception domain are expected to apply to end-to-end driving tasks.
Language as Input
When humans drive cars, they use visual perception and intrinsic knowledge, such as traffic rules and desired routes, which collectively form causal behavior. In some areas related to autonomous driving, such as robotics and indoor navigation (also known as embedded AI), significant progress has been made in using natural language as fine-grained instructions to control visual motion agents. However, compared to indoor robotic applications, outdoor autonomous driving tasks present different characteristics:
(1) Outdoor environments are unknown, and vehicles cannot explore back and forth.
(2) There are few unique landmarks, which poses significant challenges for foundational language teaching.
(3) Driving scenarios are much more complex, with continuous action spaces and highly dynamic agents.
Safety is paramount in the manipulation process. To incorporate linguistic knowledge into driving behavior, the Talk2Car dataset provides a benchmark for locating reference simulations in outdoor environments. Tasks such as visual language navigation using Google Street View are introduced in datasets like Talk2Nav, TouchDown, and Map2Seq. They model the world as a discrete connected graph and require navigation to a target in a node selection format. HAD first adopts human suggestions to vehicles and adds visual-based tasks with an LSTM-based controller. Sriram et al. encode natural language instructions into high-level behaviors, including left turn, right turn, no left turn, etc., and validate their language-guided navigation methods in the CARLA simulator. They address low-level real-time control issues by focusing on text operation requirements. Recently, CLIP-MC and LM Nav leverage CLIP, benefiting from large-scale visual-language pre-training, to extract linguistic knowledge from structures and visual features from images. They demonstrate the advantages of pre-trained models and provide an attractive prototype for solving complex navigation tasks in multimodal models.
Although attempts to use CLIP for landmark feature extraction have been successful, the application of large language models (LLMs) like GPT-3 or guiding language models like ChatGPT in autonomous driving remains unclear. Modern LLMs provide more opportunities for processing complex linguistic instructions. However, given their long and unstable reasoning times, determining the interactive modalities for road applications is also crucial. Additionally, current language-guided navigation works validate their effectiveness in simulations or specific robotic implementations and lack large-scale benchmarks that include meaningful language prompts.
Visual Abstraction
End-to-end autonomous driving systems roughly complete manipulation tasks in two stages: encoding the state space into latent feature representations and then decoding driving strategies using intermediate features. In urban driving scenarios, the input states, namely the surrounding environment and self-states, are more diverse and high-dimensional compared to common reinforcement learning benchmarks like video games. Therefore, it is beneficial to pre-train the network’s visual encoder using agent pre-training tasks. This enables the network to effectively extract useful driving information, facilitating the subsequent strategy decoding phase while meeting memory and model size constraints for all end-to-end algorithms. Furthermore, this can improve the sampling efficiency of RL methods.
The process of visual abstraction or representation learning typically involves certain inductive or prior information. To achieve more compact representations than raw images, some methods directly utilize semantic segmentation masks from pre-trained segmentation networks as input representations for subsequent policy training. SESR encodes segmentation masks into class disentangled representations via VAE, further enhancing this. In another study, predicted green indicators, such as traffic light states, speed, offset to the lane center, danger indicators, and distances to leading vehicles, were used as representations for policy learning.
Having observed that segmenting or affording as a representation can lead to human-defined bottlenecks and loss of useful information, some have utilized intermediate latent features from pre-training tasks as effective representations. PIE-G has demonstrated that the early layers of ImageNet pre-trained models can serve as effective representations. Some articles use latent representations pre-trained through tasks including semantic segmentation and/or affordance prediction as inputs for RL training, achieving excellent performance. In another study, attention maps and depth maps obtained from segmented diffusion boundaries enhance latent features in VAEs to highlight important areas. PPGeo learns effective representations in an unsupervised manner through motion prediction and depth estimation on unlabeled driving videos. TARP utilizes data from a series of prior tasks to perform different task-related prediction tasks to acquire useful representations. In another work, latent representations are learned via approximating π-bisimulation metrics, which consist of differences in rewards and outputs of dynamic models. In addition to these supervised prediction pre-training tasks, another approach has adopted unsupervised contrastive learning based on enhanced views. ACO further adds steering angle discrimination to the contrastive learning structure.
As current methods primarily rely on manually defined pre-training tasks, there inevitably exists a potential information bottleneck in representation learning, which may include redundant information unrelated to driving decisions. Therefore, how to better extract key information for driving strategies during representation learning remains an open question.
World Models and Model-Based RL
Besides being able to better abstract perceptual representations, end-to-end models must also make reasonable predictions about the future to adopt safe strategies. In this section, the authors primarily discuss the challenges of current model-based policy learning works, where world models provide explicit future predictions for policy models.
Deep reinforcement learning often faces the challenge of high sample complexity, which is particularly evident in tasks like autonomous driving due to the large sample space. Model-based reinforcement learning (MBRL) offers a promising direction for improving sample efficiency by allowing agents to interact with learned world models instead of the actual environment. MBRL methods explicitly model world models/environment models, which consist of transition dynamics and reward functions, and agents can interact with them at low cost. This is particularly beneficial for autonomous driving, as 3D simulators like CARLA are relatively slow.
Modeling the highly complex and dynamic environments in driving is a challenging task. To simplify the problem, Chen et al. assume that the world is on a track, decomposing transition dynamics into non-reactive world models and simple kinematic self-vehicle models. They enrich the labels of static datasets by utilizing this factorized world model and reward function to optimize better labels through dynamic programming. In another study, probabilistic sequential latent models are used as world models to reduce the sample complexity of RL learning. To address the potential inaccuracies in learning world models, ensembles of multiple world models are employed to provide uncertainty assessments. Based on uncertainty, imaginative rollouts between world models and policy agents may be truncated and adjusted accordingly. Inspired by successful MBRL models like Dreamer, ISO Dream considers non-deterministic factors in the environment and decouples visual dynamics into controllable and uncontrollable states. Then, the policy is trained on disentangled states while explicitly considering uncontrollable factors (such as the motion of other agents).
It is noteworthy that learning world models in the raw image space is not suitable for autonomous driving. Important small details, such as traffic lights, can easily be overlooked in predicted images. To address this, MILE incorporates world models into BEV semantic segmentation space. It combines world modeling with simulation learning by adopting Dreamer-style world model learning as an auxiliary task. SEM2 also extends the Dreamer architecture but uses BEV segmentation maps and trains using RL. In addition to directly using MBRL to learn world models, DeRL combines a model-free actor-critic framework with world models. Specifically, learning world models provides self-assessment of current actions and combines it with the critic’s state value to better understand the performance of the “actor.”
End-to-end autonomous driving world model learning (MBRL) is an emerging and promising direction, as it significantly reduces the sample complexity of RL, and understanding the world aids in driving. However, due to the highly complex and dynamic nature of driving environments, further research is needed to determine what needs to be modeled and how to model the world effectively.
Multi-Task Learning with Policy Prediction
Multi-task learning (MTL) involves jointly performing multiple related tasks based on shared representations through separate branches/heads. MTL significantly reduces computational costs by using a single model for multiple tasks. Additionally, relevant domain knowledge is shared in the shared model, allowing for better utilization of task relationships to improve the generalization and robustness of the model. Therefore, MTL is particularly suitable for end-to-end autonomous driving, where the final policy prediction requires a comprehensive understanding of the current environment.
Compared to common visual tasks that require dense predictions, end-to-end autonomous driving predicts sparse signals. Here, sparse supervision poses challenges for extracting useful information from input encoders for decision-making. For image inputs, auxiliary tasks such as semantic segmentation and depth estimation are commonly employed in end-to-end autonomous driving models. Semantic segmentation ensures that the model gains a high-level understanding of the scene and identifies different categories of simulations; depth estimation enables the model to understand the 3D geometry of the environment and better estimate distances to key simulations. By performing these tasks, image encoders can better extract useful and meaningful feature representations for subsequent planning. In addition to auxiliary tasks for perspective images, 3D simulation detection is also applicable to LiDAR encoders. As BEV becomes a natural and popular representation for autonomous driving, tasks such as HD map mapping and BEV segmentation are included in models that aggregate features in the BEV space. Furthermore, in addition to including these visual tasks as multi-tasking, predicting visual affordances, including traffic light states, distances to intersections, and distances to opposing lanes, is also included.
Multi-task learning for end-to-end autonomous driving has proven effective in enhancing performance and providing interpretability for autonomous driving models. However, the optimal combination of auxiliary tasks and the appropriate weighting of their losses for achieving optimal performance remain to be explored. Additionally, constructing large-scale datasets with various types of alignments and high-quality annotations is a significant challenge.
Policy Distillation
Since imitation learning or its primary sub-category, behavior cloning, merely mimics expert behavior through supervised learning, corresponding methods typically follow a “teacher-student” paradigm. Teachers, such as handcrafted expert drivers provided by CARLA, have access to the ground truth states of surrounding agents and map elements, while students are directly supervised by collected expert trajectories or control signals through raw sensor inputs. This presents a significant challenge for student models, as they must not only extract perceptual features but also learn driving strategies from scratch.
To address the above difficulties, some studies suggest dividing the learning process into two stages: first training a teacher network and then distilling the policy into the final student network. In particular, Chen et al. first use privileged agents to learn how to access environmental states directly. They then allow the sensory motion agents (student network) to closely mimic the privileged agents, distilling during the output stage. With a more compact BEV representation as input for the privileged agents, it provides stronger generalization and supervision compared to the raw expert. The process is illustrated in the diagram below.
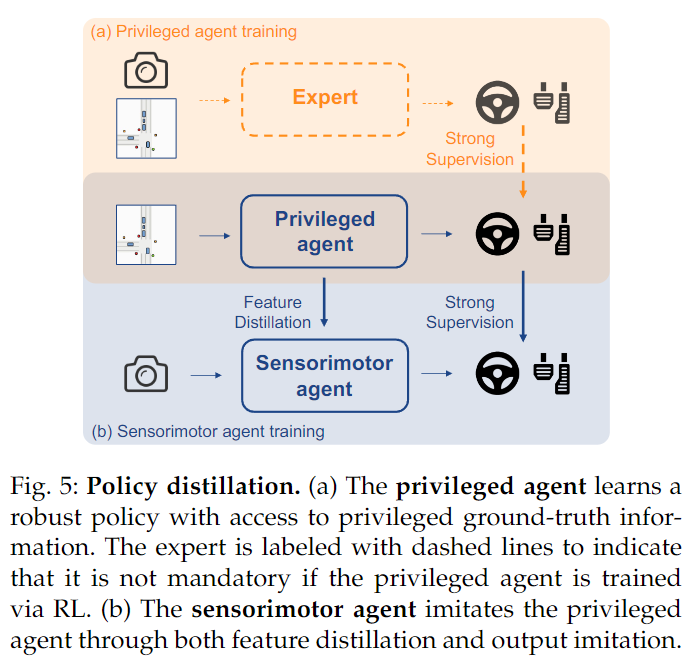
LAV further enables privileged agents to predict the trajectories of all nearby vehicles and extracts this capability into the student network using visual features.
In addition to directly supervising planning results, some works also train their prediction models by extracting knowledge at the feature level. For instance, FM-Net adopts off-the-shelf networks, including segmentation and optical flow models, as auxiliary teachers to guide feature training. SAM increases the L2 feature loss between teacher and student networks, where the teacher network predicts control signals from basic factual semantic segmentation maps and stops intention values. WoR learns a model-based action value function and then uses it to supervise visual motion policies. CaT recently introduced BEV safety prompts in the training of privileged experts based on IL and extracts them in the BEV space for feature alignment. Roach proposed training stronger privileged experts with RL, eliminating the limits of imitation learning. It incorporates multiple distillation objectives, including action distribution prediction, value estimation, and latent features. By leveraging powerful RL experts, TCP achieved new state-of-the-art performance on the CARLA leaderboard with monocular visual inputs.
Despite significant efforts to design a more robust expert and transfer knowledge from teachers to students at different levels, the teacher-student paradigm remains affected by inefficient distillation. As all previous works have shown, visual motion networks exhibit substantial performance gaps compared to privileged agents. For example, privileged agents have access to the ground truth states of traffic lights, which are small simulations in images, posing challenges for extracting corresponding features. This may lead to causal confusion for students. Therefore, exploring how to draw more inspiration from general distillation methods in machine learning to minimize this gap is worth investigating.
Interpretability
Interpretability plays a crucial role in autonomous driving. It enables engineers and researchers to better test, debug, and improve systems, provides performance assurances from a societal perspective, increases user trust, and facilitates public acceptance. However, achieving interpretability in end-to-end autonomous driving models (often referred to as black boxes) is a challenge. Given a trained autonomous driving model, some post-hoc X-AI (explainable AI) techniques can be applied to the learned model to obtain saliency maps. Saliency maps highlight specific areas in the visual input that the model primarily relies on for planning. However, this approach provides limited information, and its effectiveness and validity are difficult to assess. In contrast, the authors focus on autonomous driving frameworks that directly enhance interpretability in model design. The authors will introduce each category of interpretability in the diagram below.
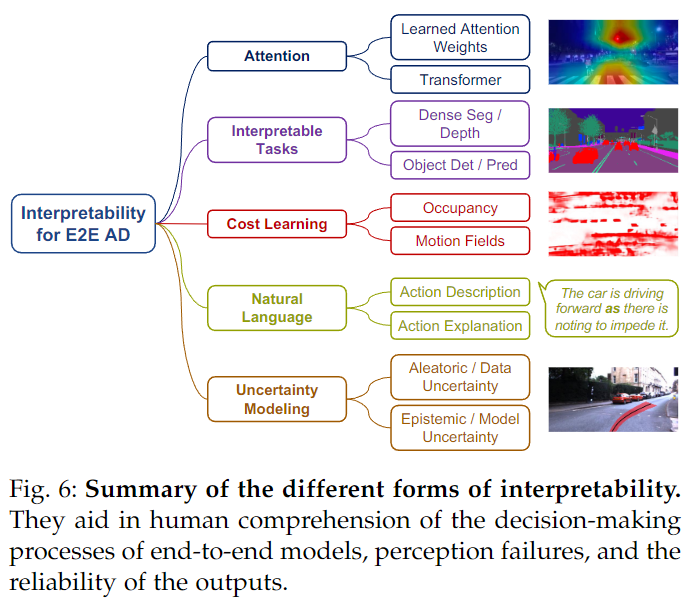
Attention Visualization: Attention mechanisms often provide a certain degree of interpretability. In one study, learned attention weights are applied to aggregate important features from intermediate feature maps. Learning attention weights to adaptively combine ROI pooling features from different simulated regions or fixed grids. NEAT iteratively aggregates features to predict attention weights and refines aggregated features. Recently, the Transformer attention mechanism has been widely adopted in many autonomous driving models. Some articles have employed Transformer attention blocks to better aggregate information from sensor inputs, with attention maps showing important areas in the input for driving decisions. In PlanT, attention layers process features from different scenarios to provide interpretable insights for corresponding actions. Similar to post-hoc saliency methods, although the acquired attention maps can provide some direct clues about the model’s focus, their fidelity and practicality remain limited.
Explainable Tasks: In deep driving models, inputs are initially encoded into intermediate representations for subsequent predictions. Therefore, many IL-based works introduce interpretability by decoding latent feature representations into other meaningful information, such as semantic segmentation, depth estimation, simulated detection, affordance prediction, motion prediction, and gaze estimation. Although these methods provide interpretable information, most methods treat these predictions merely as auxiliary tasks, having no explicit influence on final driving decisions. Some do use these outputs for final driving actions, but they are only used for performing additional safety checks.
Cost Learning: As mentioned earlier, cost learning-based methods share some similarities with traditional modular autonomous driving systems, thus exhibiting a certain degree of interpretability. NMP and DSDNet combine detection and motion prediction results to construct cost volumes. P3 combines predicted semantic occupancy maps with comfort and traffic rule constraints to construct cost functions. Various representations, such as probabilistic occupancy and time motion fields, emergency occupancy, and freespace, are used to score sampled trajectories. Explicitly incorporating factors such as safety, comfort, traffic rules, and routes based on perception and prediction outputs into constructing cost metrics.
Language Interpretability: Since one aspect of interpretability is to help humans understand systems, natural language is a suitable choice to achieve this goal. Kim et al. generated the BDD-X dataset, pairing driving videos with descriptions and explanations. They also proposed an autonomous driving model with a vehicle controller and explanation generator, enforcing spatial attention weights alignment between the two modules. BEEF proposed an explanation module that fuses predicted trajectories and intermediate perception features to predict adjustments in decisions. Some articles introduced a dataset called BBD-OIA, which includes annotations of driving decisions and explanations for high-density traffic scenarios. Recently, ADAPT proposed a Transformer-based network to jointly estimate actions, narratives, and reasoning based on driving videos from the BBD-X dataset. Given the recent advancements in multimodal and foundational models, the authors believe that further integrating language with autonomous driving models holds promise for achieving excellent interpretability and performance, as previously mentioned.
Uncertainty Modeling: Uncertainty is a quantitative method for interpreting the reliability of model outputs. Since planning results are not always accurate or optimal, designers and users must identify uncertain situations for improvement or necessary interventions. For deep learning, there are two types of uncertainty: prior uncertainty and epistemic uncertainty. Aleatory uncertainty is inherent to the task, while epistemic uncertainty arises from limited data or modeling capabilities. In one study, uncertainty in end-to-end autonomous driving systems was quantitatively assessed, utilizing certain stochastic regularizations in the model to perform multiple forward passes as samples to measure uncertainty. However, the requirement for multiple forward passes is not feasible in real-time scenarios. RIP proposed capturing epistemic uncertainty using ensembles of expert likelihood models and aggregating results to perform safe planning. Regarding methods for modeling arbitrary uncertainty, some studies explicitly predicted driving behavior/planning and uncertainty (typically represented by variance). For predicted uncertainty, the lowest uncertainty output is selected from multiple outputs, while a weighted combination is generated for suggested actions. VTGNet did not directly use uncertainty for planning but demonstrated that modeling uncertainty in data can enhance overall performance. Currently, predicted uncertainty is mainly combined with hard-coded rules. Exploring better methods to model and leverage uncertainty in autonomous driving is necessary.
Causal Confusion
Driving is a task that exhibits temporal stability, making past movements reliable predictors of the next action. However, methods that train on multiple frames may overly rely on this shortcut and suffer catastrophic failures during deployment. In some works, this problem is referred to as the imitation problem, manifesting as causal confusion, where accessing more information leads to performance degradation. LeCun et al. were among the earliest reporters on this impact. They used single input frames to guide predictions to avoid such inferences. Although overly simplistic, this remains the preferred solution in current state-of-the-art imitation learning methods [22, 28, 29]. Unfortunately, the disadvantage of using single frames is the inability to capture the speed of surrounding obstacles. Another cause of confusion is speed measurement. The diagram below illustrates an example of a car waiting at a red light.
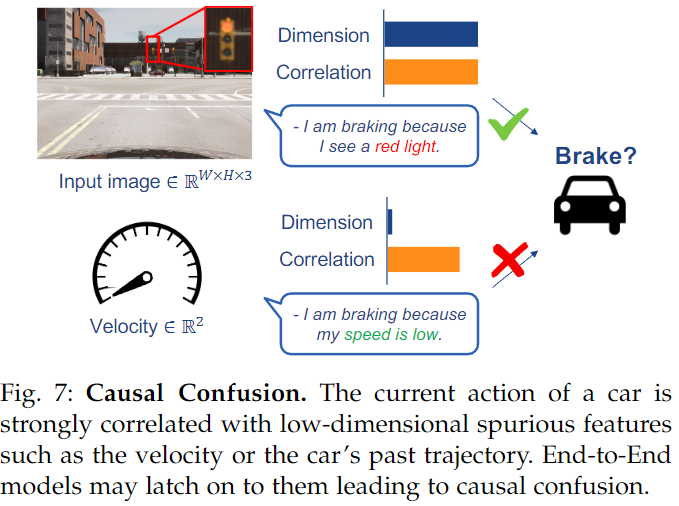
The speed of the car is highly correlated with braking actions, as the car waits for many frames with a speed of zero, while the braking action corresponds to braking. This correlation only breaks at the single frame where the traffic light changes from red to green. When using multiple frames, various methods can address the causal confusion problem. Chauffer-Net addresses this issue by using intermediate visual abstractions in BEV. An abstraction is the past of the self-vehicle, while others do not contain this information. During training, the past actions of the self-vehicle are dropped with a 50% probability. However, this approach requires explicit abstractions to work effectively. In another study, the authors attempted to remove spurious temporal correlations from learned intermediate bottleneck representations by training adversarial models to predict the past actions of the self-vehicle. This led to a min-max optimization problem, where imitation loss is minimized, and adversarial loss is maximized. Intuitively, this trains the network to eliminate its past from intermediate layers. This method works well in MuJoCo but does not scale to complex vision-based driving. The first work to study driving complexity was. They suggested increasing the weight of key frames in training losses. Key frames are frames where decisions change (thus cannot be predicted by inferring the past). To find key frames, they trained a policy that predicts actions using only the past of the self-vehicle as input. Compared to key frames, PrimeNet improves performance by using ensembles, where predictions from single-frame models serve as additional inputs for multi-frame models. Zhuang et al. did something similar, but supervised multi-frame networks with action residuals rather than actions. OREO maps images to discrete codes representing semantic simulations and applies random dropout masks to units sharing the same discrete codes. This helps in presenting the last action on the screen in Confounded Atari. In autonomous driving, using only historical LiDAR (single-frame images) and rearranging point clouds into the same coordinate system can avoid the issue of causal confusion. This removes information about self-motion while retaining information about the past states of other vehicles. This technique has been used in multiple works, although its motivation was not.
Causal confusion has been a persistent challenge in imitation learning for nearly two decades. In recent years, significant researchers have begun to investigate this issue. However, these studies used modified environments to simplify the study of causal confusion problems. Demonstrating performance improvements in state-of-the-art environments remains an open question.
Robustness
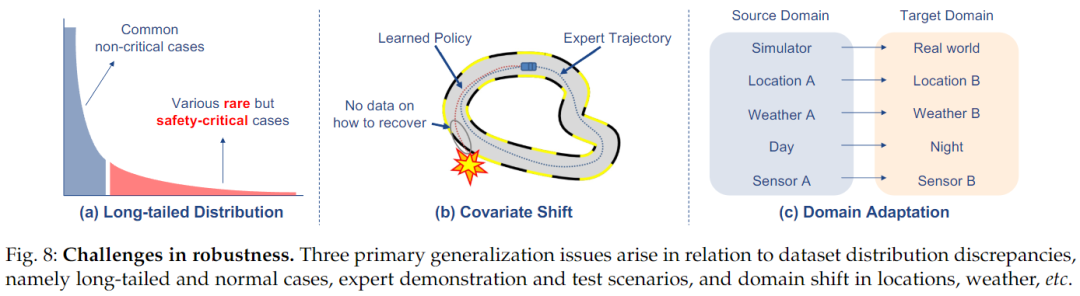
Long-Tail Distribution
An important aspect of the long-tail distribution problem is dataset imbalance, where minority classes dominate while many other classes have limited sample sizes, as illustrated in the diagram below.
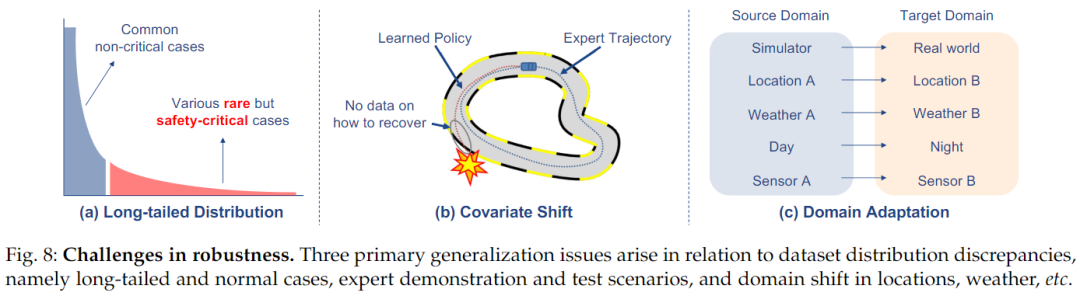
This presents significant challenges for the model to generalize to various environments. Various methods address this issue through data processing, including oversampling, undersampling, and data augmentation. Additionally, weighting-based methods are often used to alleviate dataset imbalance issues.
In the context of end-to-end autonomous driving, the long-tail distribution problem is particularly severe. Dataset imbalance is especially problematic in driving datasets, as most typical driving is repetitive and mundane, such as driving along a lane for many frames. In contrast, interesting safety-critical scenarios occur infrequently but are diverse in nature. To address this issue, some works rely on handcrafted scenarios to generate more diverse and interesting data in simulations. LBC utilizes privileged agents to create hypothetical super-privileges conditioned on different navigation commands. LAV considers that, although the self-vehicle used for data collection rarely experiences accidents, other human agents may have encountered some safety-critical or interesting situations. Therefore, it includes trajectories from other agents for training to promote data diversity. In another study, a simulation framework was proposed to apply importance sampling strategies to accelerate the assessment of rare event probabilities.
Another research avenue generates safety-critical scenarios in a data-driven manner through virtual attacks. In one study, Bayesian optimization was used to generate adversarial scenarios. Learning collisions represent driving scenarios as joint distributions on building blocks and apply policy gradient RL methods to generate risky scenarios. AdvSim modifies the trajectories of agents while adhering to physical realism to induce failures and updates LiDAR accordingly. Recent work KING proposed an optimization algorithm using gradients of safety-critical perturbations with different kinematic models. Overall, effectively generating realistic safety-critical scenarios that cover long-tail distributions remains a significant challenge. While many works focus on adversarial scenarios in simulators, better leveraging real-world data for critical scenario mining and potential adaptation of simulations is also crucial. Furthermore, a systematic, rigorous, comprehensive, and realistic testing framework is essential for evaluating end-to-end autonomous driving methods under long-tail distributed safety-critical scenarios.
Covariate Shift
As mentioned earlier, a significant challenge of behavior cloning is covariate shift. The state distributions of expert policies and trained agent policies differ, leading to compounded errors when the trained agent is deployed in unseen test environments or when the responses from other agents differ from those during training. This can result in the trained agent being in states outside the expert training distribution, leading to severe failures. As shown in the diagram above, DAgger (Dataset Aggregation) is a commonly used method to overcome this issue. DAgger is an iterative training process where the currently trained policy is rolled out in each iteration to collect new data, and experts label the accessed states. This enriches the training dataset by adding examples of how to recover from suboptimal states that may be accessed by imperfect policies. The policy is then trained on the augmented dataset, and the process is repeated. However, one drawback of DAgger is the need for an available expert to query online.
For end-to-end autonomous driving, DAgger is employed, equipped with MPC-based experts. To reduce the cost of continuously querying experts and improve safety, SafeDAgger extends the original DAgger algorithm by learning a safe policy that estimates the deviation between the current policy and expert policy. Experts are only queried when the deviation is significant, and in those dangerous situations, the expert takes over. MetaDAgger combines meta-learning with DAgger to aggregate data from multiple environments. LBC adopts DAgger and resamples data to sample samples with higher losses more frequently. In DARB, several modifications to DAgger are proposed to adapt it to driving tasks. To better utilize failure or safety-related samples, it proposes several mechanisms, including task-based, policy-based, and policy-expert-based mechanisms, to sample these critical states. It also uses a fixed-size replay buffer for iterative training to increase diversity and reduce dataset bias.
Domain Adaptation
Domain adaptation (DA) is a form of transfer learning where the target task is the same as the source task but the domains differ. Here, the authors discuss scenarios where labels are available for the source domain, while the target domain has limited or no labels. As illustrated in the diagram above, domain adaptation for simulated driving tasks includes several situations:
-
Simulation to Real: The significant gap between the simulator used for training and the real world used for deployment. -
Geography to Geography: Different geographic locations with different environmental appearances. -
Weather to Weather: Changes in sensor inputs caused by weather conditions such as rain, fog, and snow. -
Day to Night: Variations in lighting in sensor inputs. -
Sensor to Sensor: Potential differences in sensor characteristics, such as resolution and relative positioning.
Note that the above situations often overlap. VISRI uses translation networks to map simulated images to real images, using segmentation maps as intermediate representations. RL agents are trained based on translated simulated images. In another study, domain-invariant feature learning was achieved using image translators and discriminators to map images from two domains to a common latent space. Similarly, LUSR employs cyclic-consistent VAEs to project images into latent representations composed of domain-specific parts and domain-general parts, on which to learn policies. UAIL achieves weather-to-weather adaptation by decomposing images under different weather conditions into distinguishable style spaces and shared content spaces using GANs. In SESR, class disentangled encodings are extracted from semantic segmentation masks to reduce the domain gap between images in the simulator and the real world. Domain randomization is also a simple and effective technique for simulation-to-real adaptation in RL policy learning, further applicable to end-to-end autonomous driving systems. It is achieved by randomizing the rendering and physical settings of the simulator to cover the variability of the real world during training and obtain training strategies with good generalization capabilities. Currently, simulation-to-real adaptation through source-target image mapping or domain-invariant feature learning is a focus for end-to-end autonomous driving. Other domain adaptation scenarios, such as geography-to-geography or weather-to-weather adaptation, are addressed through the diversity and scale of training datasets. Given that LiDAR has become a popular driving input modality, specific adaptation techniques suitable for LiDAR features must also be designed, considering that current methods primarily focus on visual gaps in images. Additionally, as current methods only focus on visual gaps in images, attention should also be paid to the behavior of traffic agents and the gap in traffic rules between the simulator and the real world. Incorporating real-world data into simulations through technologies like NeRF is another promising direction.
5Future Trends
Considering the challenges and opportunities discussed, the authors outline several key directions for future research that may have broader impacts in the field.
Zero-Shot and Few-Shot Learning
Eventually, autonomous driving models will inevitably encounter real scenarios beyond the training data distribution. This raises the question of whether the authors can successfully adapt the model to an unseen target domain where limited or no labeled data is available. A key step in achieving this goal is to formalize the task within the end-to-end driving domain and incorporate relevant techniques from zero-shot/few-shot learning literature.
Modular End-to-End Planning
Modular end-to-end planning frameworks optimize multiple modules while prioritizing downstream planning tasks, which has interpretability advantages, as previously shown. This has been advocated in recent literature, and certain industry solutions (such as Tesla, Wayve, etc.) involve similar ideas. When designing these distinguishable perception modules, several questions arise regarding the selection of loss functions, such as the necessity of 3D bounding boxes for object detection, whether occupancy representations are sufficient for detecting general obstacles, or the advantages of choosing BEV segmentation over lane topology for static scene perception.
Data Engines
The importance of large-scale, high-quality data for autonomous driving cannot be overstated. Establishing a data engine with an automated annotation pipeline can greatly facilitate the iterative development of data and models. Autonomous driving data engines, especially modular end-to-end planning systems, need to streamline the process of annotating high-quality perception labels automatically with the assistance of large perception modules. They should also support mining difficult/corner cases, scene generation and editing to simplify the data-driven evaluations discussed earlier, facilitating data diversity and model generalization. Data engines will enable autonomous driving models to make consistent improvements.
Foundational Models
Recent advancements in large foundational models in language and vision have had significant impacts across various aspects of society. Leveraging large-scale data and model capabilities unlocks tremendous potential for AI in advanced reasoning tasks. Paradigms such as fine-tuning or few-shot learning, self-supervised reconstruction forms of optimization or contrastive learning, and data pipelines are applicable to the end-to-end autonomous driving domain. However, the authors believe that directly applying LLMs to autonomous driving seems inconsistent with the differing objectives of these two goals. The outputs of autonomous agents typically require stable and accurate measurements, while the generative sequence outputs in language models are designed to behave like humans, regardless of accuracy. A feasible solution for developing large autonomous driving models is to train a video predictor capable of predicting long-term predictions in 2D or 3D environments. To perform well in downstream tasks like planning, the optimization objectives for large models need to be sufficiently complex, exceeding the framework level of perception.
V2X
Occlusions and obstacles beyond the perception range are two fundamental challenges for modern computer vision technologies, which can pose significant difficulties for human drivers when they need to respond quickly to crossing targets. V2V, V2I, and V2X systems offer promising solutions to address this critical issue, where information from different perspectives supplements self-blind spots. Witnessing advancements in information transmission mechanisms in multi-agent scenarios, these systems can provide a solution for achieving advanced decision intelligence.
6Conclusion
This survey first outlines the fundamental methods of end-to-end autonomous driving and summarizes various aspects of simulation and benchmarking. It then delves into the extensive literature to highlight a series of significant challenges and promising solutions. Finally, it discusses how to adopt rapidly developing foundational models and data engines in the future. End-to-end autonomous driving simultaneously faces immense opportunities and challenges, with the ultimate goal of creating versatile systems. In this emerging technological era, it is hoped that this survey can serve as a starting point, providing new clues for this field.
7References
[1].End-to-end Autonomous Driving: Challenges and Frontiers
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of "Beginner Learning Vision" public account to download the first OpenCV extension module tutorial in Chinese, covering over twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of "Beginner Learning Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of "Beginner Learning Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
Welcome to join the public account reader group to discuss with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat number below to join the group, noting: "Nickname + School/Company + Research Direction". For example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format, otherwise, it will not be approved. Once added successfully, you will be invited into relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~