
Source: DeepHub IMBA
This article has a total of 4500 words, and it is recommended to read in 5 minutes.
This article will delve into five main types of computing accelerators.
In today’s rapidly evolving computing technology, traditional general-purpose processors (CPUs) are gradually being supplemented or replaced by dedicated hardware accelerators, especially in specific computing domains. These accelerators achieve significant optimizations in power efficiency, computational throughput (FLOPS), and memory bandwidth through targeted designs. As of April 2025, the demand for accelerators is experiencing exponential growth, primarily driven by the widespread deployment of artificial intelligence (AI), machine learning (ML), high-performance computing (HPC), and edge computing applications. This article will systematically compare five main types of computing accelerators—GPUs, FPGAs, ASICs, TPUs, and NPUs—analyzing their technical architectures, performance characteristics, application fields, and industrial ecosystems, as well as assessing the suitability of each type of accelerator in different application scenarios.
Basic Principles and Key Metrics of Hardware Accelerators
Hardware accelerators are specialized processing devices designed to offload specific computational tasks from general-purpose CPUs, achieving efficient execution through architectural optimization. Unlike CPUs that pursue generality, accelerators focus on parallel processing capabilities, low-latency responses, and energy efficiency optimization for specific computational patterns. These devices, through customized microarchitectures, are particularly suited for operations with repetitive and computation-intensive characteristics, such as matrix multiplication in deep learning or signal processing in telecommunications.Key technical metrics for evaluating accelerator performance include:
-
Computational Capability (FLOPS): The number of floating-point operations per second, directly reflecting the processor’s raw computational power in scenarios such as scientific computing and AI training.
-
Memory Bandwidth: The rate of data transfer between storage units and processing units, which often constitutes the main bottleneck in high-throughput applications.
- Energy Efficiency: The computational performance per unit of energy consumed, typically measured in FLOPS per watt or operations per joule, which is particularly important for mobile devices and edge computing.
The following sections will explore the technical architectures, performance characteristics, and practical advantages of various types of accelerators in detail.
1. Graphics Processing Units (GPUs)
Technical Architecture and Evolution
Graphics Processing Units were originally designed for accelerating graphics rendering, but due to their highly parallel processing architecture, they have evolved into the dominant platform for general-purpose computing acceleration. Modern GPUs integrate thousands of processing cores optimized for single instruction multiple data (SIMD) operations, forming a highly parallel computational matrix, particularly suited for processing large datasets that require the simultaneous execution of the same instruction.
Technical Specifications and Performance Parameters
-
Computational Performance: For example, the NVIDIA Ampere architecture A100 GPU can achieve up to 19.5 TFLOPS in double precision (FP64) computing, while performance can be boosted to 312 TFLOPS when using Tensor Cores for AI workloads.
-
Memory Bandwidth: The A100 uses HBM3 (High Bandwidth Memory) technology, providing up to 1.6 TB/s of memory bandwidth, far exceeding the DDR memory systems used by traditional CPUs.
- Power Characteristics: The power consumption at full load is approximately 400W, reflecting the energy demand characteristics of high-performance computing processors.
Technical Advantages
The core advantage of the GPU architecture lies in its large-scale parallel processing capability, with thousands of computing cores able to execute multi-threaded tasks simultaneously, greatly accelerating matrix operations and vector processing. High-bandwidth memory technology effectively alleviates data transfer bottlenecks, ensuring that computing cores can continuously receive data supply. Through parallel computing frameworks such as CUDA and OpenCL, GPUs have expanded from dedicated graphics processing to general computing, supporting a diverse range of application scenarios.
Application Fields
-
AI Model Training and Inference: GPUs dominate the deep learning field, providing foundational computing power for frameworks like TensorFlow and PyTorch, supporting the training and deployment of large-scale neural networks.
-
Scientific Computing Simulations: With their strong floating-point computation capabilities, GPUs are widely used in computationally intensive scientific research fields such as physics, chemistry, and climate simulations.
- Blockchain and Cryptographic Computing: The parallel computing architecture of GPUs is suitable for handling the repetitive hash computations required for cryptocurrency mining.
Major Manufacturers and Product Lines
-
NVIDIA: As the market leader in GPUs, it offers a range from data center-level A100, H100, H200, GB2000 to consumer-level GeForce RTX series products. Its CUDA ecosystem significantly enhances the programmability and application scalability of GPUs.
-
AMD: Competes with NVIDIA through the Instinct MI series (such as the MI300X with 141 TFLOPS FP32 performance), offering a certain advantage in cost-performance ratio.
-
Intel: In recent years, it has actively expanded the GPU market with Gaudi, Arc, and Data Center GPU Max product lines, focusing on AI acceleration and high-performance computing.
Comparison with Other Accelerators
GPUs typically outperform CPUs in parallel computing capability and raw FLOPS performance, but may not match the energy efficiency of FPGAs or ASICs for specific tasks. Their general-purpose computing architecture makes them more flexible than ASICs and TPUs, but relatively less efficient for fixed computational tasks.
2. Field-Programmable Gate Arrays (FPGAs)
Technical Architecture and Characteristics
FPGAs are integrated circuits that can be reconfigured after manufacturing, consisting of programmable logic blocks, configurable interconnects, and I/O units. Unlike fixed-architecture GPUs, FPGAs allow developers to customize hardware circuits based on specific algorithm requirements, providing a balance between flexibility and performance optimization.
Technical Specifications and Performance Parameters
-
Computational Performance: The Xilinx Versal ACAP series can provide approximately 10-20 TFLOPS of floating-point performance depending on specific configurations, but this parameter can vary significantly with logic resource allocation.
-
Memory Bandwidth: Mid-range FPGAs typically use DDR4/DDR5 interfaces to achieve bandwidths of 100-200 GB/s, while high-end models like Intel Stratix 10 with integrated HBM can reach up to 1 TB/s.
- Power Characteristics: Power consumption varies widely; mid-range FPGAs like the Xilinx Zynq UltraScale+ series consume about 10-50W under typical workloads, depending on logic resource utilization and clock frequency.
Technical Advantages
The key advantage of FPGAs lies in their reconfigurability, allowing hardware architecture optimization for new algorithms or workloads after deployment. Due to the ability to build customized data paths, FPGAs exhibit extremely low processing latency in real-time processing applications. Additionally, FPGA designs optimized for specific tasks typically have higher energy efficiency than general-purpose GPUs.
Application Fields
-
Edge Computing: With low power and low latency characteristics, FPGAs are suitable for AI inference acceleration in IoT devices such as smart cameras and sensors.
-
Telecommunications Infrastructure: Widely used in signal processing and network data packet routing for 5G base stations.
- Financial Trading Systems: Custom logic designs effectively reduce processing latency in high-frequency trading systems.
Major Manufacturers and Product Lines
-
Xilinx (AMD): Known for the Versal and Zynq series, providing heterogeneous FPGA solutions with integrated ARM processor cores.
-
Intel: Produces Stratix and Agilex series FPGAs, with some high-end models integrating HBM to meet high bandwidth application needs.
-
Lattice Semiconductor: Focuses on low-power FPGA product lines, such as the CrossLink-NX series aimed at edge computing.
Comparison with Other Accelerators
FPGAs typically have lower raw computational performance (FLOPS) than GPUs, but excel in latency-sensitive and power-constrained application environments. Compared to ASICs, FPGAs have lower energy efficiency for fixed-function tasks but significantly increased flexibility. In the absence of integrated HBM, FPGAs usually have lower memory bandwidth than high-end GPUs.
3. Application-Specific Integrated Circuits (ASICs)
Technical Architecture and Design Philosophy
ASICs are microprocessors custom-designed to perform specific functions, with their circuit structures optimized for fixed workloads, providing unparalleled execution efficiency. ASIC design sacrifices flexibility for extreme performance and energy efficiency; once manufactured, their functions are fixed.
Technical Specifications and Performance Parameters
-
Computational Performance: Google’s Edge TPU is optimized for integer operations, providing approximately 4 TOPS (trillions of operations per second) of inference performance.
-
Memory Bandwidth: Performance varies significantly; high-end ASICs like the Cerebras WSE-2 utilize innovative memory architectures to achieve up to 20 PB/s (petabytes per second) of on-chip bandwidth.
- Power Characteristics: The Edge TPU is designed for a power consumption of only 2W, suitable for edge devices, while the WSE-2, due to its large scale and high-performance requirements, has a total power consumption of about 23kW.
Technical Advantages
The greatest advantage of ASICs lies in their extreme optimization for specific computational tasks, achieving the best performance-to-power ratio. On-chip memory architectures reduce off-chip data transfers, significantly enhancing processing efficiency. New large-scale ASIC architectures like the WSE-2 can handle complex workloads that exceed the capabilities of traditional GPUs.
Application Fields
-
AI Edge Inference: For example, Google’s Edge TPU provides efficient inference capabilities for lightweight machine learning models in mobile devices.
-
Deep Learning Training: Large ASICs like the Cerebras WSE-2 accelerate the training of large-scale neural networks in data centers.
- Cryptocurrency Processing: ASICs from companies like Bitmain dominate Bitcoin mining with highly optimized hashing algorithms.
Major Manufacturers and Product Lines
-
Google: Develops the TPU and Edge TPU series, optimized for AI workloads.
-
Cerebras Systems: Pioneered wafer-scale ASIC architectures, such as the WSE-2, aimed at deep learning.
-
Bitmain: Leads in the cryptocurrency mining ASIC field, known for its Antminer series products.
Comparison with Other Accelerators
ASICs typically outperform GPUs and FPGAs in efficiency and bandwidth for their specific design tasks, but lack flexibility to adapt to algorithm changes. For general computing tasks, their raw computational performance may be lower than high-end GPUs, and high design and production costs limit their application scope, primarily focusing on large-scale deployments or specific domain applications.
4. Tensor Processing Units (TPUs)
Technical Architecture and Design Philosophy
Tensor Processing Units are a type of special ASIC developed by Google, designed to accelerate tensor operations in neural networks. TPUs find a balance between the general computing architecture of GPUs and the highly specialized nature of ASICs, achieving efficient processing through optimization of core computational patterns in machine learning.
Technical Specifications and Performance Parameters
-
Computational Performance: TPU v4 provides approximately 275 TOPS (INT8 precision) per chip, achieving exascale (ExaFLOPS) computing capabilities in large-scale cluster configurations.
-
Memory Bandwidth: The TPU v5 architecture utilizes HBM3 technology, achieving up to 1.2 TB/s of memory bandwidth per chip.
- Power Characteristics: The total power consumption of a complete TPU v4 pod cluster is about 500kW, but the energy efficiency of a single chip is high, consuming about 100W.
Technical Advantages
The core advantage of TPUs lies in their matrix multiplication units (MXUs) optimized for machine learning, enabling efficient processing of key tensor operations in neural networks. The TPU pod architecture supports interconnection of thousands of processing units, enabling large-scale parallel computing. Additionally, the deep integration of TPUs with frameworks like TensorFlow ensures optimized collaboration between hardware and software.
Application Fields
-
Cloud AI Services: Google Cloud TPU provides training and inference infrastructure for large-scale machine learning models.
-
Cutting-edge Research: Supports cutting-edge AI research projects such as AlphaGo and large language models.
-
Large-scale Data Analysis: Accelerates the processing and analysis of structured datasets.
Major Manufacturers
Google is the sole developer and manufacturer of TPUs, providing TPU computing capabilities to the market through Cloud TPU services and Edge TPU product lines.
5. Neural Processing Units (NPUs)
Technical Architecture and Design Approach
Neural Processing Units are a new type of dedicated accelerator optimized for neural network inference, typically integrated into system-on-chip (SoC) designs for mobile devices and edge computing platforms. NPU designs prioritize low-power operation and real-time inference capabilities to suit resource-constrained environments.
Technical Specifications and Performance Parameters
-
Computational Performance: The Neural Engine in Apple’s M2 chip provides approximately 15.8 TOPS of inference performance.
-
Memory Bandwidth: Typically ranges from 50-100 GB/s, primarily utilizing on-chip SRAM caches to optimize data access.
-
Power Characteristics: Extremely low power design, consuming only 1-5W under typical operating conditions, specifically optimized for battery-powered devices.
Technical Advantages
The standout advantage of NPUs lies in their ultra-low power design, making them particularly suitable for mobile devices and IoT applications. Their architecture is optimized for real-time processing, exhibiting extremely low latency in scenarios such as voice recognition and image processing. The compact design allows NPUs to be integrated as components of SoCs, effectively saving space and system costs.
Application Fields
-
Mobile Computing Platforms: The Apple Neural Engine provides local AI processing capabilities for features like Face ID and Siri.
-
Smart Driving Systems: Processes sensor data streams in autonomous vehicles.
-
Consumer Electronics: Enhances interaction experiences in AR/VR headsets and smart home devices.
Major Manufacturers and Product Lines
-
Apple: Integrates Neural Engine in A-series and M-series processors.
-
Qualcomm: Integrates Hexagon NPU in Snapdragon SoCs.
-
Huawei: Integrates self-developed Da Vinci architecture NPU in Kirin processors.
Comparison with Other Accelerators
NPUs outperform traditional GPUs and TPUs in power efficiency and processing latency, but their computational capability (FLOPS) is relatively lower, primarily targeting lightweight inference rather than training tasks. Compared to FPGAs, NPUs have lower flexibility but a higher degree of specialization for specific neural network computations.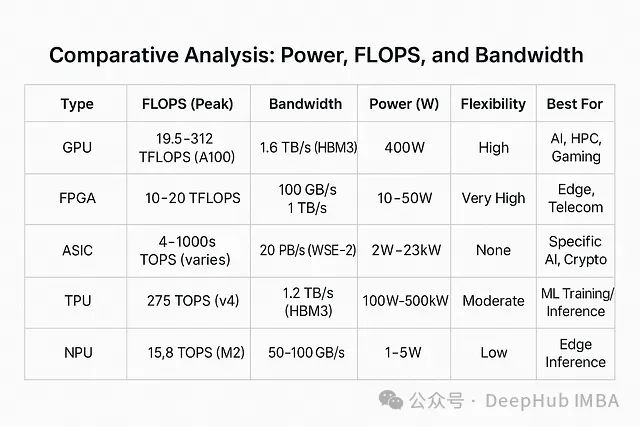
Performance Comparison and Selection Guide for Accelerators
Energy Efficiency Comparison
In terms of energy efficiency, NPUs and low-power ASICs (such as Edge TPU) lead with power consumption of less than 5W per chip, making them ideal choices for battery-powered devices and edge computing. In contrast, high-performance GPUs and large ASICs (such as WSE-2), while consuming more power, are optimized for data center environments that require extremely high computational density.
Computational Performance Comparison
In terms of raw computational capability, TPUs and high-end GPUs dominate large-scale training tasks with performance metrics in the hundreds of TFLOPS/TOPS. While FPGAs and NPUs may be relatively weaker in absolute computational capability, they possess unique advantages in efficiency and latency optimization for specific tasks.
Memory Bandwidth Comparison
In terms of memory bandwidth, new ASIC architectures like Cerebras WSE-2 achieve byte-level data transfer capabilities through innovative on-chip memory designs, redefining the performance limits of processor memory systems. In contrast, FPGAs and NPUs rely on relatively lower bandwidth memory systems, making them more suitable for processing smaller-scale tasks.
Accelerator Selection Recommendations
-
GPU: The first choice when computational flexibility and raw computational power are needed. The NVIDIA H100 is recommended for large-scale AI training, while the AMD MI300X is suitable for high-performance computing applications that prioritize cost-performance ratio.
-
FPGA: The ideal choice when applications require hardware-level customization and low-latency processing. The Xilinx Versal series excels in edge computing and telecommunications.
-
ASIC: ASICs provide unparalleled efficiency for fixed algorithms requiring extremely high throughput workloads. The Cerebras WSE-2 has significant advantages in large-scale AI research.
-
TPU: Particularly suitable for machine learning applications that require deep integration with the Google ecosystem and high scalability.
-
NPU: NPUs are the best choice for AI inference in edge devices when power consumption and size constraints are primary considerations.
Editor: Huang Jiyan
About Us
DataPi THU, as a data science public account, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for gathering data talent, creating the strongest group in China’s big data.

Sina Weibo: @DataPi THU
WeChat Video Account: DataPi THU
Today’s Headlines: DataPi THU