Author: This article is contributed by the community, authored by Wuyuhang, a learner from the Shusheng Large Model Practical Camp. This article will provide a detailed introduction to the project MultiAgent-Search, which is an image localization system based on multi-agent collaboration.
Acknowledgments
Hello everyone, I am a first-year graduate student at Shanghai University of Engineering Science. First of all, I would like to sincerely thank the Shusheng Large Model Practical Camp for giving me this valuable opportunity, and I am grateful to my mentor Xiong Yujie for her patient guidance, as well as to my classmate Zhang Henghua for his selfless help, which allowed me to successfully complete the MultiAgent-Search project.
It is particularly worth mentioning that the practical camp provided us with free course resources, model support, and computational power assistance, which is a tremendous boost for ordinary students like me. Here, I express my deep gratitude once again!
Project Related Links:
- https://github.com/InternLM/Tutorial
- https://github.com/InternLM/InternLM
- https://github.com/InternLM/agentlego
- https://github.com/InternLM/MindSearch
- https://github.com/langchain-ai/langchain
Project Overview
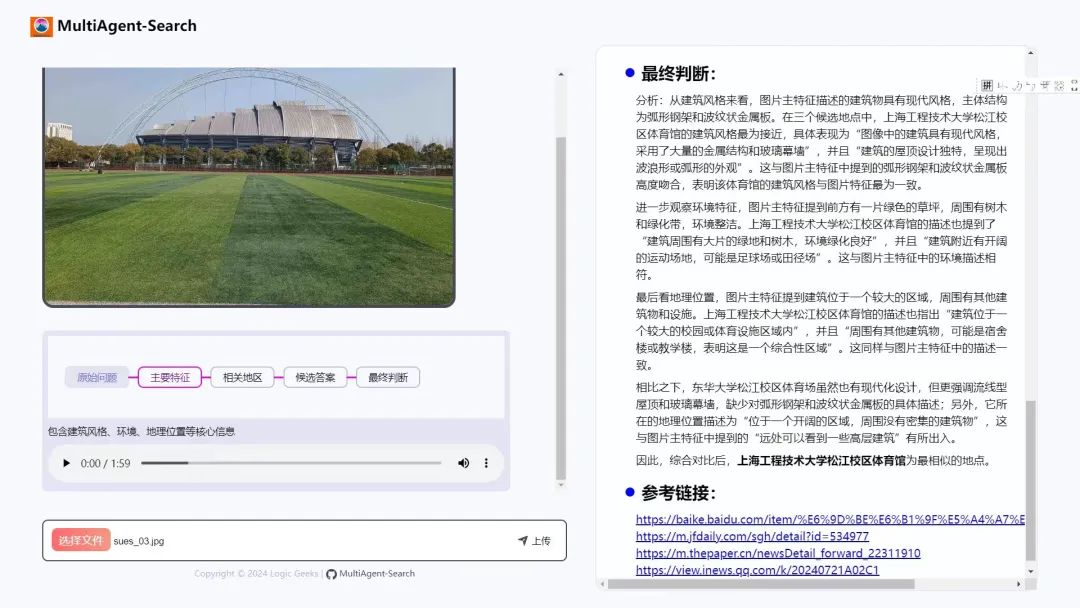
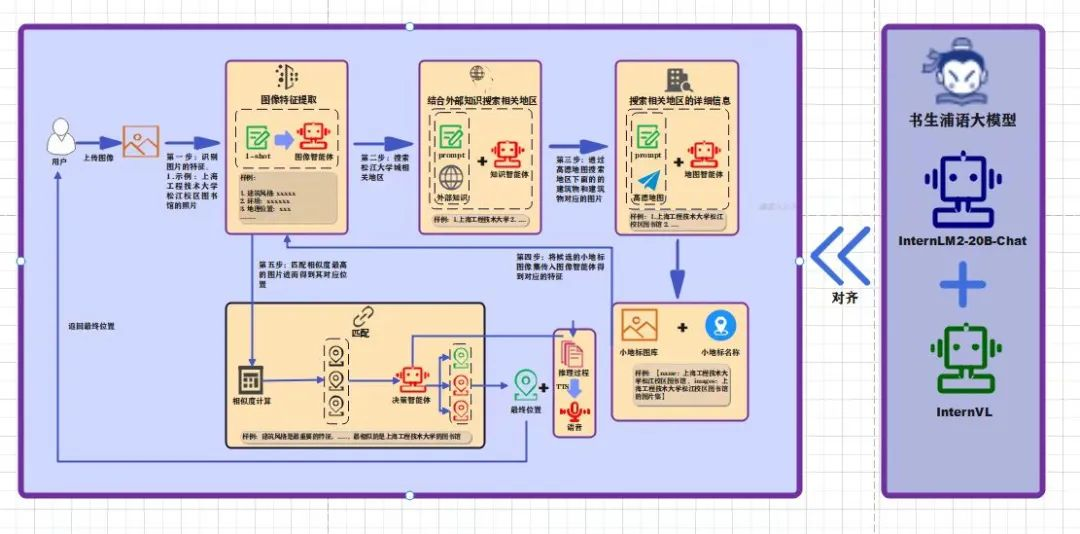
Traditional image localization technology mainly relies on computer vision (CV), determining specific locations by comparing with massive satellite images. Although this method is effective, with the development of large model technology, utilizing human understanding and reasoning capabilities regarding geographical features of images is also an excellent alternative. Therefore, I designed and developed a multi-agent-based image recognition and geographical localization system. This system can efficiently analyze various information about urban landmarks through the collaborative operation of visual analysis, knowledge integration, and decision reasoning, gradually deducing precise geographical locations.
The project has now been uploaded to GitHub, and interested friends are welcome to support it and give it a star, thank you ⭐: https://github.com/Wuyuhang11/MultiAgent-Search
(The project is still being optimized, and you can click “Read the original text” at the end to access it directly)
The following video is sourced from Shusheng Intern
Technical Implementation
Visual Agent
In the technical design of the visual agent, I adopted a few-shot learning approach, enabling it to extract important feature information from images, such as architectural styles, landmark names, and possible geographical clues. This information will provide a foundation for subsequent localization reasoning.
Knowledge Agent
The knowledge agent uses prompt engineering techniques, combining image data obtained from the visual agent, to call external geographical knowledge and relevant information from the internet for comprehensive analysis, thereby preliminarily locking in target areas in complex urban environments. Technically, this agent employs the RAG (Retrieval-Augmented Generation) framework, relying not only on internal data but also retrieving supplementary information from external knowledge bases and databases based on image features, further clarifying the location range.
Map Agent
The map agent, based on the area range provided by the knowledge agent, conducts in-depth area searches using the Gaode Map POI API, extracting image features and names of small buildings within each sub-area, and organizing them into key-value (k-v) pairs for more refined processing of geographical information.
Decision Agent and Final Results
The decision agent integrates all known information, first converting the features of small landmarks into vector representations, then calculating the similarity between features using the Euclidean algorithm to filter out the top-k candidate locations. Next, combining the adversarial ideas of Generative Adversarial Networks (GANs) and the reasoning logic of Chain of Thought (CoT), it performs final filtering to determine the geographical location that best matches the input image.
RAG Technology
RAG (Retrieval-Augmented Generation) is a technology that combines external data sources with large models to meet specific user needs.
The workflow of RAG is as follows:
- The user uploads questions and related documents;
- The documents are preprocessed, and both documents and questions are embedded through a vector model;
- Relevant information is retrieved from the vector database;
- The retrieval results are sorted and optimized;
- External knowledge is integrated with the user question as context, inputting into the downstream model to generate the final answer.
Geographical Knowledge Documents
We utilize knowledge documents related to image localization to support the reasoning of large models, thereby improving the accuracy of answers and reducing the hallucination problem of the model.

Application of AgentLego
AgentLego is an open-source multifunctional tool API library designed to enhance the capabilities of agents based on large language models (LLMs), with main features including:
- A rich multimodal toolset supporting visual perception, image generation and editing, speech processing, and visual language reasoning;
- Flexible tool interfaces that support user-defined parameters and output types;
- Seamless integration with mainstream LLM frameworks (such as LangChain, Transformers Agents, Lagent);
- Support for tool services and remote calls, especially suitable for scenarios requiring large machine learning models (such as ViT) or specific hardware environments (such as GPU and CUDA).
Example of Agent Construction: Taking the knowledge agent as an example, we load the Google search tool using the load_tool function of AgentLego (which can be replaced by Bocha AI in China), then initialize the agent using Lagent (LangChain can also be used), and execute the action chain through Lagent’s ActionExecutor. At the same time, we introduce the ReAct module, combining the language model and action executor to enhance dialogue and task execution capabilities.
Text-to-Speech (TTS): By simply loading the TTS and langid dependencies, text-to-speech conversion can be achieved through AgentLego’s TextToSpeech tool, outputting audio content.
Frontend Design
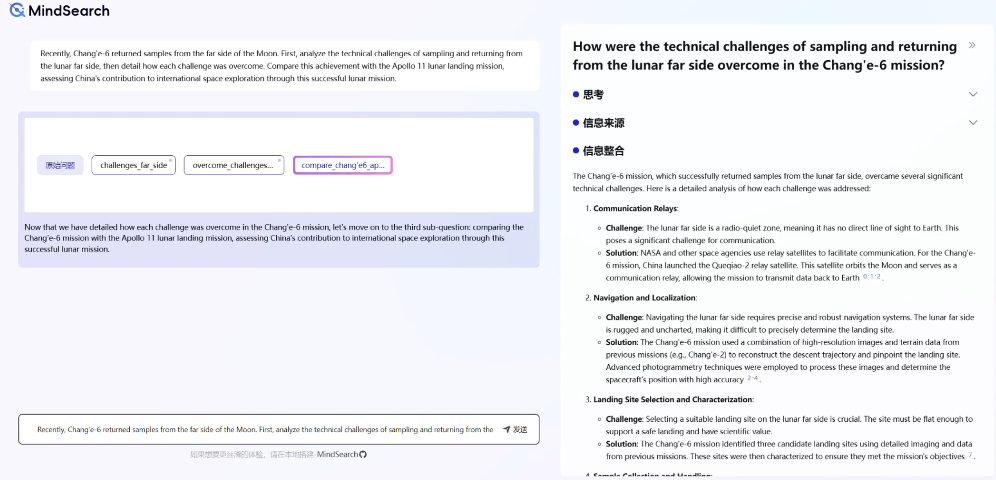
The design inspiration for the frontend interface comes from <span>MindSearch</span>, breaking down a complex macro problem into multiple sub-problems, utilizing the collaboration of multiple agents to simulate human thinking to gradually solve the problem.
Future Plans
- The current project has only been tested in the Shanghai Songjiang University Town area, and when the area range is expanded, relying solely on large models will not achieve precise localization.
- In the future, we plan to combine computer vision (CV) with large language models, utilizing the reasoning capabilities of large models to amplify the representation of image features and narrow down the localization range.
— The End —
Recommended Reading from Zhihui Stream::
1. Let’s Talk About the New Features of Nvidia Hopper: TMA
2. 🚀 Alibaba and Others Launch WritingBench🔥
3. Doing What Manus Could Not: How to Make AI Use Computers Like Humans? Unveiling the Intelligent Revolution of Agent S
4. Tsinghua and Others Launch VisualSimpleQA: A Benchmark Test for Decoupling the Evaluation of Large Visual Language Models’ Factual Accuracy
Welcome to reply “cc” in the “Zhihui Stream” WeChat public account to join the Zhihui Stream large model exchange group; reply “HF” to join our irregular HuggingFace Daily Paper high-rated paper sharing event group, which will also share AI paper news from major companies. Explore the future of AI and human potential with us, and ride the wave of AI together!