(Source: extremetech)
What does “NPU” stand for? What can it do? Here’s what you need to know about this emerging technology.
In the past year, discussions about Neural Processing Units (NPU) have increased significantly. Although NPUs have been present in smartphones for several years, Intel, AMD, and more recently, Microsoft have launched consumer-grade laptops and personal computers equipped with NPUs that support AI.
NPUs are closely related to the concept of AI PCs, with an increasing number of chips produced by major hardware manufacturers such as AMD, Apple, Intel, and Qualcomm incorporating NPUs. Since Microsoft launched its Copilot+ AI PC products earlier this year, NPUs have begun to appear more frequently in laptops.
l What role does the NPU play?
The role of the NPU is to act as a hardware accelerator for artificial intelligence. Hardware acceleration involves using dedicated silicon to manage specific tasks, much like a chef delegating different tasks to sous chefs to prepare a meal on time. The NPU does not replace your CPU or GPU; rather, it is designed to complement the strengths of the CPU and GPU, handling workloads such as edge AI so that the CPU and GPU can reserve processing time for tasks they excel at.
GPUs are hardware accelerators specifically designed for rendering graphics, but they also possess enough underlying flexibility to be well-suited for AI or certain types of scientific computing. For a long time, if you had AI workloads to process, you would want to use one or more high-performance [possibly Nvidia?] GPUs for the actual numerical computations. Some companies are working on building dedicated hardware accelerators specifically for AI, such as Google’s TPU, because the additional graphical capabilities that come with “G” in “GPU” are of no use in cards purely intended for AI processing.
l Workload determines everything
Hardware acceleration is most useful for repetitive tasks that do not involve a lot of conditional branching, especially when dealing with large amounts of data. For example, rendering 3D graphics requires the computer to manage a continuous stream of countless particles and polygons. This is a bandwidth-intensive task, but the actual computations are primarily trigonometric functions. Computer graphics, physics, astronomical calculations, and large language models (LLMs) such as those supporting modern AI chatbots are a few examples of ideal workloads for hardware acceleration.
AI workloads come in two types: training and inference. Training is almost entirely done on GPUs. Nvidia dominates both markets, leveraging its nearly two-decade investment in CUDA and its leadership in discrete GPUs, although AMD has fallen far behind in second place. Large-scale training occurs at data center scale, and inference workloads that run when you interact with cloud-based services like ChatGPT are also processed there.
The scale at which NPUs (and the AI PCs connected to them) operate is much smaller. They can supplement the integrated GPUs in the microprocessors from your favorite CPU vendors, providing additional flexibility for future AI workloads and improving performance compared to waiting for the cloud.
l How does the NPU work?
Generally, NPUs rely on a highly parallel design to execute repetitive tasks quickly. In contrast, CPUs are generalists. This difference is reflected in the logical and physical architecture of NPUs. A CPU has one or more cores that can access a small amount of shared memory cache, while an NPU has multiple sub-units, each with its own mini-cache. NPUs are suited for high-throughput and highly parallel workloads, such as neural networks and machine learning.
NPUs, neural networks, and neuromorphic systems (such as Intel’s Loihi platform) share a common design goal: to simulate certain aspects of brain information processing.
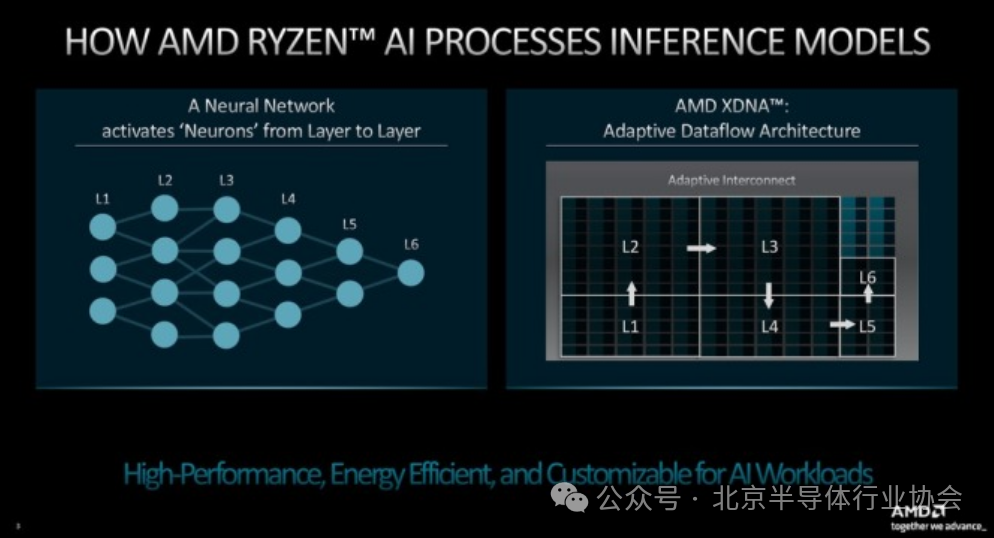
Every device manufacturer bringing NPUs to market has its specific microarchitecture tailored to its products. Most manufacturers also release software development tools to work with their NPUs. For example, AMD provides the Ryzen AI software stack, while Intel continues to improve its ongoing open-source deep learning software toolkit, OpenVINO.
l NPU and Edge Intelligence
Most NPUs are installed in consumer-facing devices such as laptops and PCs. For instance, Qualcomm’s Hexagon DSP adds NPU acceleration to its Snapdragon processors for smartphones, tablets, wearables, advanced driver-assistance systems, and the Internet of Things. The Apple ecosystem utilizes its Neural Engine NPU in the A-series and M-series chips in iPhones, iPads, and iMacs. Additionally, some PCs and laptops are designated as Copilot+, meaning they can run Microsoft’s Copilot AI on the onboard NPU. However, some server-side or cloud-based systems also utilize NPUs. Google’s Tensor Processing Units are NPU accelerators designed specifically for high-performance machine learning in data centers.
One reason for the rise of NPUs is the increasing importance of edge intelligence. The demand for data organization among sensor networks, mobile devices (such as phones and laptops), and the Internet of Things has grown significantly. Meanwhile, cloud-based services are constrained by infrastructure latency. Local processing does not necessarily have to perform any operations in the cloud. This can be an advantage in terms of both speed and security.
The question of whether you need an NPU is almost a distraction. Silicon Valley giants like Intel, AMD, and Apple have invested in this technology. Whether or not you have a specific use for an NPU, the chip you choose when assembling or purchasing your next PC is likely to come equipped with one. By the end of 2026, analysts expect that 100% of enterprise PC purchases in the U.S. will embed one or more NPUs in their chips. In other words, you need not worry about not being able to find systems with NPUs. They will be actively seeking you out.