(Source: techspot)
Today, hardware and software applications for artificial intelligence have evolved into systems designed specifically to optimize AI and neural network operations. This includes Neural Processing Units (NPU), whose capabilities in accelerating AI tasks are often comparable to those of Graphics Processing Units (GPU). NPUs are increasingly common hardware designed to execute cutting-edge AI/machine learning tasks at the fastest speeds. But how do they differ?
Let’s briefly explore NPUs and GPUs, compare their differences, and examine their respective advantages and disadvantages.
What is an NPU?
NPU stands for Neural Processing Unit. An NPU is a dedicated hardware designed to optimize the performance of tasks related to artificial intelligence and neural networks.
This might make NPUs sound like something belonging to research labs and military bases, but despite being a relatively new invention, NPUs are becoming increasingly common. Soon, you will start to see NPUs in desktop and laptop computers, with most modern smartphones integrating NPUs into their main CPUs, including iPhones, Google Pixels, and Samsung Galaxy models from recent years.
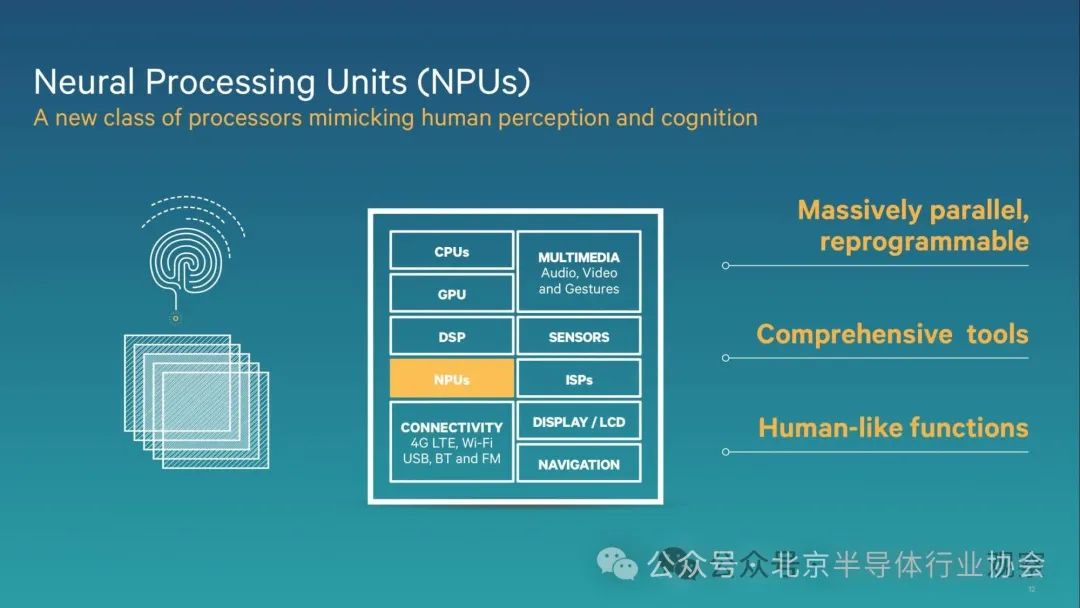
Neural Processing Units help support (as the name suggests) neural engines and network algorithms used in very advanced environments such as autonomous driving and natural language processing (NLP), as well as more common applications like facial recognition, voice recognition, and image processing on smartphones.
What is a GPU?
GPU stands for Graphics Processing Unit. GPUs were originally developed for rendering graphics in video games and multimedia applications, their use has significantly changed and they are now used in many different applications that require parallel processing to manage complex computations.
The unique advantage of GPUs is their ability to execute thousands of small tasks simultaneously, quickly and efficiently. This makes them particularly adept at handling complex tasks that require many calculations at once, such as rendering graphics, simulating physics, and even training neural networks.
NPU vs. GPU: Differences
Architecturally, NPUs are better suited for parallel processing than GPUs. NPUs have a greater number of smaller processing units compared to GPUs. NPUs can also combine specialized memory hierarchies and data flow optimizations to make processing deep learning workloads particularly efficient. In contrast, GPUs have more powerful cores. Historically, these cores have been used for various computational tasks through parallel processing, but NPUs are specifically designed for neural network algorithms.

NPUs excel at handling short and repetitive tasks. NPUs integrated into modern computing systems can offload the burden of inherent matrix operations for neural networks from GPUs, allowing GPUs to handle rendering tasks or general computations.
Compared to GPUs, NPUs perform exceptionally well in tasks that rely on intensive deep learning computations. NLP, voice recognition, and computer vision are several examples where NPUs outperform GPUs. GPUs have a more general architecture and may struggle to compete with NPUs in handling large-scale language models or edge computing applications.
NPU vs. GPU: Performance
The largest performance difference between NPUs and GPUs lies in efficiency and battery life. Since NPUs are designed specifically for neural network operations, they require significantly less power to execute processes at comparable speeds to GPUs.

This comparison is more about the current complexity and applications of neural networks rather than the architectural differences between the two types of hardware. NPUs are optimized architecturally for AI/ML workloads and outperform GPUs in handling the most complex workloads such as deep learning inference and training.

The dedicated hardware used for matrix multiplication and activation functions in NPUs means they outperform GPUs in tasks such as real-time language translation, image recognition in autonomous vehicles, and image analysis in medical applications.
Implementation Issues and Storage Requirements
At the enterprise level, NPUs can be integrated into existing infrastructure and data processing pipelines. NPUs can be deployed alongside CPUs, GPUs, and other accelerators within data centers to maximize computational power for AI tasks. However, when all AI/ML processing elements are incorporated into the operations of an enterprise data center, there may be risks associated with data access and storage.
Fully optimized NPUs and GPUs can handle AI/ML workloads, capable of processing data at very high speeds, while traditional storage systems may struggle to keep up, leading to potential bottlenecks in data retrieval and processing.
In applications, NPUs do not dictate specific storage spaces—but running them at peak efficiency relies on their extremely fast access to large datasets. NPUs processing AI/ML workloads typically require vast amounts of data to train and infer accurate models, as well as the ability to sort, access, modify, and store data extremely quickly. Enterprise-level solutions include flash storage and overall managed storage infrastructure.
In summary, NPUs are specifically designed and built to perform neural network operations, making them particularly effective at handling small repetitive tasks associated with AI/ML operations.
On the surface, GPUs sound similar: hardware components designed to execute small operations simultaneously. However, since NPUs are optimized for tasks like matrix multiplication and activation functions, they have a clear advantage in neural workloads. This makes NPUs superior to GPUs in handling deep learning computations, especially in terms of efficiency and speed.