According to reports from Electronic Enthusiasts (by Zhou Kaiyang), the sudden popularity of generative AIs like ChatGPT has once again driven the demand for high AI computing power. This impact is not limited to data center GPUs, FPGAs, and ASIC chips; NPUs in terminal devices have also entered a new round of computing arms race.
Although these NPUs are often not aimed at applications with ultra-large parameters like ChatGPT, the trend towards higher computing power design is inevitable, especially on mobile devices where AI applications like photo denoising, video super-resolution, and dynamic frame interpolation have started to become mainstream.
How high does the computing power need to be for NPUs?
For SoC design companies, especially startups, developing their own NPUs is quite challenging, so opting for excellent third-party NPU IP has become the preferred choice. On March 28, Arm Holdings launched the new “Zhouyi” X2 NPU, which is based on the new “Zhouyi” V3 architecture and introduces the Cluster concept, allowing multiple NPU cores to form a cluster. It also supports multiple clusters to form a subsystem, greatly enhancing performance scalability compared to the previous generation “Zhouyi” Z series, which only supported multi-core implementations in SoCs. This scalability allows the “Zhouyi” X2 NPU subsystem to support a maximum computing power of 320 TOPS.
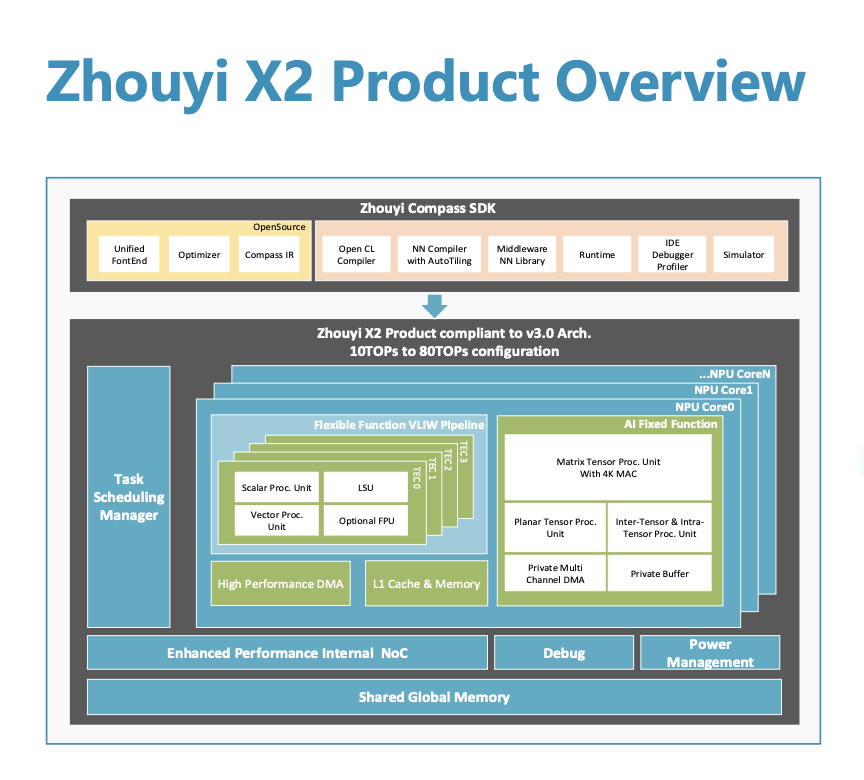
“Zhouyi” X2 NPU architecture / Arm Holdings
Compared to the previous generation “Zhouyi” Z series, another significant improvement of the “Zhouyi” X2 NPU is its support for mixed precision computing, rather than just supporting fixed-point INT8 integer schemes. Currently, the precisions supported by the “Zhouyi” X2 NPU include int4, int8, int12, int16, fp16, and fp32. Arm Holdings product director Yang Lei emphasized that the benefit of supporting mixed precision computing is that it balances computing performance and density, thereby better controlling chip costs.
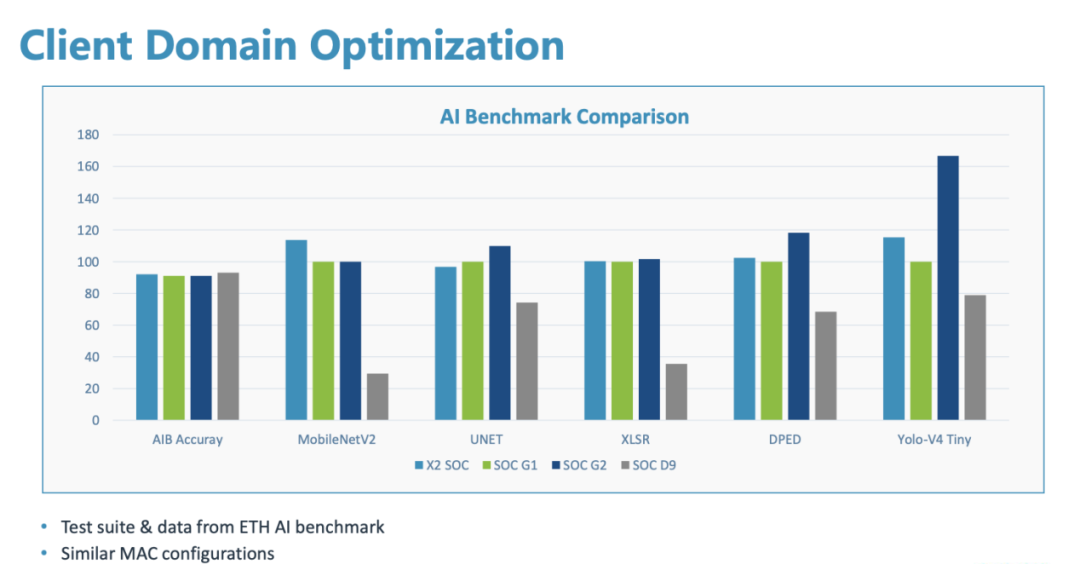
Comparison of ETH AI Benchmark scores between “Zhouyi” X2 SoC and competing SoCs / Arm Holdings
The ETH AI Benchmark scores also indicate that, under similar MAC configurations, the SoC integrated with the “Zhouyi” X2 NPU performs comparably or even better than competitors across various neural networks. In common networks like MobileNet and YOLO, it demonstrates a clear performance advantage.
Despite achieving such high computing power, the “Zhouyi” X2 NPU has not compromised on power consumption; instead, it has made more technological upgrades in low-power design. This is because one of the significant scenarios for the “Zhouyi” is handheld terminal devices, including smartphones and tablets. Based on a 7nm process node, the “Zhouyi” X2 NPU can achieve an energy efficiency ratio of 10 TOPS/W.
The “Zhouyi” X2 NPU is currently in a mature stage and can be officially delivered to customers. Yang Lei also revealed that several chips featuring the “Zhouyi” X2 NPU will be launched this year.
Not only autonomous driving outside the car, but also strong AI demand within the intelligent cockpit
As autonomous driving progresses from L2 to higher levels, the demand for AI computing power in autonomous driving chips has doubled. However, another automotive AI scenario is often overlooked: the intelligent cockpit. Unlike the heavy loads of autonomous driving and ADAS, the intelligent cockpit does not require computing power in the hundreds of TOPS, but this does not mean that the computing power required for intelligent cockpits is stagnant.
To achieve more intelligent cockpit features, such as presence detection, fatigue detection, and voice interaction, an increasing number of sensors are being integrated within the cockpit, often with multiple cameras providing data for visual detection algorithms and several microphones running voice and natural language processing algorithms. This involves a significant amount of models based on the Transformer structure.
The “Zhouyi” X2 NPU provides an efficient 4K MAC matrix, specifically optimized for these types of AI models. Additionally, the “Zhouyi” X2 NPU offers many reconfigurable structural units, allowing customers to deploy custom private operators through C language or OpenCL in this rapidly evolving era of AI models and operators, making it more attractive for automotive scenarios with strong customization needs. Yang Lei disclosed that a partner in the automotive field has developed about 40 operators through this route.
The other two major upgraded features of the “Zhouyi” X2 NPU also make it more suitable for intelligent cockpit scenarios: the bandwidth-saving i-Tiling technology and the TSM task decomposition and management technology that improves efficiency and responsiveness. Taking the aforementioned in-car visual processing as an example, when processing 4K resolution images, denoising can significantly increase bandwidth demands. The i-Tiling technology can split 4K images into several tiles, reducing external bandwidth requirements by 90%, thus avoiding memory wall limitations and significantly lowering system costs.
TSM supports multi-core real-time scheduling, for instance, when multiple cameras operate simultaneously or during multi-sensor fusion detection algorithms, the TSM unit can rapidly achieve parallel task scheduling of NPU cores, assigning tasks to idle NPU cores at a scheduling speed of up to 100ns. Crucially, this scheduling process does not require the main CPU’s participation, as it is handled by the TSM unit, reducing CPU occupancy rates.
Given these advantages, such as the maximum computing power, bandwidth, latency, and power consumption of the “Zhouyi” X2 NPU, it will find widespread applications in autonomous driving chips and intelligent cockpit chips. Arm Holdings’ Executive Vice President and Head of Product Development Liu Shu stated that the “Zhouyi” X2 NPU is primarily targeting the automotive market, especially the Chinese automotive market. China accounts for one-third of global automotive sales, and many local smart automotive brands have emerged in recent years, making them important partners for the “Zhouyi” X2.
Open-source software has become a trend; AI ecology must avoid fragmentation
However, like other AI computing units, relying solely on hardware advantages is not enough to maintain a competitive edge in the market; it will ultimately pose challenges to software design. After all, if software cannot fully leverage hardware performance, it will still be regarded as a failure in hardware-software co-design, and the design of NPUs is no exception.
From the product architecture diagram of the “Zhouyi” X2 NPU, it can be seen that the key to leveraging its hardware advantages is the “Zhouyi” Compass software platform. Arm Holdings has integrated low-level software, middleware such as compilers, Runtime, IDE, Profiler, and Simulator into Compass, and has prepared numerous high-performance NN operators for direct customer use.
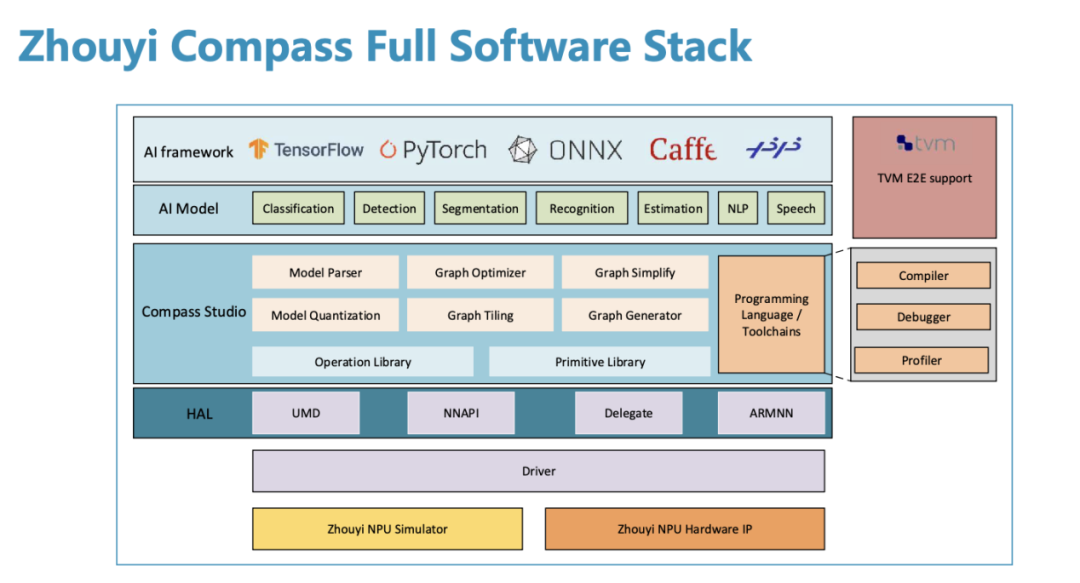
“Zhouyi” Compass software platform / Arm Holdings
The current Compass software platform has already integrated mainstream AI frameworks, such as TensorFlow, PyTorch, ONNX, and PaddlePaddle. In terms of support for heterogeneous computing, it also provides two open heterogeneous computing platforms, TVM and Arm NN, which can work together with other computing units in the SoC to maximize performance.
In the past, whether it was chips, semiconductor IP itself, or the development software tied to them, they were all commercially closed source. However, in the rapidly developing era of AI, more and more manufacturers have begun to realize the significant workload involved in application development and porting, especially in inference and training.
Yang Lei mentioned that Arm Holdings has statistically analyzed 60 chip projects using NPUs in China over the past year, of which 55% used self-developed NPUs, while the rest were based on IP solutions. However, these fragmented solutions ultimately lead to different development toolchains, increasing the difficulty and time required for software and application development.
To promote ecological prosperity and avoid fragmentation, many manufacturers have chosen the open-source software route, and Arm Holdings is no exception. With the launch of new products, Arm Holdings also introduced the “Zhouyi” NPU open-source software plan, opening up the intermediate representation layer of “Zhouyi”, as well as model parsers, quantization, drivers, and scheduling, with the code uploaded to the Github community.
Additionally, an ecosystem partner program has been launched, providing existing self-developed product technology solutions from Arm Holdings’ IP matrix to ecosystem partners, including the “Zhouyi” NPU, “Shanhai” SPU, “Xingchen” CPU, and “Linglong” ISP&VPU, among others. Partners in this program include not only chip customers but also upstream and downstream players, such as OEMs and software algorithm developers, like the new automotive manufacturers mentioned earlier.
Localized self-developed IP matrix to avoid reinventing the wheel
As one of Arm Holdings’ self-developed IP R&D teams, its NPU R&D team has iterated the “Zhouyi” architecture three times over the past five years. According to Sun Jinhong, Senior Director of NPU R&D at Arm Holdings, the entire team consists of over 130 engineers engaged in full-stack collaborative development of NPU hardware and software, covering AIoT, smart terminals, and automotive scenarios. Facing the ever-changing future neural networks, there will be more demands on NPU architecture, and Arm Holdings will take measures to improve the “Zhouyi” architecture under the premise of being close to customers and practical applications.
When asked about Arm Holdings’ positioning in the domestic semiconductor industry, Liu Shu replied, “The positioning of an IP company like Arm Holdings is akin to a shared design center for the industry.” Their NPU team is responding to the technological trends in the industry to solve common problems that customers and partners are unwilling to invest resources in repeatedly, thereby shortening the design, verification, tape-out, and delivery cycles of chips.