
2024 is destined to be an extraordinary year for the AI industry. Although we have just entered March, AI news has already repeatedly occupied the headlines. Last month, OpenAI released the text-generating video model Sora, whose realistic effects have directly cleared the market for entrepreneurs struggling in this niche. A few days later, Nvidia’s market value hit $2 trillion, becoming the fastest company in history to achieve a market value from $1 trillion to $2 trillion. As the saying goes, “When you discover a gold mine, the best business is not mining but selling shovels,” Nvidia has become the biggest winner in the AI era’s arms race.
While everyone laments that “there are only two types of AI in the world, one is called OpenAI, and the other is called other AI,” the long-silent Anthropic dropped a bombshell. This company, founded by a former research vice president of OpenAI, released the latest Claude3 model, which has surpassed GPT4 across all metrics.
The upheaval in the AI industry also indicates that this industry is still in its early stages. The pace of technological iteration is too fast, and temporarily leading companies may be overturned overnight by new technologies. Some dazzling new technologies have emerged but have yet to be publicly released or deployed. For example, the aforementioned Sora has not yet been officially opened to the public as of this writing.
There exists a gap between the research and local deployment of generative AI. Currently, generative AI products used by the public are often deployed in the cloud and accessed locally (such as the ChatGPT webpage), but this does not meet all needs and can create some risks.
Firstly, as large models become increasingly complex, the transmission between the cloud and local becomes strained under limited bandwidth. For instance, a Boeing 787 generates 5G of data per second; if uploaded to the cloud, computed, and the results returned, the plane could have already flown several kilometers away (assuming a speed of 800 km/h).
If AI functions are used on the plane but deployed in the cloud, such transmission speeds would be inadequate.
Moreover, should sensitive user data or privacy data necessarily go to the cloud? Clearly, keeping it local is more reassuring for users.
No matter how powerful generative AI is, deploying it locally remains an unavoidable issue. This is a trend in industry development, although it currently faces some difficulties.
The difficulty lies in how to fit a “large model” into “small devices.” Note that here, “size” is relative. The cloud computing behind it may be a data center covering tens of thousands of square meters, while local deployment requires generative AI to run on your phone. Without liquid nitrogen cooling or endless power, how can AI be deployed?

Qualcomm’s heterogeneous computing AI engine (hereafter referred to as Qualcomm AI engine) provides a feasible solution for the industry. It achieves AI deployment and significantly enhances AI experience through the collaboration of CPU, GPU, NPU, and Qualcomm’s sensor hub and memory subsystems.

Image|Dedicated industrial design makes different computing units more compact Source: Qualcomm
Different types of processors excel at different tasks; the principle of heterogeneous computing is to let “specialists do specialized work.” CPUs are good at sequential control and suitable for low-latency application scenarios. Meanwhile, some smaller traditional models, such as Convolutional Neural Networks (CNN) or some specific Large Language Models (LLM), can also be handled well by CPUs. GPUs excel at parallel processing for high-precision formats, such as videos and games that require very high image quality.
CPUs and GPUs are widely recognized, and the public is quite familiar with them, while NPUs are relatively new technology. NPUs, or Neural Processing Units, are designed specifically for low-power, accelerated AI inference.When we continuously use AI, we need to output high peak performance with low power consumption, and this is where NPUs can shine.
For example, when a user plays a resource-intensive game, the GPU will be fully occupied, or when the user browses multiple web pages, the CPU will be fully occupied. At this time, the NPU, as a true AI dedicated engine, will take on the AI-related computations, ensuring a smooth AI experience for the user.
To summarize, CPUs and GPUs are general-purpose processors designed for flexibility and easy programming, responsible for the operating system, games, and other applications. NPUs are designed for AI; AI is their primary task, achieving higher peak performance and energy efficiency by sacrificing some programmability, thus safeguarding the user’s AI experience.
When we integrate CPUs, GPUs, NPUs, and Qualcomm’s sensor hub and memory subsystems, we have a heterogeneous computing architecture.
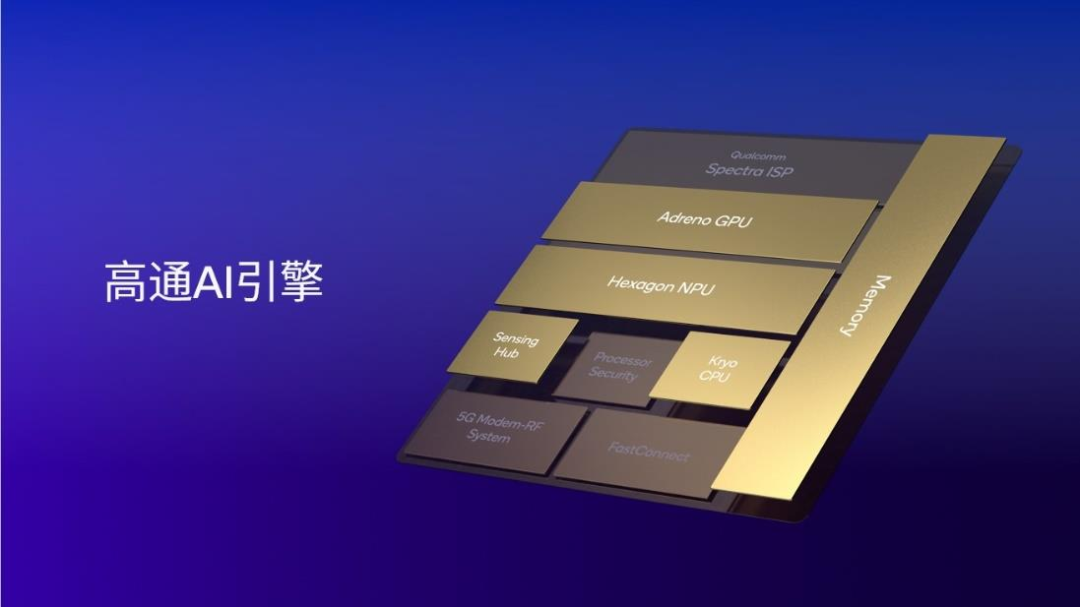
Image|Qualcomm AI engine includes Hexagon NPU, Adreno GPU, Qualcomm Oryon or Kryo CPU, Qualcomm sensor hub, and memory subsystems Source: Qualcomm
Qualcomm AI engine integrates Qualcomm Oryon or Kryo CPU, Adreno GPU, Hexagon NPU, and Qualcomm sensor hub and memory subsystems. The Hexagon NPU, as the core component, has reached industry-leading AI processing levels after years of upgrades and iterations. For example, on mobile platforms, the third-generation Snapdragon 8 supports industry-leading LPDDR5x memory with a frequency of up to 4.8GHz, enabling it to run large language models such as Baichuan and Llama 2 at very high chip memory read speeds, achieving very fast token generation rates and providing users with a brand-new experience.

Image|NPU continues to evolve with changing AI use cases and models, achieving high performance with low power consumption Source: Qualcomm
Qualcomm’s research on NPUs did not start in recent years. If we trace back to the origin of Hexagon NPU, it goes back to 2007, 15 years before generative AI entered the public eye. The first Hexagon DSP released by Qualcomm debuted on the Snapdragon platform, and its DSP control and scalar architecture became the foundation for Qualcomm’s future generations of NPUs.
Eight years later, in 2015, the Snapdragon 820 processor integrated the first Qualcomm AI engine;
In 2018, Qualcomm added tensor accelerators to Hexagon NPU in Snapdragon 855;
In 2019, Qualcomm expanded terminal-side AI use cases in Snapdragon 865, including AI imaging, AI video, AI voice, and more;
In 2020, Hexagon NPU underwent a transformative architecture update. Scalar, vector, and tensor accelerators were integrated, laying the foundation for Qualcomm’s future NPU architecture;
In 2022, the Hexagon NPU in the second-generation Snapdragon 8 introduced a series of significant technological improvements. Micro-slicing technology eliminated up to 10 layers of memory occupancy, reducing power consumption and achieving a 4.35-fold increase in AI performance.
On October 25, 2023, Qualcomm officially released the third-generation Snapdragon 8. As Qualcomm’s first mobile platform meticulously designed for generative AI, its integrated Hexagon NPU represents Qualcomm’s latest and best design for generative AI.
Qualcomm provides a complete solution for AI developers and downstream manufacturers (this part will be elaborated in the third part), rather than just chips or a specific software application.This means that Qualcomm can consider hardware design and optimization comprehensively, identify current bottlenecks in AI development, and make targeted improvements.
For example, why pay special attention to the technical point of memory bandwidth? When we shift our perspective from chips to AI large model development, we find that memory bandwidth is the bottleneck for token generation in large language models. One reason why the NPU architecture of the third-generation Snapdragon 8 can help accelerate the development of AI large models is that it specifically improves the efficiency of memory bandwidth.
This efficiency improvement mainly benefits from the application of two technologies.
The first is micro-slicing inference. By dividing the neural network into multiple independently executed micro-slices, it eliminates up to 10 layers of memory occupancy, maximizing the utilization of scalar, vector, and tensor accelerators in the Hexagon NPU while reducing power consumption. The second is local 4-bit integer (INT4) operations. It can double the throughput of INT4 layers and neural networks and tensor accelerators, while also improving memory bandwidth efficiency.
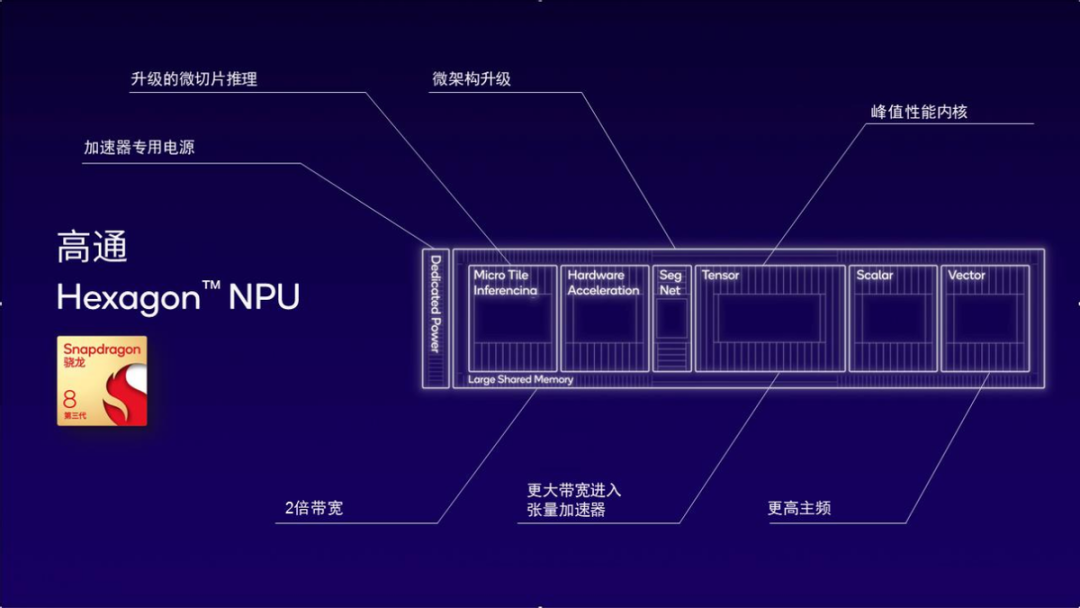
Image|The Hexagon NPU of the third-generation Snapdragon 8 achieves better AI performance with low power consumption
On February 26, the Mobile World Congress (MWC 2024) kicked off in Barcelona. Based on Snapdragon X Elite, Qualcomm showcased the world’s first large multimodal language model (LMM) with over 7 billion parameters running on the terminal side. This model can accept text and audio inputs (such as music, traffic sounds, etc.) and generate multi-turn dialogue based on audio content.
So, what kind of AI experience will there be on mobile terminals integrated with the Hexagon NPU? And how is it achieved? Qualcomm detailed a case study.
With the AI travel assistant on mobile terminals, users can directly request the model to plan travel itineraries. The AI assistant can immediately provide flight itinerary suggestions and adjust output results through voice conversation, ultimately creating a complete flight schedule using the Skyscanner plugin.
How is this seamless experience achieved?
First, the user’s voice is converted into text through the Automatic Speech Recognition (ASR) model Whisper. This model has 240 million parameters and mainly runs on Qualcomm’s sensor hub;
Second, the Llama 2 or Baichuan large language model generates text replies based on the text content, which runs on the Hexagon NPU;
Third, the text is converted into speech through an open-source TTS (Text to Speech) model running on the CPU;
Finally, network connection is established through modem technology, using the Skyscanner plugin to complete the ticket booking.

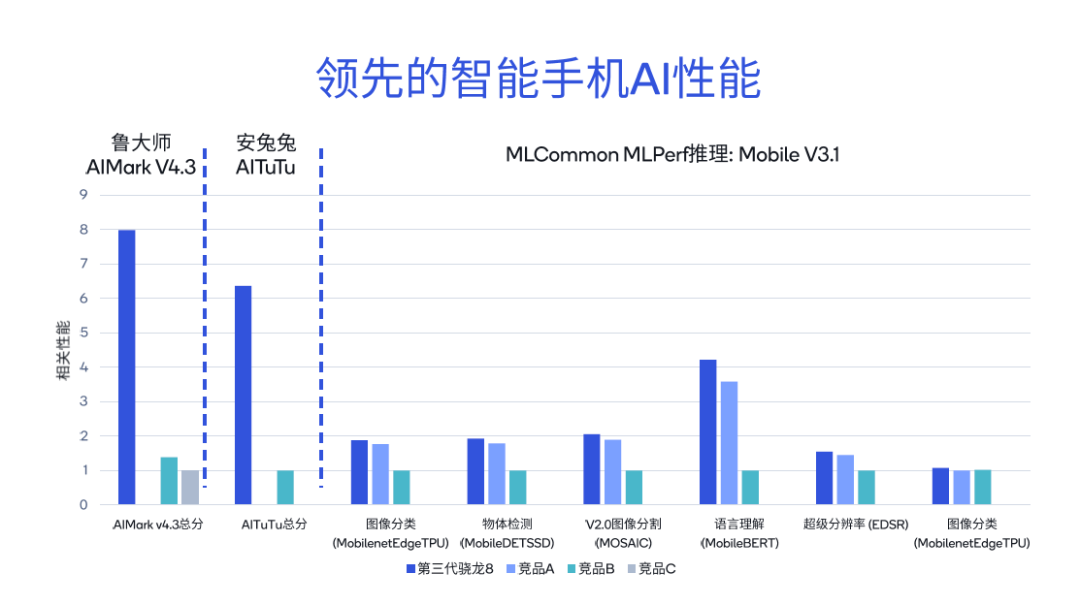
Testing the AI performance of Snapdragon and Qualcomm platforms with different tools reveals that their scores are several times higher than competing products. According to the results of the Lu Master AIMark V4.3 benchmark test, the total score of the third-generation Snapdragon 8 is 5.7 times higher than competing product B and 7.9 times higher than competing product C.
In the AnTuTu AITuTu benchmark test, the total score of the third-generation Snapdragon 8 is 6.3 times higher than competing product B. Detailed comparisons were also made for various sub-items of MLCommon MLPerf inference, including image classification, language understanding, and super-resolution.
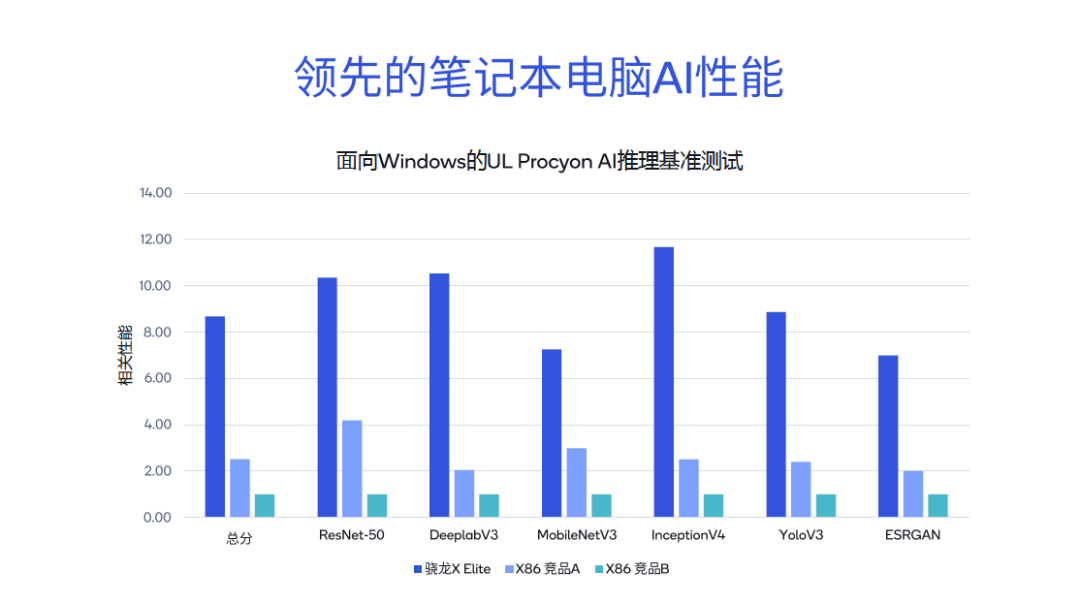
Further comparisons between Snapdragon X Elite and other X86 architecture competitors show that Snapdragon X Elite demonstrates a clear leading position in tests such as ResNet-50 and DeeplabV3, with total benchmark scores being 3.4 times that of X86 architecture competitor A and 8.6 times that of competitor B. Therefore, on the PC side, whether running Microsoft Copilot or performing document summarization, document writing, and other generative AI applications, the experience is very smooth.
Leading AI performance is not solely due to the Qualcomm AI engine; rather, Qualcomm’s empowerment of AI manufacturers is comprehensive.
First, there is the Qualcomm AI engine. It includes Hexagon NPU, Adreno GPU, Qualcomm Oryon CPU (PC platform), Qualcomm sensor hub, and memory subsystems. Dedicated industrial design and good collaboration between different components provide a low-power, high-efficiency development platform for terminal-side products.
Based on advanced hardware, Qualcomm also launched the AI software stack (Qualcomm AI Stack). This product was created to address the persistent issues in AI development—repeated labor for the same function across different platforms. The AI Stack supports all major AI frameworks currently, allowing OEM manufacturers and developers to create, optimize, and deploy AI applications on the platform, achieving “one-time development, multi-platform deployment,” greatly reducing redundant work for developers.

Image|Qualcomm AI Stack helps developers achieve “one-time development, multi-platform deployment” Source: Qualcomm
Additionally, there is the AI Hub recently launched by Qualcomm at MWC 2024. AI Hub is a model library containing nearly 80 AI models, including both generative AI models and traditional AI models, as well as image recognition or facial recognition models, such as Baichuan, Stable Diffusion, Whisper, and more. Developers can select the desired models from AI Hub to generate binary plugins, achieving “plug and play” in AI development.

In summary, if we look vertically in depth, Qualcomm accelerates the AI development pace of manufacturers comprehensively across three dimensions: hardware (AI engine), software (AI Stack), and material library (AI Hub). Horizontally, Qualcomm’s products cover nearly all terminal-side devices (the third-generation Snapdragon 8 supports mobile phones and other terminals, while X Elite empowers AI PC products).
AI applications are in the brewing stage before a boom.
In the education sector, AI can formulate personalized teaching plans based on students’ learning abilities and progress; in the medical field, AI can be used to discover new types of antibiotics; in elderly care, AI terminals can collect all personal data from the homes of elderly individuals in regions with serious aging issues, helping to prevent emergency medical incidents.
The term “before the boom” is used precisely because large-scale deployment has not yet occurred. On the other hand, AI applications, being one of the easiest products to generate user stickiness, have a strong first-mover advantage effect.
AI product developers need to take the lead, allowing users to experience their products earlier, establishing connections with users, cultivating stickiness, and thus gaining an advantage in competition.
