
Introduction

This article is translated from https://princeton-nlp.github.io/language-agent-impact/
While 2022 was the year that language models like ChatGPT captured public attention, 2023 witnessed the rise of language agents (also known as agents). Papers like “ReAct” and “Toolformers”, along with frameworks such as “LangChain” and “ChatGPT Plugins”, demonstrated that language models can connect with web pages, software, tools, and APIs to enhance their capabilities through computational tools and customized, up-to-date information sources. This ability to act and influence the world allows language models to be applied in a broader range of fields, beyond traditional language processing. For instance, they can navigate websites to gather information, control software like Excel, or engage in interactive programming with execution feedback.
The “language agents” referred to in this article are intelligent agents based on large language model technology.
Referring to these machines simply as “language models” (whose optimization objective is to predict the next token) significantly underestimates their capabilities, as they are evolving into autonomous agents capable of using language as the primary medium to solve general digital tasks—in short, “language agents” in the digital world.
Despite the excitement surrounding demonstrations and papers about language agents, what does this mean for the future of artificial intelligence and society? This blog post aims to provide our insights on this question and spark discussions around the inherent opportunities and risks in the development of language agents. For a technical overview of these agents, please refer to the excellent blog post by Lilian Weng. Additionally, for more papers, blog posts, benchmarks, and other resources about language agents, please visit our repository.
https://github.com/ysymyth/awesome-language-agents
Language Agents in the Digital World:
A New Prospect for General Artificial Intelligence
Language Agents in the Digital World:
A New Prospect for General Artificial Intelligence
The long-standing goal of artificial intelligence has been to create autonomous agents that can interact intelligently with their environment to achieve specific goals. Reinforcement learning (RL) is a powerful framework for addressing these challenges, with notable successes such as AlphaGo and OpenAI Five. However, RL has always struggled with the issues of lack of inductive bias and environmental constraints. Injecting human visual-motor or physical priors has been challenging, meaning that RL models often require millions of interactions to train from scratch. Thus, learning in physical, real-world environments has been fraught with challenges, as robot interaction speeds are slow and collection costs are high. This also explains why major reinforcement learning success cases have occurred in games—where simulations are fast and cheap, but also present closed and limited domains that are difficult to transfer to complex real-world intelligent tasks.
While physical environments and game worlds each have their limitations, the digital world (primarily using language) offers unique scalable environments and learning advantages. For example, WebShop is a shopping website environment with millions of products, where agents need to read web pages, input queries, and click buttons to shop, just like humans. Such digital tasks challenge multiple aspects of intelligence, including visual understanding, reading comprehension, and decision-making, and can be easily scaled. This also provides opportunities to guide agents to fine-tune using pre-trained prior knowledge—large language model prompts can be directly applied to WebShop or any ChatGPT plugin tasks, which is difficult to achieve in traditional reinforcement learning domains. As more APIs are integrated into the environment, an extremely diverse and highly open ecosystem of digital tools and tasks will emerge, giving rise to more general and capable autonomous language agents. This will pave new paths toward general artificial intelligence.
The Huge Potential of an Automated Society
The Huge Potential of an Automated Society
While physical environments and game worlds each have their limitations, the digital world (primarily using language) offers unique scalable environments and learning advantages. For example, WebShop is a shopping website environment with millions of products, where agents need to read web pages, input queries, and click buttons to shop, just like humans. Such digital tasks challenge multiple aspects of intelligence, including visual understanding, reading comprehension, and decision-making, and can be easily scaled. This also provides opportunities to guide agents to fine-tune using pre-trained prior knowledge—large language model prompts can be directly applied to WebShop or any ChatGPT plugin tasks, which is difficult to achieve in traditional reinforcement learning domains. As more APIs are integrated into the environment, an extremely diverse and highly open ecosystem of digital tools and tasks will emerge, giving rise to more general and capable autonomous language agents. This will pave new paths toward general artificial intelligence.
An autonomous machine capable of acting has huge potential to alleviate human labor burdens across various fields. From robotic vacuum cleaners to self-driving cars, these machines are typically deployed in physical environments, equipped with task-specific algorithms and narrow application scopes. On the other hand, language agents like ChatGPT plugins and Microsoft 365 Copilot offer general solutions for automating a wide range of digital tasks, which is especially crucial in an era where much of human life and work is conducted in digital environments.
In a study involving 95 people, we glimpse the upcoming revolution—Github Copilot reduced average coding time by over 50%. However, Github Copilot only provides preliminary suggestive actions—an increasingly autonomous agent capable of repeatedly writing code, executing it, and utilizing automatic environmental feedback (such as error messages) to debug code is emerging.
Designers, accountants, lawyers, and any profession dealing with digital tools and data may experience similar situations. Furthermore, considering the Internet of Things connecting the physical world with the digital world, language agents could interact with physical environments far beyond simple functions like Alexa’s “turn on the light.” For instance, with cloud robotics lab services, language agents could participate in complex decision cycles for automated drug discovery: reading data, analyzing insights, setting parameters for the next experiment, reporting potential results, and so on.
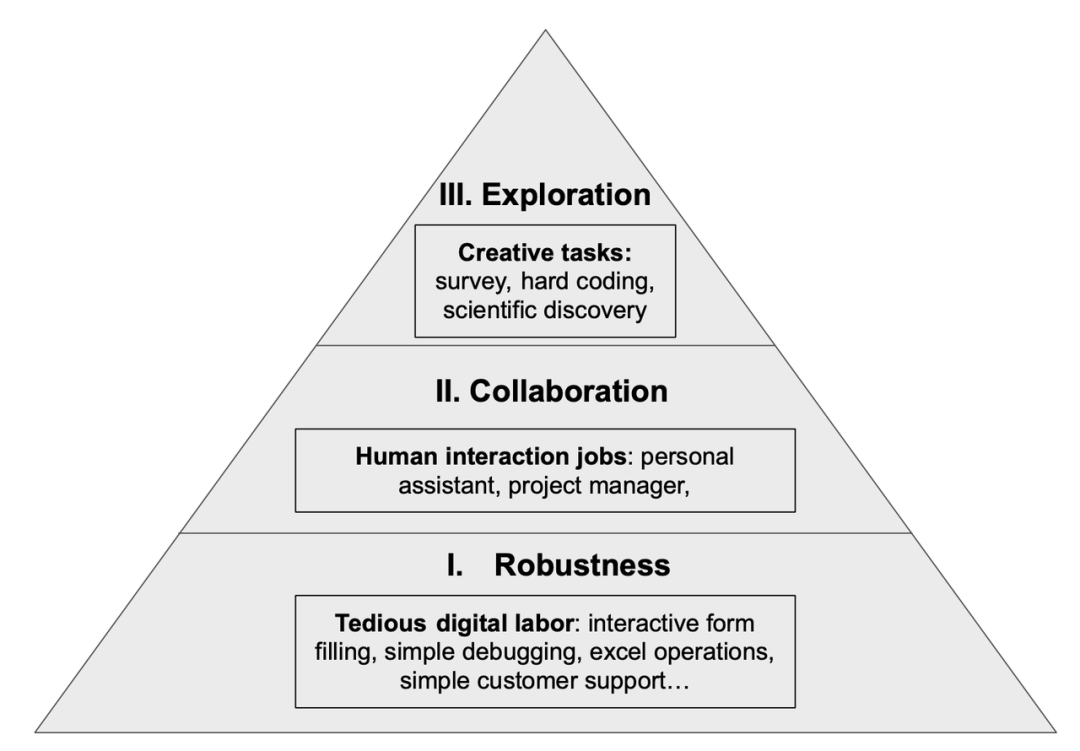
The automation opportunities of language agents and their capability ladder.
Faced with endless possibilities, how should we classify them? There seems to be no single answer, just as human work can be classified or organized from multiple dimensions (salary level, work environment, knowledge level, general vs. specialized, etc.). Here, we propose a three-step progressive ladder based on agent capabilities.
• Step One: Enhancing the robustness of tedious digital labor: Tasks such as interacting with web pages and software to fill out various forms, repetitive Excel operations, or customer support tasks, or fixing code errors, involve multiple rounds of information retrieval and trial and error. These digital activities (excluding coding) can onboard newcomers with just a few hours of training, yet are repetitive and tedious for humans, and may also lead to errors due to fatigue. Similarly, automating these jobs does not seem to have fundamental barriers. Providing a few examples to GPT-4 can achieve reasonable performance on many such simple tasks. However, achieving human-level reliability and safety remains a challenge (see below). Once this is achieved, a significant portion of these jobs is expected to be automated, potentially marking the initial rise of automation driven by language agents.
Coq proof assistant https://coq.inria.fr/
Balancing Progress and Safety
Balancing Progress and Safety

Robustness, malicious use, job insecurity, and the presence of risks. While history has provided insights into the first three issues, the presence of risks is less understood and more unknown.
How to Address These Risks
How to Address These Risks

Addressing safety issues of language agents (and AI in general) requires collaboration and multi-layered efforts from developers, researchers, educators, policymakers, and even AI systems.
Constitutional AI https://arxiv.org/abs/2212.08073
2. Preventing malicious use through regulation: Responsible ownership, control, and oversight of large language models and their applications are crucial. In addition to technical solutions for robustness and safeguards, legal, regulatory, and policy frameworks are needed to govern their deployment. For instance, OpenAI has proposed a licensing system for large models, an idea that may soon be implemented in countries like China. Furthermore, strict data permission protocols and regulations can be established to prevent misuse and unauthorized access to sensitive information. At the same time, potential criminal behaviors should be considered, and punitive measures should be established based on the experiences of cryptocurrency crimes and their legal consequences.
OpenAI licensing system https://www.bloomberg.com/news/articles/2023-07-20/internal-policy-memo-shows-how-openai-is-willing-to-be-regulated
3. Employment impacts and educational policy needs: In the face of a (potential) employment crisis, implementing comprehensive education and policy initiatives is crucial. By equipping individuals with the skills and knowledge needed to adapt to changing environments, we can facilitate the smooth integration of language agents into various industries. This can be achieved through educational programs, vocational training, and reskilling initiatives to prepare the workforce for the demands of a technology-driven future.
4. Managing existential risks through understanding and research: Deepening our understanding of language agents and their impacts is crucial before taking further action. This involves a thorough understanding of how these models operate, their limitations, and potential risks. Additionally, establishing scalable oversight mechanisms to ensure responsible deployment and prevent potential misuse is also vital. One approach is to leverage language agents themselves to monitor and evaluate the behavior of other language agents, proactively identifying and mitigating any harmful consequences. Promoting further research in the field of language agents will help us gain a more comprehensive understanding of their safety implications and assist society in developing effective safeguards.
Final Thoughts
Final Thoughts
“Post-ChatGPT” Reading Club

AGI Reading Club Launched
To delve into AGI-related topics, the Collective Intelligence Club, in collaboration with Yuetao Yue, Director of the Institute of Deep Perception Technology, MIT Ph.D. Shen Macheng, and Temple University Ph.D. student Xu Bowen, has jointly initiated the AGI reading club, covering topics including: definitions and measurements of intelligence, principles of intelligence, large language models and intelligent information worlds, perception and embodied intelligence, artificial intelligence from multiple perspectives, alignment techniques and AGI safety, and future societies in the AGI era. The reading club will begin on September 21, 2023, every Thursday evening from 19:00 to 21:00, expected to last for 7-10 weeks. Friends interested are welcome to sign up to participate!

For more details, see:
AGI Reading Club Launched: Interdisciplinary Pathways to General Artificial Intelligence
Recommended Reading