Since the emergence of large language models, the popularity of AI Agents has been on the rise, seen as a viable path towards AGI (Artificial General Intelligence). Personally, when using AI products like GPT, I not only enjoy their convenience in handling daily tasks, such as assisting with information collection and validating the feasibility of new product PMF (Product-Market Fit), but I am also constantly exploring ways to solve existing problems.
How can we make Agents controllable, accurate, and efficient in dealing with complex tasks? How can they automatically decompose task objectives and accurately mobilize other Agents to collaborate on the sub-tasks? How can we construct a more scientifically reasonable multi-Agent product architecture? These questions have prompted me to write this note. By combining theory and practice, I aim to form a more systematic understanding of Agents, distilling a methodology for building Agents, and sharing this process as a reference for learning and communication.

You may be curious, what exactly is an Agent? How does it differ from large models? And what can it help us do?
From traditional software to large model applications, and then to the evolution of Agents, we can easily see that traditional software like Bilibili, WeChat, or the console game “Black Wukong” performs tasks automatically within limited scenarios through preset program rules and code logic. For example, in the Bilibili search input box, it explicitly requires text input; once “Agent” is entered, the application follows established processing rules to match video titles and descriptions across the internet, combining data such as views, likes, and comments to comprehensively rank the search results, ultimately presenting them to the user in the form of a video list.
On the other hand, large language model applications like ChatGPT, Claude, and Kimi mimic the human brain, trained on vast amounts of data. When in use, the model often cannot predict what content the user will input, which could be text, tables, images, or even videos and audio. The process of information handling and output results is also filled with uncertainty, but it is this uncertainty that gives the model creativity and survivability, allowing it to step beyond rule-based programs toward a more human-like direction. When using ChatGPT, we often experience this: after inputting a task, the model immediately provides an answer, but the answer may deviate from our expectations. At this point, we need to adjust the instructions and resend them to ChatGPT, repeating this process until we get a satisfactory result. This process is what we commonly refer to as “Prompt Engineering,” which tests the user’s ability to ask questions and express needs.
However, to elevate the quality of large language model outputs, we face several challenges:
-
Insufficient data timeliness: The training data for models is time-sensitive; for example, ChatGPT-4’s training data is cut off in October 2023, thus unable to provide the latest information and insights on events occurring after that time.
-
Lack of vertical domain knowledge: While large models are trained on broad datasets and possess generalization capabilities, their analysis and suggestions in vertical fields such as medicine, law, or finance cannot match those of domain experts.
-
Context length limitations: When processing long texts, large models may lose context, resulting in incoherent or contradictory generated content.
To address the limitations of large language models and better achieve commercial application, we have entered the era of Agents. In June 2023, an OpenAI researcher published a blog post titled “Autonomous Agents Driven by Large Language Models,” which garnered widespread attention.
So, what exactly is an Agent? Currently, in Chinese, Agents are often referred to as “智能体” (intelligent body), but I prefer to call them “代理” (proxy). They are AI programs that handle tasks on behalf of humans. Take smart cars as an example; smart cars integrate functions like autonomous driving, automatic parking, and voice control, collectively resembling an Agent. They possess the ability to interact with the outside world and execute tasks, while the car engine—its core component—serves as the core unit model or multimodal model providing speed and powerful dynamics, akin to how the engine functions for a car, acting as the intelligent brain of the Agent responsible for understanding and processing complex instructions.
Of course, a car has more than just an engine; it also has tires, a steering system, brake sensors, etc. To build an Agent capable of handling complex tasks, it requires not only reliance on language models but also the collaborative interaction of components such as data perception collection, external tool invocation, decision-making, and task planning. Thus, the Agent can be seen as an extension of the large model, compensating for and enhancing capabilities that the model lacks.
Through comparative case studies, we may better appreciate the charm of Agents. As mentioned earlier, the interaction process of large language models typically involves: the user inputs a task, the large language model directly outputs, the user evaluates based on the output content, and then re-inputs instructions for the large model to process, repeating this until satisfied. In contrast, the interaction process of AI Agents is entirely different: after the user inputs a task, the Agent automatically decomposes it into multiple sub-tasks and determines the order of priority for execution. During processing, the Agent selectively invokes external tools to assist in handling based on task requirements. After completion, the Agent reflects and evaluates, optimizing execution strategies for the next task. Once all tasks are completed, the Agent summarizes and outputs the final result to the user. Therefore, the content output by an excellent Agent is a complete task solution.
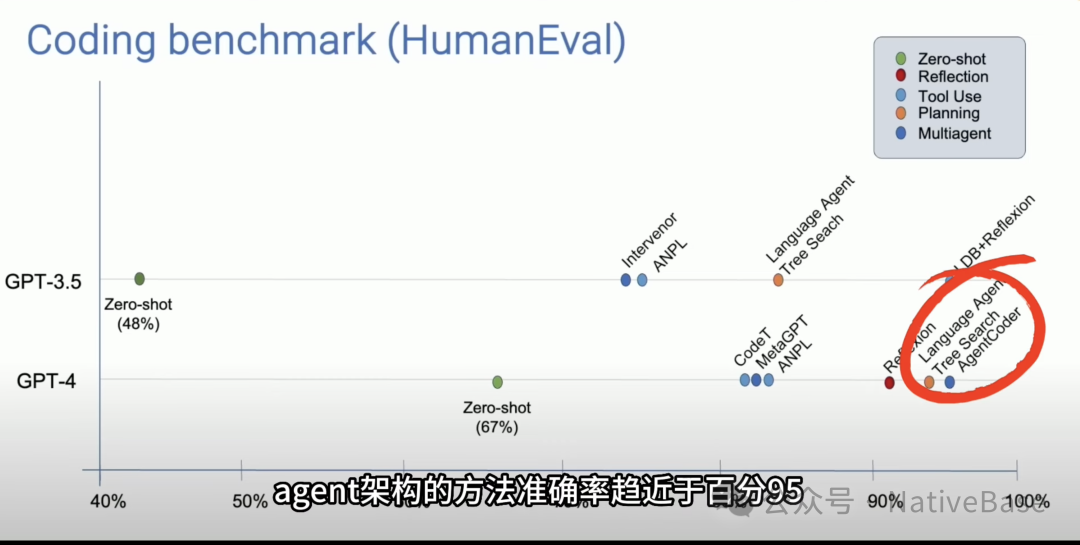
Professor Andrew Ng’s team conducted comparative experiments on programming issues between large language models and Agents, discovering that the output accuracy of GPT-3.5 and GPT-4 was 48% and 67%, respectively, while models using Agent architecture achieved higher output quality with accuracy approaching 95%.
So I summarize several significant characteristics of Agents compared to large language models:
First, they possess planning and decision-making capabilities. Unlike large language models, which operate without regrets, Agents are closer to human thinking, finding the optimal heuristic for task objectives through exploration and iterative trial and error.
Second, they have memory capabilities, freeing themselves from the context limitations of large language models. Agents can remember users’ preferences and usage habits, summarizing and storing context in a database, enabling large language models to better understand long texts and handle complex dialogues.
Third, they have the ability to invoke tools. Under the Agent architecture, they can help unit models recognize their capability boundaries by invoking external tools or other models to solve corresponding problems.
Fourth, they have a cooperation mechanism, capable of collaborating with multiple models or combinations of multiple Agents to achieve complex workflows. For example, in the scenario of formulating product strategies, growth Agents and commercialization Agents can be likened to a company’s marketing operations team and commercialization team, engaging in multi-objective trade-offs in user scale and commercial revenue, ultimately allowing AI to devise a product strategy that balances both sides’ demands.