
Source: DeepHub IMBA
This article is approximately 5000 words long and is suggested to be read in 10 minutes.
This article starts with a simple implementation of LoRA, delving into LoRA, its practical implementation, and benchmarking.
LoRA stands for Low-Rank Adaptation, which provides an efficient and lightweight method for fine-tuning pre-existing language models.
One of the main advantages of LoRA is its efficiency. By using fewer parameters, LoRA significantly reduces computational complexity and memory usage. This allows us to train large models on consumer-grade GPUs and distribute our LoRA (measured in megabytes) to others.
LoRA can improve generalization performance. By limiting the model’s complexity, they help prevent overfitting, especially when training data is limited. This results in more resilient models that perform well when handling new, unseen data, or at least retain knowledge from their original training tasks.
LoRA can be seamlessly integrated into existing neural network architectures. This integration allows for fine-tuning and adaptation of pre-trained models with minimal additional training costs, making them very suitable for transfer learning applications.
This article will first explore LoRA in depth, then develop a LoRA from scratch using the RoBERTa model, followed by benchmarking the implementation using GLUE and SQuAD benchmarks, and discuss some tips and improvements.
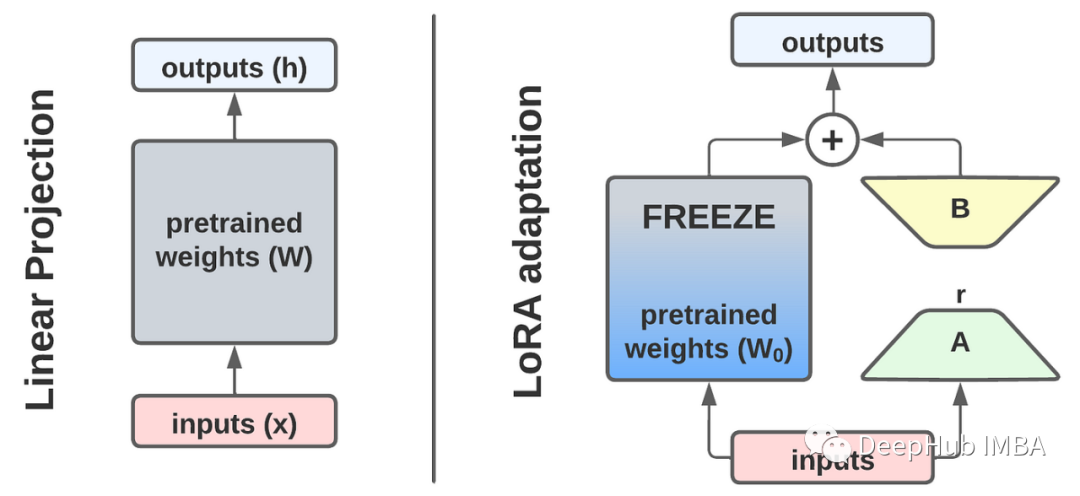
How LoRA Works
The basic idea of LoRA is to freeze the pre-trained matrix (i.e., parameters of the original model) and only add a small delta on top of the original matrix, with fewer parameters than the original matrix.
For example, matrix W, which could be the parameters of a fully connected layer or one of the matrices in the transformer attention mechanism:
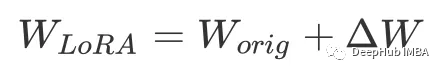
If the dimension of w-orig is n×m and we initialize a new matrix with the same dimensions for fine-tuning, it will double the parameters.
So we construct ΔW by performing matrix multiplication from low-dimensional matrices B and A, making it have “fewer dimensions” than the original matrix.
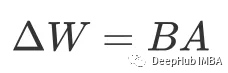
Here, we first define the rank r, which is less than the dimensions of the base matrix r≪n, r≪m. Thus, matrix B is an n×r matrix and A is an r×m matrix. Multiplying them gives a matrix with the same dimensions as W, but with fewer parameters.
We want to start training like the original model, so B is usually initialized to all zeros, while A is initialized to random (usually normally distributed) values.
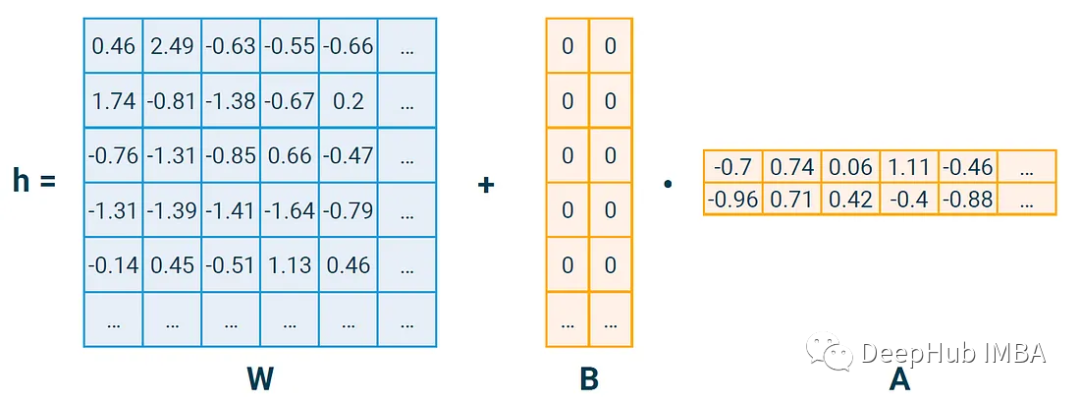
Assuming our base dimension is 1024 and we choose a LoRA rank r of 4, then:
W has 1024 * 1024≈1 million parameters; A and B each have r * 1024 = 4 * 1024≈4k parameters, totaling 8k which means we only need to train 0.8% of the parameters to update our matrix using LoRA. In the LoRA paper, they measure the delta matrix with the alpha parameter:

If you simply set α to r and fine-tune the learning rate, you can achieve results similar to those in the paper. We ignore this detail in the implementation below, but it is a common feature in many other LoRA libraries (e.g., Hugging Face’s PEFT).
Implementing LoRA by Hand
Our implementation here will be done in PyTorch. Although we aim to strictly follow the original LoRA paper, we have slightly simplified the code to make it easier to read while still demonstrating the essential elements.
We are using the RoBERTa model here. We create a new class LoraRobertaSelfAttention that extends Hugging Face’s implementation RobertaSelfAttention as a base class to initialize the LoRA matrices. All B matrices are initialized to zero, and all A matrices are initialized to random numbers from a normal distribution.
class LoraRobertaSelfAttention(RobertaSelfAttention): """ Extends RobertaSelfAttention with LoRA (Low-Rank Adaptation) matrices. LoRA enhances efficiency by only updating the query and value matrices. This class adds LoRA matrices and applies LoRA logic in the forward method.
Parameters: - r (int): Rank for LoRA matrices. - config: Configuration of the Roberta Model. """ def __init__(self, r=8, *args, **kwargs): super().__init__(*args, **kwargs) d = self.all_head_size
# Initialize LoRA matrices for query and value self.lora_query_matrix_B = nn.Parameter(torch.zeros(d, r)) self.lora_query_matrix_A = nn.Parameter(torch.randn(r, d)) self.lora_value_matrix_B = nn.Parameter(torch.zeros(d, r)) self.lora_value_matrix_A = nn.Parameter(torch.randn(r, d))Given these matrices, we need to define new class methods lora_query and lora_value. These compute the ΔW matrix, i.e., BA, and add it to the original matrix, calling the original matrices from the original method query and value.
class LoraRobertaSelfAttention(RobertaSelfAttention): # ...
def lora_query(self, x): """ Applies LoRA to the query component. Computes a modified query output by adding the LoRA adaptation to the standard query output. Requires the regular linear layer to be frozen before training. """ lora_query_weights = torch.matmul(self.lora_query_matrix_B, self.lora_query_matrix_A) return self.query(x) + F.linear(x, lora_query_weights)
def lora_value(self, x): """ Applies LoRA to the value component. Computes a modified value output by adding the LoRA adaptation to the standard value output. Requires the regular linear layer to be frozen before training. """ lora_value_weights = torch.matmul(self.lora_value_matrix_B, self.lora_value_matrix_A) return self.value(x) + F.linear(x, lora_value_weights)To use these methods, we must rewrite the original forward function of RobertaSelfAttention. Although this is somewhat hardcoded (discussions of improvements follow), it is very straightforward. First, we copy the original forward code from modeling_roberta.py. Then we replace every call to query with lora_query and every call to value with lora_value. The function then looks like this:
class LoraRobertaSelfAttention(RobertaSelfAttention): # ... def forward(self, hidden_states, *args, **kwargs): """Copied from https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py but replaced the query and value calls with calls to the lora_query and lora_value functions. We will just sketch of how to adjust this here. Change every call to self.value and self.query in the actual version. """ # original code for query: ## mixed_query_layer = self.query(hidden_states) # updated query for LoRA: mixed_query_layer = self.lora_query(hidden_states)
# The key has no LoRA, thus leave these calls unchanged key_layer = self.transpose_for_scores(self.key(hidden_states))
# original code for value: ## value_layer = self.transpose_for_scores(self.value(hidden_states)) # updated value for LoRA: value_layer = self.transpose_for_scores(self.lora_value(hidden_states))
# ... (rest of the forward code, unchanged)Thus, we have added the LoRA part to the attention layer. The remaining task is to replace the attention module in the original RoBERTa model.
Here we need to iterate through each named component of the RoBERTa model, check if it belongs to the RobertaSelfAttention class, and if so, replace it with LoraRobertaSelfAttention, while retaining the original weight matrices.
class LoraWrapperRoberta(nn.Module): def __init__(self, task_type, num_classes=None, dropout_rate=0.1, model_id="roberta-large", lora_rank=8, train_biases=True, train_embedding=False, train_layer_norms=True): """ A wrapper for RoBERTa with Low-Rank Adaptation (LoRA) for various NLP tasks. - task_type: Type of NLP task ('glue', 'squad_v1', 'squad_v2'). - num_classes: Number of classes for classification (varies with task). - dropout_rate: Dropout rate in the model. - model_id: Pre-trained RoBERTa model ID. - lora_rank: Rank for LoRA adaptation. - train_biases, train_embedding, train_layer_norms: Flags whether to keep certain parameters trainable after initializing LoRA.
Example: model = LoraWrapperRoberta(task_type='glue') """ super().__init__() # 1. Initialize the base model with parameters self.model_id = model_id self.tokenizer = RobertaTokenizer.from_pretrained(model_id) self.model = RobertaModel.from_pretrained(model_id) self.model_config = self.model.config
# 2. Add the layer for the benchmark tasks d_model = self.model_config.hidden_size self.finetune_head_norm = nn.LayerNorm(d_model) self.finetune_head_dropout = nn.Dropout(dropout_rate) self.finetune_head_classifier = nn.Linear(d_model, num_classes)
# 3. Set up the LoRA model for training self.replace_multihead_attention() self.freeze_parameters_except_lora_and_bias()self.replace_multihead_attention: replaces all attention layers in the neural network with our previously written LoraRobertaSelfAttention.
self.freeze_parameters_except_lora_and_bias: this will freeze all major parameters during training, so that the gradient and optimizer steps only apply to LoRA parameters and other parameters we want to keep trainable, such as normalization layers.
class LoraWrapperRoberta(nn.Module): # ...
def replace_multihead_attention_recursion(self, model): """ Replaces RobertaSelfAttention with LoraRobertaSelfAttention in the model. This method applies the replacement recursively to all sub-components.
Parameters ---------- model : nn.Module The PyTorch module or model to be modified. """ for name, module in model.named_children(): if isinstance(module, RobertaSelfAttention): # Replace RobertaSelfAttention with LoraRobertaSelfAttention new_layer = LoraRobertaSelfAttention(r=self.lora_rank, config=self.model_config) new_layer.load_state_dict(module.state_dict(), strict=False) setattr(model, name, new_layer) else: # Recursive call for child modules self.replace_multihead_attention_recursion(module)Then we recursively traverse all model parts and freeze all parameters we do not want to train anymore:
class LoraWrapperRoberta(nn.Module): # ...
def freeze_parameters_except_lora_and_bias(self): """ Freezes all model parameters except for specific layers and types based on the configuration. Parameters in LoRA layers, the finetune head, bias parameters, embeddings, and layer norms can be set as trainable based on class settings. """ for name, param in self.model.named_parameters(): is_trainable = ( "lora_" in name or "finetune_head_" in name or (self.train_biases and "bias" in name) or (self.train_embeddings and "embeddings" in name) or (self.train_layer_norms and "LayerNorm" in name) ) param.requires_grad = is_trainableThis is the simplest implementation of a LORA we have here, and next, let’s look at the results.
Benchmarking with GLUE and SQuAD
We evaluate using the GLUE (General Language Understanding Evaluation) and SQuAD (Stanford Question Answering Dataset) benchmarks.
The GLUE benchmark is a set of tests consisting of 8 different NLP tasks, including challenges like sentiment analysis, textual entailment, and sentence similarity, providing a strong measure of the model’s language adaptability and proficiency.
SQuAD focuses on evaluating question-answering models. It includes extracting answers from paragraphs of Wikipedia, where the model identifies relevant text spans. SQuAD v2 is a more advanced version that introduces unanswerable questions, increasing complexity and reflecting real-world situations where the model must recognize the absence of answers in the text.
For the benchmarks below, no hyperparameters were tuned, no multiple runs were performed (especially since smaller GLUE datasets are prone to random noise), no early stopping was done, and no fine-tuning was started from previous GLUE tasks (which is usually done to reduce the variability of small dataset noise and prevent overfitting).
Starting with a rank of 8 LoRA injected into the RoBERTa-base model, training for each task was precisely conducted 6 times. The learning rate linearly increased to the maximum value in the first 2 epochs, then linearly decayed to zero over the remaining 4 epochs. The maximum learning rate for all tasks was 5e-4. The batch size for all tasks was 16.
The RoBERTa-based model has 124.6 million parameters. With LoRA, we only have 420,000 parameters to train.
This means we are actually training only 0.34% of the original parameters. The number of parameters introduced by LoRA for these specific tasks is very small, with an actual disk size of only 1.7 MB.
After training, we reload the LoRA parameters and test performance on the validation set for each task. The results are as follows:

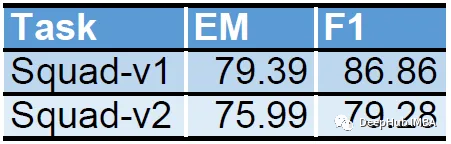
It clearly demonstrates that our LoRA implementation is effective and that the injected low-rank matrices are learning.
Improvement Ideas
Much of the code above is hardcoded, and one might wonder: “Are there more efficient and general methods (that can be transferred to other network architectures) than re-coding self-attention classes and performing complex replacements?”
In fact, we can simply implement a wrapper for nn.Linear, meaning we can directly replace layers by checking their names.
class LoraLinear(nn.Linear): """ Extends a PyTorch linear layer with Low-Rank Adaptation (LoRA). LoRA adds two matrices to the layer, allowing for efficient training of large models. """ def __init__(self, in_features, out_features, r=8, *args, **kwargs): super().__init__(in_features, out_features, *args, **kwargs)
# Initialize LoRA matrices self.lora_matrix_B = nn.Parameter(torch.zeros(out_features, r)) self.lora_matrix_A = nn.Parameter(torch.randn(r, in_features))
# Freeze the original weight matrix self.weight.requires_grad = False
def forward(self, x: Tensor) -> Tensor: # Compute LoRA weight adjustment lora_weights = torch.matmul(self.lora_matrix_B, self.lora_matrix_A) # Apply the original and LoRA-adjusted linear transformations return super().forward(x) + F.linear(x, lora_weights)Injecting LoRA into all linear layers has also become a fairly common practice. Since the biases and normalizations are already small, you don’t need to streamline them further.
Moreover, the above code is actually (close to) how the huggingface PEFT library implements LoRA. While our implementation is usable, it is strongly recommended to use PEFT, as we are not here to reinvent the wheel.
PEFT Usage Guide
We load the model in a quantized manner. Thanks to the integration of bitsandbytes with the transformers library (launched in May 2023), this is a breeze.
import bitsandbytes as bnb from transformers import AutoModel, AutoModelForSequenceClassification, BitsAndBytesConfig
# Configuration to load a quantized model bnb_config = BitsAndBytesConfig( load_in_4bit=True, # Enable 4-bit loading bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16, llm_int8_skip_modules=['classifier', 'qa_outputs'], # Skip these for quantization )
# Load the model from Huggingface with quantization model = AutoModelForSequenceClassification.from_pretrained('roberta-base', torch_dtype="auto", quantization_config=bnb_config)We are using 4-bit quantization loading, which may be a bit slower; we can also verify the 4-bit loading by checking the model’s modules and parameter data types:
# Verify 4-bit loading print("Verifying 4-bit elements (Linear4bit) in the attention layer:") print(model.roberta.encoder.layer[4].attention)
print("Checking for uint8 data type:") print(model.roberta.encoder.layer[4].attention.self.query.weight.dtype)Now we inject LoRA parameters using PEFT. The PEFT library locates the modules to be replaced by their names; thus, we need to look at model.named_parameters(). This is what a non-quantized roberta base model looks like.
Module Parameters ---------------------------------------------------------- ------------ roberta.embeddings.word_embeddings.weight 38_603_520 roberta.embeddings.position_embeddings.weight 394_752 roberta.embeddings.token_type_embeddings.weight 768 roberta.embeddings.LayerNorm.weight 768 roberta.embeddings.LayerNorm.bias 768 roberta.encoder.layer.0.attention.self.query.weight 589_824 roberta.encoder.layer.0.attention.self.query.bias 768 roberta.encoder.layer.0.attention.self.key.weight 589_824 roberta.encoder.layer.0.attention.self.key.bias 768 roberta.encoder.layer.0.attention.self.value.weight 589_824 roberta.encoder.layer.0.attention.self.value.bias 768 roberta.encoder.layer.0.attention.output.dense.weight 589_824 roberta.encoder.layer.0.attention.output.dense.bias 768 roberta.encoder.layer.0.attention.output.LayerNorm.weight 768 roberta.encoder.layer.0.attention.output.LayerNorm.bias 768 roberta.encoder.layer.0.intermediate.dense.weight 2_359_296 roberta.encoder.layer.0.intermediate.dense.bias 3_072 roberta.encoder.layer.0.output.dense.weight 2_359_296 roberta.encoder.layer.0.output.dense.bias 768 roberta.encoder.layer.0.output.LayerNorm.weight 768 roberta.encoder.layer.0.output.LayerNorm.bias 768 roberta.encoder.layer.1.attention.self.query.weight 589_824 ... roberta.encoder.layer.11.output.LayerNorm.bias 768 classifier.dense.weight 589_824 classifier.dense.bias 768 classifier.out_proj.weight 1_536 classifier.out_proj.bias 2 ---------------------------------------------------------- ------------ TOTAL 124_647_170We can then specify which layers to fine-tune with LoRA. All layers not injected with LoRA parameters will be frozen automatically. If we want to train layers in their original form, we can specify them by passing a list to the LoraConfig‘s modules_to_save parameter. In our case.
The following example injects LoRA with a rank of 2. We specify the alpha parameter as 8 because this was the rank we first tried, which should allow us to use the learning rate from the previous example.
import peft
# Config for the LoRA Injection via PEFT peft_config = peft.LoraConfig( r=2, # rank dimension of the LoRA injected matrices lora_alpha=8, # parameter for scaling, use 8 here to make it comparable with our own implementation target_modules=['query', 'key', 'value', 'intermediate.dense', 'output.dense'], # be precise about dense because classifier has dense too modules_to_save=["LayerNorm", "classifier", "qa_outputs"], # Retrain the layer norm; classifier is the fine-tune head; qa_outputs is for SQuAD lora_dropout=0.1, # dropout probability for layers bias="all", # none, all, or lora_only )
model = peft.get_peft_model(model, peft_config)Specifying more modules for LoRA injection may increase VRAM requirements. If you encounter VRAM limits, consider reducing the number of target modules or lowering the LoRA rank.
For training, especially QLoRA, choose optimizers compatible with quantized matrices. Replace the standard optimizer with bitsandbytes variants as follows:
import torch import bitsandbytes as bnb
# replace this optimizer = torch.optim.AdamW(args here) # with this optimizer = bnb.optim.AdamW8bit(same args here)Thus, you can train this model as before. After training, the process of saving and reloading the model is straightforward. Use model.save_pretrained to save the model, specifying the desired filename. The PEFT library will automatically create a directory at this location to store model weights and configuration files. This file includes essential details such as the base model and LoRA configuration parameters.
To reload the model using peft.AutoPeftModel.from_pretrained, pass the directory path as a parameter. The key point to remember is that the LoRA configuration currently does not retain the number of classes initialized for AutoModelForSequenceClassification. When using from_pretrained, this needs to be manually input as an additional parameter.
The reloaded model will contain the original base model with LoRA applied. If you decide to permanently integrate LoRA into the base model matrix, simply execute model.merge_and_unload().
Conclusion
We started with a simple (albeit hardcoded) LoRA implementation, delving into LoRA, its practical implementation, and benchmarking. We also introduced a more efficient implementation strategy and explored the advantages of existing libraries for LoRA integration, such as PEFT.
Edit: Yu Tengkai
Proofread: Lin Yilin