Selected from Raphael G’s blog
Translated by Machine Heart
Author: Raphael G
Editor: Big Chicken
Using LoRA to build faster AI models.
AI models are becoming increasingly powerful and complex, and their speed has become one of the standards for measuring advancement.
If AI is a luxury sports car, then the LoRA fine-tuning technology is the turbocharger that makes it accelerate. How powerful is LoRA? It can increase the processing speed of models by 300%. Remember the stunning performance of LCM-LoRA? It can achieve comparable results in one step where other models require ten.
How is this achieved? Raphael G’s blog details how LoRA achieves significant improvements in model inference efficiency and speed, as well as the enhancements in its implementation and its major impact on AI model performance. Below is a compilation and organization of this blog by Machine Heart without altering the original meaning.

Original blog link: https://huggingface.co/raphael-gl
We have significantly accelerated the inference speed of public LoRA based on public diffusion models in the Hub, saving a lot of computational resources and providing users with a faster and better experience.
To perform inference on a given model, there are two steps:
1. Pre-warming phase, including downloading the model and setting up the service — 25 seconds.
2. Then the inference work itself — 10 seconds.
With improvements, the pre-warming time can be reduced from 25 seconds to 3 seconds. Now, we only need less than 5 A10G GPUs to provide inference services for hundreds of different LoRAs, and the response time to user requests has decreased from 35 seconds to 13 seconds.
Next, let’s further discuss how to utilize some recently developed features in the Diffusers library to dynamically serve many different LoRAs through a single service.
LoRA is a fine-tuning technique that belongs to the series of “parameter-efficient fine-tuning” (PEFT) methods, which aim to reduce the number of trainable parameters affected during the fine-tuning process. It increases the fine-tuning speed while also reducing the size of the fine-tuning checkpoints.
The LoRA method does not fine-tune the model by making small changes to all of its weights; instead, it freezes most layers and only trains a few specific layers in the attention module. Additionally, we avoid touching the parameters of these layers by adding the product of two smaller matrices on top of the original weights. The weights of these small matrices are updated during fine-tuning and then saved to disk. This means that the original parameters of all models are preserved, allowing users to load LoRA weights adaptively on top of them.
The name LoRA (Low-Rank Adaptation) comes from the small matrices mentioned above. More information about this method can be found in the blog or the original paper below.

-
Related blog link: https://huggingface.co/blog/lora
-
Paper link: https://arxiv.org/abs/2106.09685
The image below shows two smaller orange matrices, which are saved as part of the LoRA adapter. Next, we can load the LoRA adapter and merge it with the blue base model to obtain the yellow fine-tuned model. Most importantly, we can also unload the adapter, allowing us to return to the original base model at any time.
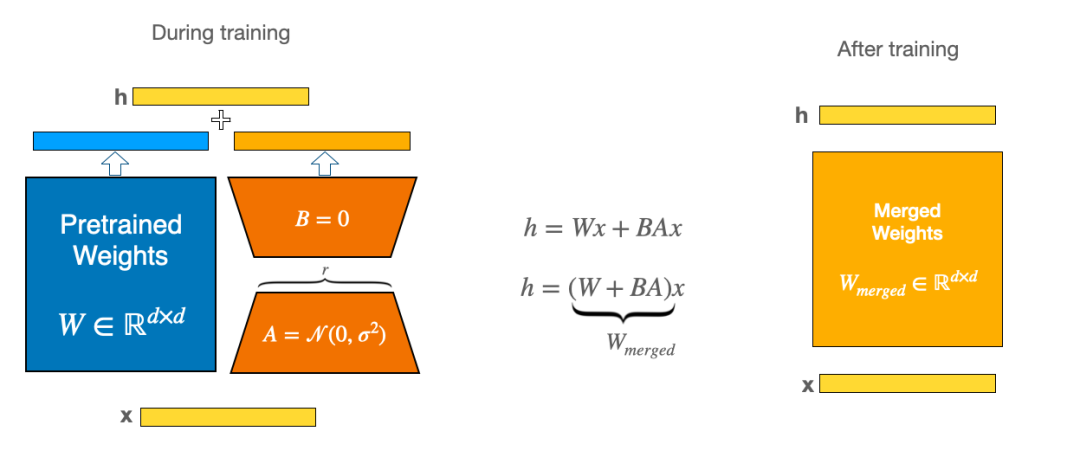
In other words, the LoRA adapter acts like an add-on to the base model that can be added and unloaded as needed. Due to its small size compared to the model size, it is very lightweight. Therefore, loading it is much faster than loading the entire base model.
For example, the Stable Diffusion XL Base 1.0 model repo, which is widely used as the base model for many LoRA adapters, is about 7 GB in size. However, a typical LoRA adapter like this only takes up 24 MB of space.
On the Hub, the number of blue base models is far less than the yellow models. If we can quickly switch from blue to yellow and vice versa, we have a way to serve many different yellow models with only a few different blue deployments.
There are about 2500 different public LoRAs on the Hub, the vast majority of which (about 92%) are based on the Stable Diffusion XL Base 1.0 model.
Before this sharing mechanism, dedicated services had to be deployed for all these models (for example, all the yellow merged matrices in the image above), which would take up at least one new GPU. The time to start the service and be ready to serve requests for a specific model was about 25 seconds, in addition to the inference time, which took about 10 seconds for 25 inference steps on an A10G for 1024×1024 SDXL diffusion. If an adapter was only occasionally requested, its service would be stopped to free up resources occupied by other adapters.
If the LoRA you requested is not very popular, even if it is based on the SDXL model, it would still take 35 seconds to pre-warm and respond to the first request, just like the vast majority of adapters found on the Hub so far.
However, the above has become a thing of the past, as the request time has now been reduced from 35 seconds to 13 seconds, because adapters will only use a few different “blue” base models (like the two important models of Diffusion). Even if your adapter is not very popular, its “blue” service is likely already pre-warmed. In other words, even if you do not often request your model, you are likely to avoid the 25 seconds of pre-warming time. The blue model has already been downloaded and is ready; all we need to do is unload the previous adapter and load the new one, which only takes 3 seconds.
Overall, although we already have ways to share GPUs across different deployments to fully utilize their computing power, we still need fewer GPUs to support all different models. Within 2 minutes, about 10 different LoRA weights are requested. We only need to use 1 to 2 GPUs (possibly more if there is a burst of requests) to serve all these models without starting 10 deployments and keeping them running.
We have implemented LoRA sharing in the inference API. When a request is made for a model on the platform, we first determine whether it is a LoRA, then identify the base model of the LoRA, and route the request to a common backend server cluster capable of serving that model.
Inference requests are served by keeping the base model running and dynamically loading/unloading LoRA. This way, you can reuse the same computing resources to serve multiple different models simultaneously.
In the Hub, LoRA can be identified by two attributes:
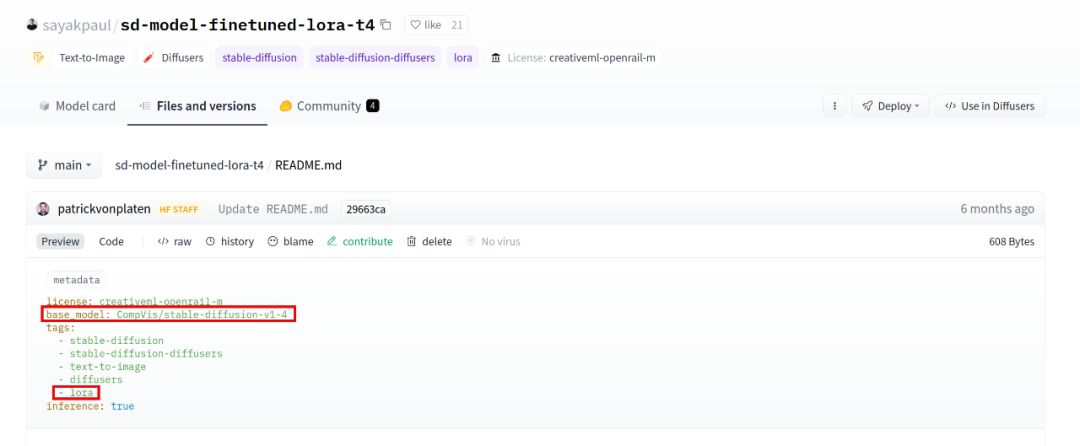
LoRA will have a base_model attribute, which is the base model on which LoRA is built for use during inference. Since not only LoRA has such attributes (any replicated model will have one), it also needs a lora tag for proper identification.
Every time inference takes an additional 2 to 4 seconds, we can serve many different LoRAs. However, on A10G GPUs, inference time is greatly reduced, while the loading time of adapters does not change much, making the loading/unloading cost of LoRA relatively higher.
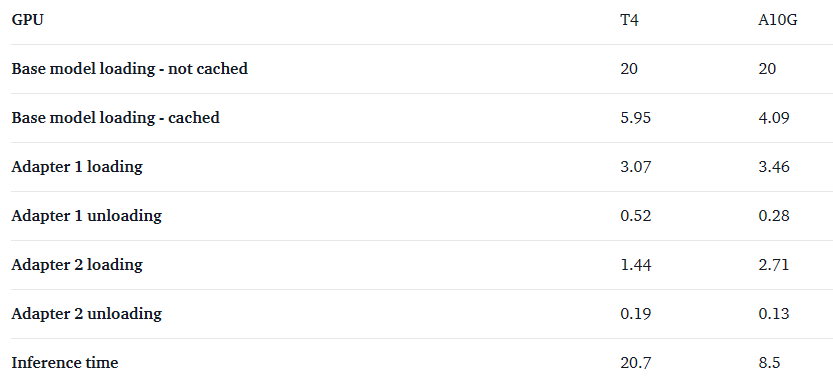 All numbers are in seconds.
How about batch processing?
Recently, there was a very interesting paper that introduced how to improve throughput by performing batch inference on LoRA models. In short, all inference requests will be collected in batches, and the computations associated with the general base model will be completed at once, and then the remaining specific adapter products will be calculated.
All numbers are in seconds.
How about batch processing?
Recently, there was a very interesting paper that introduced how to improve throughput by performing batch inference on LoRA models. In short, all inference requests will be collected in batches, and the computations associated with the general base model will be completed at once, and then the remaining specific adapter products will be calculated.

Paper link: https://arxiv.org/pdf/2311.03285.pdf
We did not adopt this technology. Instead, we adhered to individual sequential inference requests. Because we observed that for the diffusers, the throughput does not significantly increase with the batch size. In our simple image generation benchmark tests, when the batch size was 8, the throughput only increased by 25%, while the latency increased 6 times.
For more information on loading/unloading LoRA, please read the original blog.
© THE END
Please contact this public account for authorization to reprint
Submissions or inquiries: [email protected]
