Research Background
- Research Question
- The problem this paper aims to address is the minimal performance improvement of Multi-Agent Large Language Model (LLM) systems (referred to as MAS) compared to single-agent frameworks. Despite the potential of MAS in handling complex multi-step tasks and interacting with dynamic environments, their accuracy or performance improvements remain limited in popular benchmark tests.
- The challenges in researching this issue include: how to comprehensively analyze the challenges hindering the effectiveness of MAS; how to identify the various failure modes leading to the failure of MAS; and how to propose effective improvements to enhance the performance and reliability of MAS.
- In terms of challenges in agent systems, previous studies have proposed relevant solutions for specific agent challenges, such as addressing long-range navigation issues through the introduction of workflow memory. However, these works do not comprehensively understand the reasons for MAS failures and do not propose strategies that can be widely applied across various fields.
- Regarding design principles for agent systems, some studies emphasize the challenges of building robust agent systems and propose new strategies, but these studies mainly focus on single-agent design and lack comprehensive research on failure modes in MAS.
- In the classification of failures in LLM systems, there is limited specialized research on the failure modes of LLM agents. This paper fills that gap by providing pioneering research on the failure modes of MAS.
Overall Conclusion
The research findings of the paper indicate that the failure of MAS is not solely due to the limitations of LLMs, but more importantly, due to structural defects present in the design of MAS. Future research should focus on improving the design principles and organizational structure of MAS to enhance their reliability and performance. The main contributions of the paper include:
- Introducing MASFT, the first empirical classification method for MAS failures, providing a structured framework for understanding and mitigating MAS failures.
- Developing a scalable LLM-as-a-judge evaluation process for analyzing new MAS performance and diagnosing failure modes.
- Conducting intervention studies on agent specifications, dialogue management, and validation strategies. Although some improvements were achieved, they highlighted the necessity for a structural redesign of MAS.
- Open-sourcing relevant datasets and tools to facilitate further research on MAS.
Research Methodology
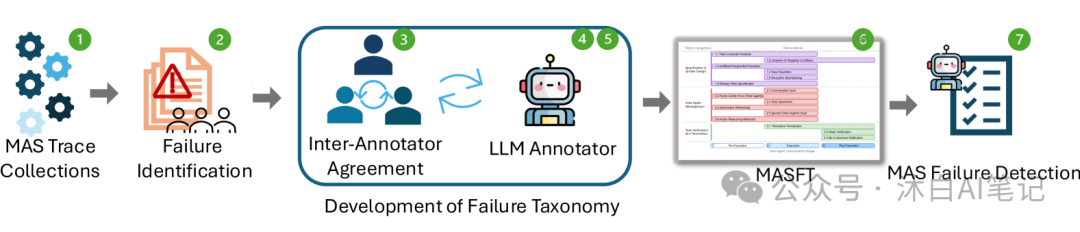
 This paper proposes a classification method for Multi-Agent System failures (MASFT) to address the failures of Multi-Agent Large Language Model systems. Specifically,
This paper proposes a classification method for Multi-Agent System failures (MASFT) to address the failures of Multi-Agent Large Language Model systems. Specifically,
- Data Collection and Analysis
- Theoretical sampling methods were used to select a diverse set of multi-agent systems and tasks, collecting over 150 dialogue trajectories from five popular open-source MAS for analysis. Each trajectory contains an average of over 15,000 lines of text.
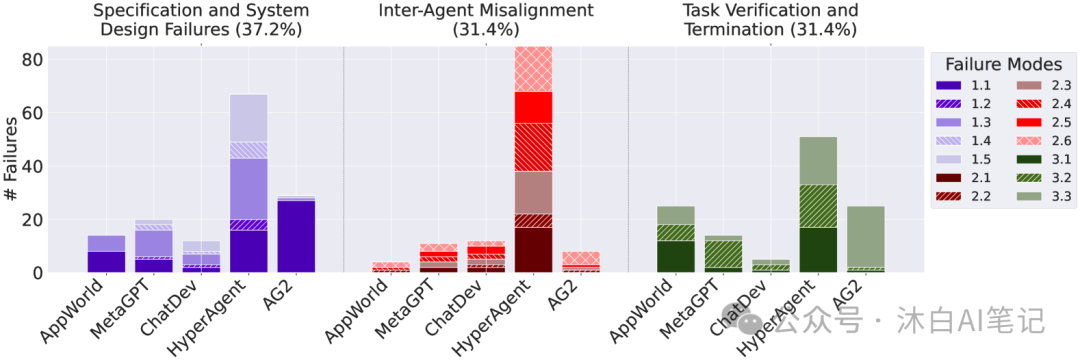
- Specification and System Design Failures: Including non-compliance with task specifications (15.2%), non-compliance with role specifications (1.57%), step repetition (11.5%), dialogue history loss (2.36%), and unawareness of termination conditions (6.54%), etc.
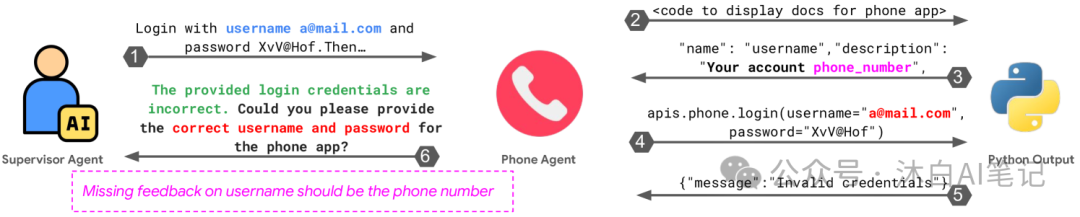
- Agent Misalignment: Including dialogue resets (5.50%), failure to clarify (2.09%), task derailment (5.50%), information withholding (6.02%), ignoring inputs from other agents (4.71%), reasoning-action mismatch (7.59%), etc.
- Task Validation and Termination: Including premature termination (9.16%), no or incomplete validation (3.2%), incorrect validation (3.3%), etc.
- Through theoretical sampling, open coding, constant comparative analysis, memoing, and theoretical iteration, 14 different failure modes were identified.
- The failure modes were clustered into three main failure categories:
- By having three expert annotators independently label 15 trajectories, inter-annotator consistency was achieved with a Cohen’s kappa score of 0.88, continuously iterating to adjust failure modes and categories, ultimately forming a structured MASFT classification method.
- Introducing a scalable automated evaluation process using OpenAI’s O1 LLM-as-a-judge framework. Cross-validation with three human expert annotators on 10 trajectories yielded a Cohen’s kappa consistency rate of 0.77.
Experimental Design
- Data Collection: Analyzed five popular open-source MAS (MetaGPT, ChatDev, HyperAgent, AppWorld, AG2) involving over 150 tasks, employing six expert annotators in the study.
- Sample Selection: Selected representative multi-agent systems and tasks covering different application scenarios and system architectures to ensure the broad applicability of the research findings.
- Parameter Configuration: During the experiments, detailed analysis and evaluation of different MAS systems were conducted, including tracking and analyzing their execution trajectories and identifying and classifying various failure modes.
Empirical Data
| System Name | Success Rate | Failure Rate | Test Scenario |
|---|---|---|---|
| MetaGPT | 66.0% | 34.0% | programdev |
| ChatDev | 25.0% | 75.0% | programdev |
| HyperAgent | 25.3% | 74.7% | SWE-bench lite |
| AppWorld | 13.3% | 86.7% | test-c |
| AG2 | 84.8% | 15.2% | GSM-Plus |
Results and Analysis
- Failure Mode Analysis
- Through detailed analysis and evaluation, 14 different failure modes were identified and classified into three main failure categories. These failure modes are prevalent across different MAS systems, leading to decreased system performance and increased task failure rates.
- For example, in the specification and system design failure category, the failure rates for non-compliance with task specifications and role specifications were high, at 15.2% and 1.57%, respectively; in the agent misalignment category, failure modes such as dialogue resets and reasoning-action mismatches were also common.
- Comparing the accuracy of the state-of-the-art open-source MAS ChatDev with GPT-4o and Claude-3, results show that ChatDev’s accuracy may be as low as 25%, indicating a significant performance gap when compared to existing advanced models.
- Two intervention measures were implemented: improving agent role specifications and enhancing orchestration strategies. Case studies on AG2 and experiments with ChatDev indicated that while these interventions brought a +14% improvement to ChatDev, they did not resolve all failure situations, and the improved performance remains insufficient for practical deployment.
Original link: https://arxiv.org/html/2503.13657v1