


As an innovative pioneer in the field of artificial intelligence, DeepSeek has empowered existing AI agents with enhanced task execution and decision support capabilities through its groundbreaking technology. However, questions remain regarding the innovations and practical value that enterprises can gain by integrating DeepSeek, how it can break development bottlenecks, and the effectiveness of its application scenarios.
This article will explore how to drive new transformations in digital operations for enterprises through the integration of DeepSeek and existing large models, based on the practices of Shushi Technology.
Guest Speaker | Cen Runzhe, General Manager of Data Intelligence Products at Shushi TechnologyThe content has been condensed; for the full expert video recording and presentation materials, please scan the QR code to obtain. 01The Arrival of DeepSeek is a “Natural Benefit” for Big Data Analysis and Application Fields In the data application track, DeepSeek has brought numerous changes and advantages. In the field of data analysis, after integrating DeepSeek, its enhanced mathematical and programming capabilities provide significant advantages, greatly improving the ability to process, statistically analyze, and analyze complex data. In the data application field, coding ability and mathematical capability are crucial. With the arrival of DeepSeek, whether in the early stages of data cleaning and feature extraction, the mid-stage construction of indicator systems and semantic layers, or the later stages of data visualization and report generation, the enhancement of mathematical and reasoning capabilities has positively impacted the entire data application mechanism. Especially in complex data cleaning, data visualization, and deep report generation, DeepSeek has brought many benefits.
01The Arrival of DeepSeek is a “Natural Benefit” for Big Data Analysis and Application Fields In the data application track, DeepSeek has brought numerous changes and advantages. In the field of data analysis, after integrating DeepSeek, its enhanced mathematical and programming capabilities provide significant advantages, greatly improving the ability to process, statistically analyze, and analyze complex data. In the data application field, coding ability and mathematical capability are crucial. With the arrival of DeepSeek, whether in the early stages of data cleaning and feature extraction, the mid-stage construction of indicator systems and semantic layers, or the later stages of data visualization and report generation, the enhancement of mathematical and reasoning capabilities has positively impacted the entire data application mechanism. Especially in complex data cleaning, data visualization, and deep report generation, DeepSeek has brought many benefits.

From a technical perspective, its reasoning chain is extremely beneficial for data analysis. Among the many financial institutions served by Shushi, a common issue with previous large models was that while they could provide answers, the reasoning process was opaque. However, in DeepSeek’s papers, it is possible to enhance the basic model from V3 to a reinforced model called DeepSeek-R1-Zero. Reinforcement learning not only rewards accuracy but also emphasizes the normativity of the process and structure. The advantage of this mechanism is that it can not only accurately perform data analysis but also present a clear reasoning process to users. For example, when users conduct business analysis, DeepSeek can present the thought process in a step-by-step format, indicating which dimensions to select and what indicators to use. This incentive mechanism greatly enhances the persuasiveness of data analysis reports, making it a highlight in the field of data applications.
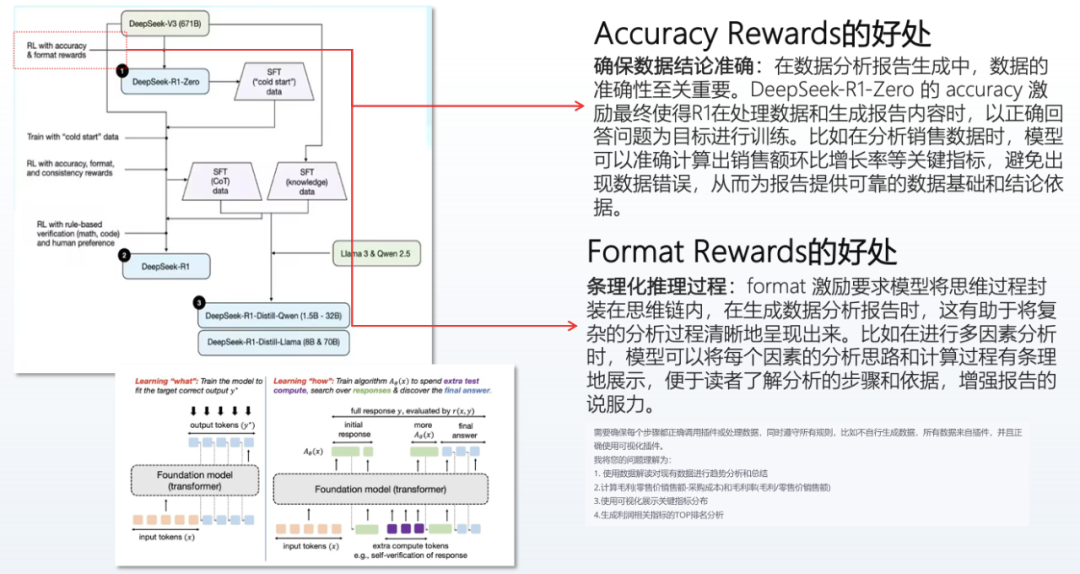
As a reasoning model, R1 pays great attention to Token output during reasoning; the more Tokens output, the more detailed the thinking, and the lower the probability of error. In complex code generation, mathematical calculations, and decision-making, R1 performs significantly better than distilled versions or Qianwen models. However, R1 has a speed issue, as processing complex tasks requires more Tokens for reasoning. Therefore, a combined approach can be adopted, using a relatively small parameter model (e.g., 32B) after distillation for task classification and entity extraction. This model performs similarly to R1 in this regard but is faster. However, when users’ data analysis tasks are extremely complex, reasoning models like R1 may be invoked for deep reasoning and planning to better meet users’ analytical needs.
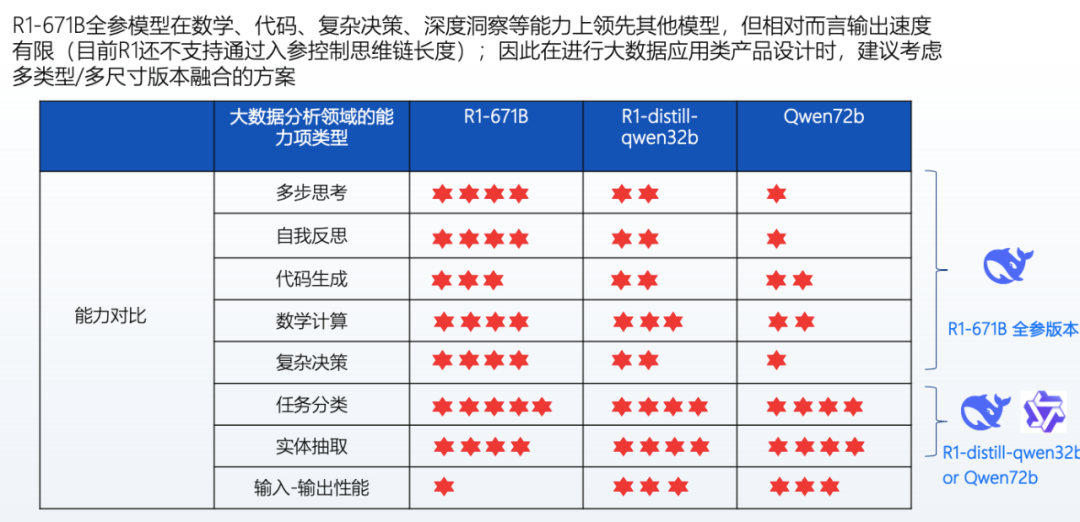
Based on recent discussions with multiple financial institutions regarding model selection, if the scenario primarily involves meeting users’ rapid data retrieval needs, such as inquiring about the balance growth rate for a certain month, there is no need to invoke long reasoning models like R1 for complex task decomposition; the V3 model can be used for reading recognition and element extraction to quickly retrieve data. However, if the user’s analytical needs are not merely simple data extraction but involve writing credit reports or detailed analyses of bank credit asset growth, the rapid thinking of the V3 model may not suffice. In such cases, the reasoning model R1 is more suitable, as it can decompose tasks. For instance, when reviewing performance comparisons in branch industries, it can identify the indicators to focus on and break down the tasks into specific steps. Therefore, many mainstream AI products now feature a button for “enabling deep thinking.” In a sense, this allows users to choose whether to engage in fast or slow thinking through product functionality. In the future, such integrated solutions may become standard across many products.
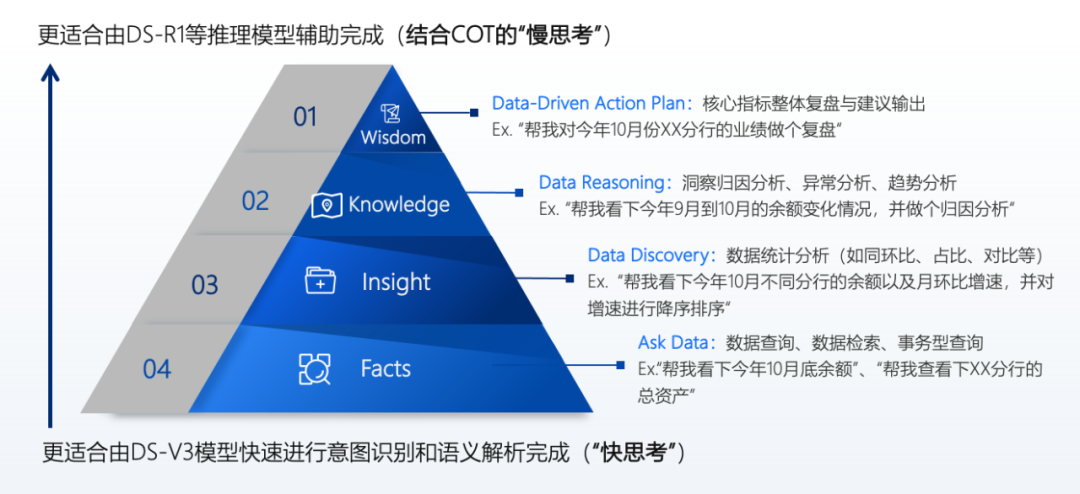
02Innovation and Application of Shushi SwiftAgent Currently, Shushi has added a “deep thinking” button in SwiftAgent. Once users enable this button, the R1 model will be invoked for deep reasoning and analysis. Shushi’s tools primarily target leading enterprises, and after integrating DeepSeek, several capability features have been upgraded, significantly enhancing the capabilities of large models in four aspects.

Frontend code generation capability is outstanding. Experiments have shown that allowing R1 to generate code based on raw data results in a very strong ability to quickly obtain visual presentations on the frontend. Previously, users often relied on BI tools to configure a series of dashboards or cockpits, but now, directly providing raw data to R1 for generating H5 or JS code has shown excellent performance, greatly enhancing visualization capabilities.Secondly, reasoning capabilities have significantly improved the depth of reports. Previous models could only provide some basic, shallow statements, but now they can genuinely consider whether indicators have issues and whether hypothesis inference is necessary, greatly enhancing the quality and depth of reports. The difficulty in data analysis lies in the accuracy of indicator definitions; conclusions must be inferred based on indicator anomalies, and sometimes reasonable suggestions must be generated by combining internal knowledge bases or related documents. When data needs to be visually presented, such as converting to tables for comparison or conducting anomaly conclusion mining, the depth of thought is superior to previous models like Qianwen, and the entire process is observable to users. For example, in financial data anomaly analysis, when users input financial data, the model can clearly inform users that an anomaly analysis is being conducted due to a decline in a certain indicator, and each node in the reasoning process can intuitively explain the reasons for the analysis to users. As a result, when presenting reports, users can clearly understand the logic behind the report writing, unlike previous large models that output results with content but lacked clarity in the basis for analysis. From this perspective, the transparency of the large model’s reasoning process is a significant transformation, greatly enhancing users’ trust in the results and improving the ability to interpret data reports. Previously, reports might have only contained plain text, but now they can incorporate images, tables, and other data visualization elements, providing users with a better experience.
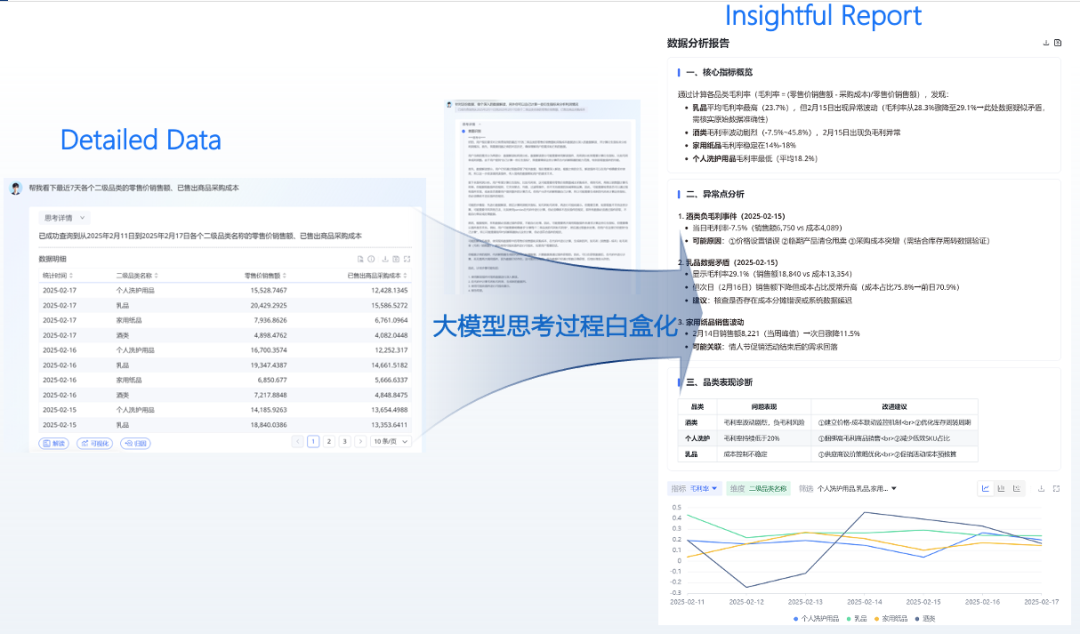
Additionally, determining which capabilities are suitable for direct code generation by large models and which are better suited for tool invocation is essential. Currently, large models have strong coding capabilities, but sometimes it is still necessary to write Function Code rather than directly allowing large models to generate code. This mainly divides into two situations: if the coding paradigm can be solidified, the accuracy of large models writing code will be very high. For example, in the case of charts, basic charts have fixed paradigms; from the perspective of data analysis visualization, their patterns are already fixed, and pie charts, for instance, have a consistent presentation method. In such cases, large models perform excellently when writing code and generally do not make mistakes. However, for codes with flexible business logic, large models are less suitable for direct writing. Business logic often involves associations between fact tables and dimension tables in databases, which have strong business logic, and the relationships between tables can vary significantly between different companies. If large models are forced to write complex association codes involving three to four tables, the generated code often has issues. Therefore, it is recommended to use the API of the indicator platform to obtain data, achieving data dimension stitching, which is a more appropriate approach.
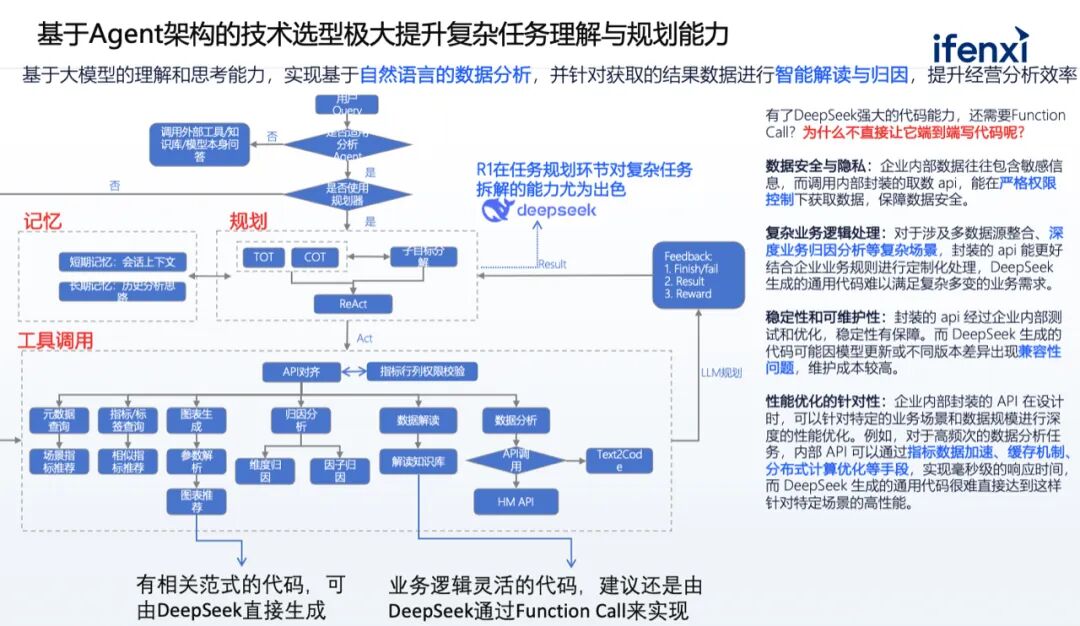
03Case Studies and Outlook in the Financial Industry Below, we will share a successful case of a city commercial bank conducting intelligent data analysis. Recently, this bank replaced its internal Qianwen model with DeepSeek V3 and R1, achieving certain performance improvements. The main issue faced by this client product was addressing the pain points of bank leaders in data extraction and analysis. This bank previously relied on analysts to manually extract data tables to provide leaders with reports on income, loan and deposit situations, and interbank liabilities. For bank leaders, their data needs are quite flexible; they may focus on the balance growth rate of several branches today and performance rankings tomorrow. However, the bank lacks sufficient analysts to meet these diverse needs. Therefore, the bank hopes to leverage a natural language query mechanism to both free up analysts’ time and enhance data retrieval efficiency; on the other hand, it aims to provide leaders with more agile attribution analysis and report analysis capabilities to gain insights into the reasons for changes in internal indicators, thereby significantly improving work effectiveness and efficiency. In the first week after the project was completed, leaders submitted thousands of query requests, and the system usage rate was high. At the same time, combined with the semantic layer of indicators, data accuracy was high, and the time from inquiry to data output was generally only about 5 seconds.

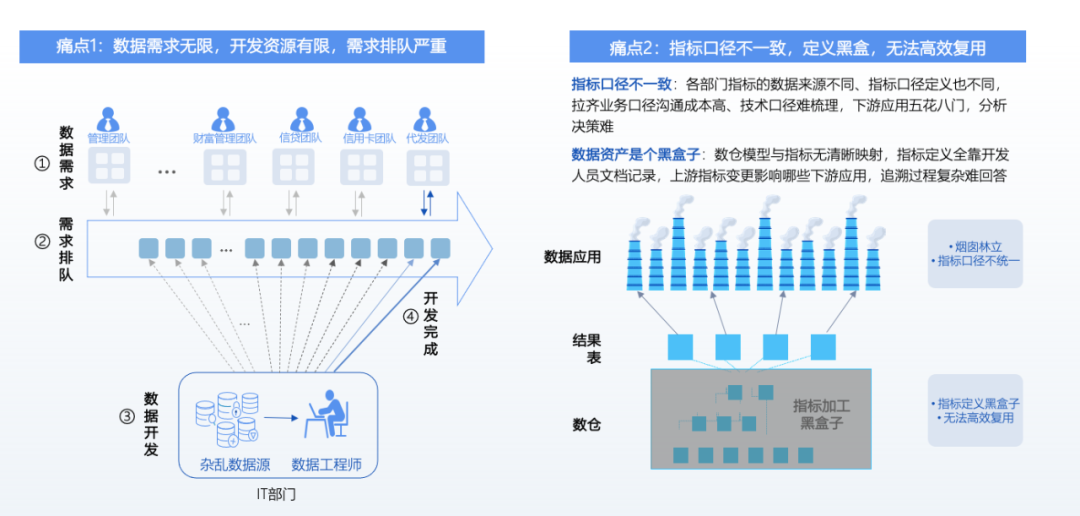
The implementation of this project, as well as the pursuit of similar services by many enterprises, fundamentally stems from two issues.
- Mismatch between Demand and Supply. Even leading banks or large enterprises may have analysts and ETL personnel, but as business continues to expand and demand grows, it is impossible for enterprises to recruit an equal number of engineers to write scripts to meet all demands, leading to a mismatch between human resource supply and demand. Therefore, enterprises hope to leverage AI agents to meet daily data retrieval and analysis needs, freeing up human resources.
- Black Box Issues at the Indicator Definition Level. Different departments may have different understandings of the same indicator name, leading to inconsistencies in definitions within the underlying data warehouse. Therefore, constructing a semantic layer for indicators to unify definitions and create a common data language among departments has become an urgent issue to address.
The implementation plan integrates the capabilities of large models with the interactive capabilities of the semantic layer for indicators. When users pose questions, the large model first makes a judgment. If the task is complex, such as generating a deep attribution report, the requirement is routed to DeepSeek R1 for processing; if it is merely simple data extraction, such as extracting data based on time, organization, loan balance, etc., the V3 model or a faster model can suffice. Thus, the large model first performs intent understanding, and if it is a complex task, it enters the task planning phase, where multi-task orchestration occurs. In the indicator query phase, the semantic layer extracts elements from users’ natural language. For example, when a user inquires about the performance of various branches, the branch serves as a dimension, the past three months as time, and performance corresponds to several indicators, which involves a mapping logic. Finally, these indicator semantic logics are translated into SQL statements for execution, and reports are summarized and fed back to users through reasoning models like R1. Currently, large models have limited capabilities in complete data extraction due to their limited understanding of the logic of SQL base tables, but they perform excellently in task recognition and report generation. Therefore, distinguishing between the strengths and weaknesses of large models and integrating solutions can better implement related projects.
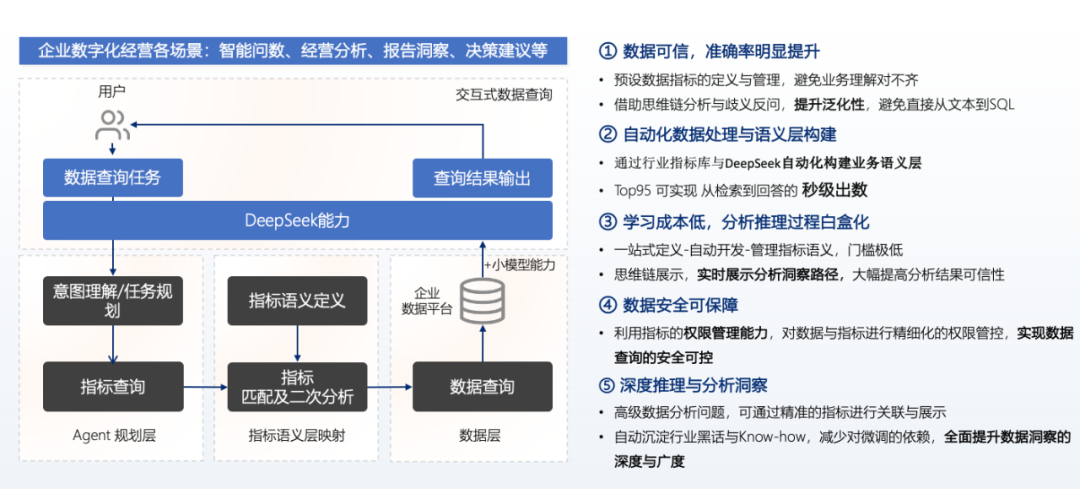
The technical team of this bank attempted to directly use the R1 model to generate SQL. When the table structure is relatively simple, such as querying assets over the past 7 days, the SQL generated by R1 can run normally. However, when the task instructions in the question are numerous and involve not only data extraction but also attribution analysis and report writing, completing this solely through code generation tools becomes challenging. At this point, R1 will first be used for multi-task planning; the first task may be data extraction, the second task may involve dimension attribution through a small model for attribution analysis, and finally, reports will be generated using the knowledge base. By combining the Agent architecture with Function Code, it can better meet the analytical needs of business parties in real complex business scenarios, which include not only data extraction but also high-level data insights, attribution, anomaly detection, and report writing, which are actual challenges enterprises face.When providing services to this financial institution, a phased approach was adopted. It is not feasible to cover all scenarios from the outset. In the first phase of the project, the focus was on natural language analysis and report generation needs for performance indicators within the bank. In the second phase, the focus shifted to actual business scenarios, such as credit and corporate loan businesses, conducting risk assessments, financial analyses, or credit card analyses, gradually expanding from the headquarters perspective to various business lines and scenarios. After the first phase of the project went live, user experience was positive. Previously, whether for the bank president or branch leaders, the data extraction process involved submitting requests to analysts, who would process them, a process that could take up to 4 hours. Now, the algorithm can proactively help users identify indicator issues, such as informing users of recent changes in non-performing loan rates or loan balances, prompting leaders to pay attention. If leaders wish to further understand the reasons for poor performance in various institutions, they can inquire based on dimensions such as branch, product type, or customer type. Finally, if leaders need to report to the head office, the system can generate simple reports containing reasons for anomalies and countermeasures by combining the existing database and knowledge base of the enterprise. After integrating DeepSeek, the bank believes that its reasoning chain generation and data interpretation modules have been significantly enhanced. Previously, reports might have contained only plain text, but now they incorporate tables, subtexts, charts, and text, greatly improving the readability and interpretability of reports, which is one of the advantages of integrating DeepSeek.

Finally, I would like to share some insights into the future of DeepSeek, especially regarding the evolution direction of reasoning models.First, the emergence of DeepSeek has achieved AI equity. This achievement is significant, as it means that both leading enterprises and medium-sized enterprises have the resources and capabilities to deploy open-source models, placing large and small enterprises on equal footing, which reflects the development of AI platforms. In the future, data application components will be centered around DeepSeek, with analysis components operating in coordination as execution parts, allowing a powerful core to effectively collaborate with different skill pools to better meet enterprise needs.
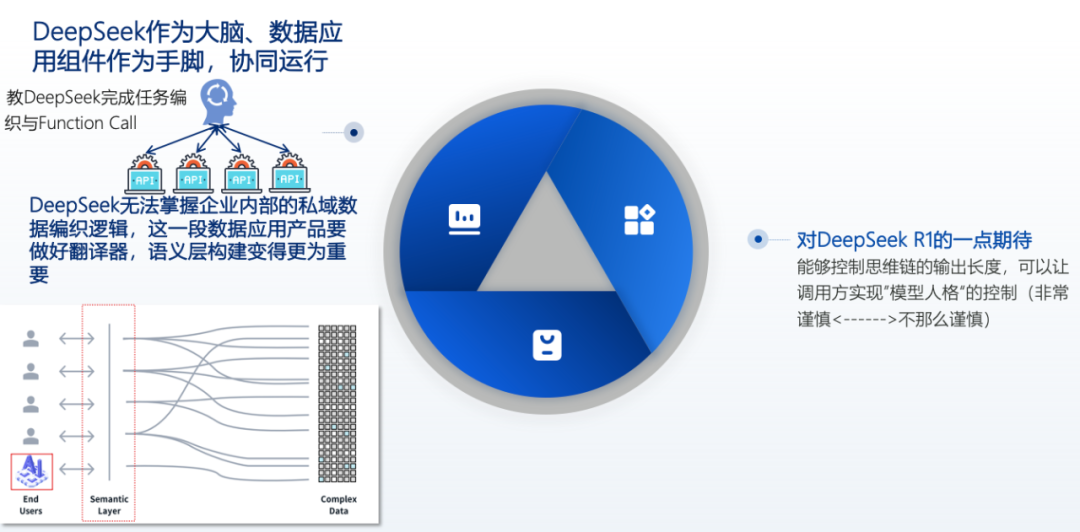
Second, DeepSeek currently cannot grasp the private knowledge and data weaving logic within enterprises. In this case, data application products need to act as “translators.” That is, a semantic layer must be constructed between the reasoning model and the complex data structures of enterprises, serving as a bridge connecting users’ natural language with the underlying data table architecture, but this is a capability that large models cannot achieve. The reason is that DeepSeek’s current context processing capability is 64K or 128K, while the actual data volume in enterprises can reach dozens of PB or even hundreds of PB in large institutions. Clearly, it is impossible to input all data into the model for analysis. Therefore, in the future, its 64K or 128K context is more suitable for reasoning, breaking down tasks in detail, and then having “hands and feet” components execute them one by one to obtain data, conduct relevant analyses, and summarize results for the core to generate reports, which is a more feasible model.Third, there is currently an issue with R1 regarding the inability to control the length of the reasoning chain, which sometimes leads to verbose outputs. If R1 makes progress in the future, it is hoped that it can achieve control over model outputs. For example, in certain scenarios, it could limit Token outputs to under 1000, while in others, allow for 2000 Tokens. If future control over Tokens can be achieved, it will enable flexible selection of output styles across various application scenarios. For instance, choosing a “cautious” output would yield more rigorous answers, while opting for a relatively lively and concise output style would be possible.

Long press the QR code to obtain the full video recording and presentation materials.
 Currently the General Manager of Data Intelligence Products at Shushi Technology, previously a senior quantitative operations leader at a leading internet company, with years of experience in data mining and user operation strategy design in the retail and financial industries, having built full-link digital operation platforms for many large enterprises from goal setting, data diagnosis, strategy design to optimization review.Note:Click the lower left corner“Read the original text” to obtain the full expert recording and shared materials..
Currently the General Manager of Data Intelligence Products at Shushi Technology, previously a senior quantitative operations leader at a leading internet company, with years of experience in data mining and user operation strategy design in the retail and financial industries, having built full-link digital operation platforms for many large enterprises from goal setting, data diagnosis, strategy design to optimization review.Note:Click the lower left corner“Read the original text” to obtain the full expert recording and shared materials..

