Click below to follow, the article comes from
🙋♂️ Friends who want to join the community can see the method at the end of the article for group communication.
“ Despite the theoretical appeal of multi-agent systems, their performance in practical applications often falls short of expectations. According to research, even advanced open-source multi-agent systems like ChatDev can have accuracy rates as low as 25%.”

Hello everyone, I am Si Ling Qi, and today I want to discuss why multi-agent systems fail. Multi-agent LLM systems have received much attention as they collaborate through multiple large language model agents to accomplish complex tasks. However, despite the enthusiasm for multi-agent systems, their actual performance often leaves much to be desired, with limited performance improvements compared to single-agent systems. What problems are hidden behind this? Let’s take a look at the paper “Why Do Multi-Agent LLM Systems Fail?”.
Why Do Multi-Agent LLM Systems Fail?
Multi-agent LLM systems are gradually becoming a research hotspot. These systems can handle complex, multi-step tasks and dynamically interact with diverse environments through the collaboration of multiple agents. They show great potential in fields such as software engineering, drug discovery, scientific simulation, and general intelligence. However, despite the theoretical appeal of multi-agent systems, their performance in practical applications often falls short of expectations. According to research, even advanced open-source multi-agent systems like ChatDev can have accuracy rates as low as 25%. This raises the question: why are multi-agent LLM systems struggling to achieve ideal performance?
To answer this question, researchers conducted a comprehensive analysis of five popular multi-agent LLM systems, including AG2, AppWorld, ChatDev, HyperAgent, and MetaGPT. The study employed a Grounded Theory approach, involving theoretical sampling, open coding, constant comparative analysis, memo writing, and theory construction, to conduct an in-depth analysis of over 150 dialogue trajectories. Six expert annotators independently annotated 15 trajectories, achieving a Cohen’s Kappa score of 0.88 for consistency, thereby identifying 14 unique failure modes and categorizing them into three main failure categories.
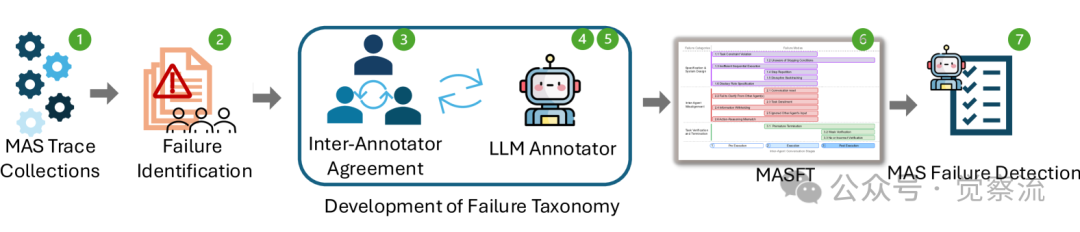
This flowchart helps us understand the overall framework and methodology of the research. From the figure below, we can see that the failure rates of these systems in the study vary significantly, indicating substantial differences in design and implementation among different systems.
Analysis of Failure Categories and Modes
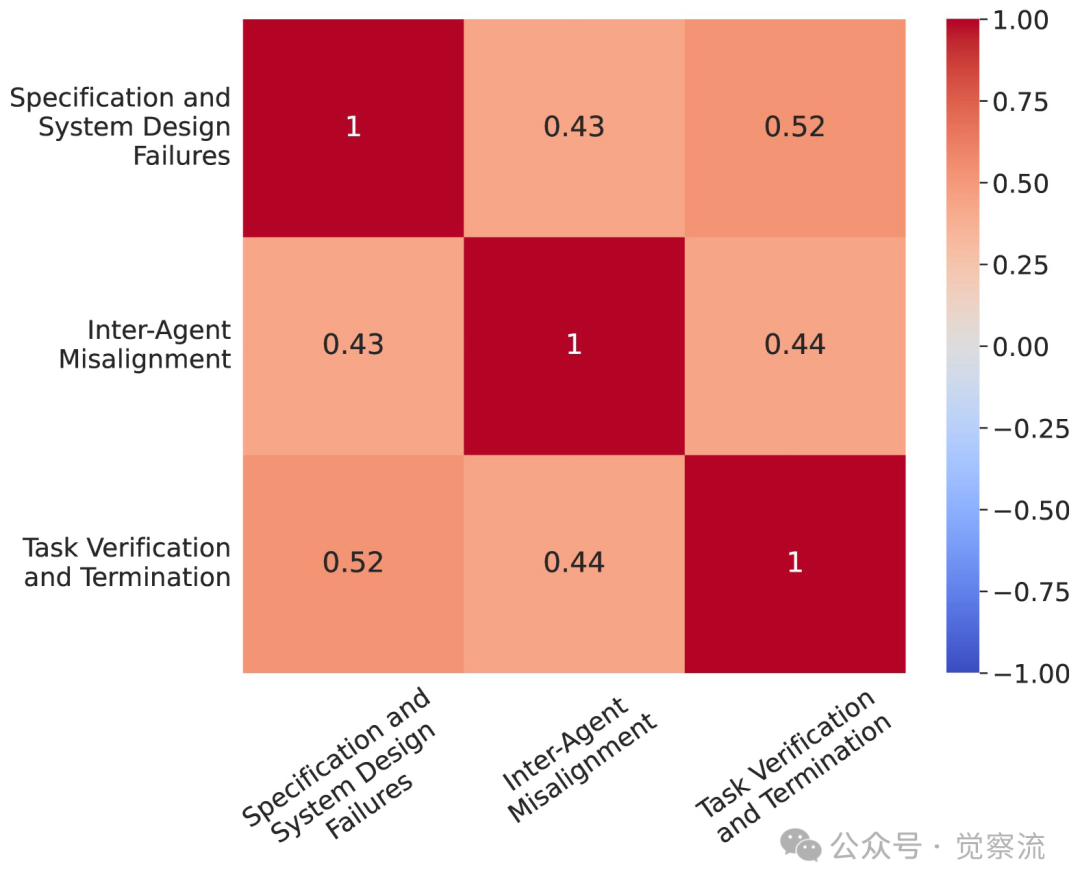
The failures of multi-agent LLM systems can be categorized into three main categories: Specification and System Design Failures, Agent Misalignment, and Task Validation and Termination Failures. These categories encompass various issues that may arise during the design, collaboration, and execution processes of the system.
1. Specification and System Design Failures
This category includes failures due to defects in system architecture design, poor dialogue management, unclear task specifications or constraint violations, and insufficient or ineffective definitions of agent roles and responsibilities. Specific manifestations include:
- • FM-1.1: Violation of Task Specifications: Agents fail to adhere to the constraints or requirements of the given task, leading to suboptimal or incorrect results. For example, in a chess game requiring moves to be represented in classical chess notation, the system instead uses coordinate notation, failing to meet the initial requirement.
- • FM-1.2: Violation of Role Specifications: Agents fail to adhere to the responsibilities and constraints of assigned roles, potentially leading to behavior similar to another role. For instance, during the requirements analysis phase of ChatDev, the CPO agent sometimes oversteps its authority to define the product vision and make final decisions.
- • FM-1.3: Step Repetition: Unnecessary repetition of previously completed steps during the process may lead to delays or errors in task completion.
- • FM-1.4: Loss of Dialogue History: Unexpected context truncation, ignoring recent interaction history and reverting to a previous dialogue state.
- • FM-1.5: Unawareness of Termination Conditions: Lack of awareness of the criteria that trigger the termination of agent interactions may lead to unnecessary continuations.
2. Agent Misalignment
This category involves issues such as poor communication between agents, ineffective collaboration, behavioral conflicts, and gradual deviation from the initial task. Specific issues include:
- • FM-2.1: Dialogue Reset: Unexpected or unjustified restarts of dialogue may lead to loss of context and progress in interactions.
- • FM-2.2: Failure to Clarify: In the face of unclear or incomplete data, the inability to request additional information may lead to erroneous actions.
- • FM-2.3: Task Deviation: Deviation from the established goals or focus of the given task may lead to irrelevant or unhelpful actions.
- • FM-2.4: Information Retention: Agents fail to share important data or insights they possess, which could influence the decisions of other agents if shared.
- • FM-2.5: Ignoring Inputs from Other Agents: Ignoring or failing to adequately consider inputs or suggestions provided by other agents in the system may lead to suboptimal decisions or missed collaboration opportunities.
- • FM-2.6: Reasoning-Action Mismatch: Discrepancies between the logical reasoning process of agents and the actions they actually take may lead to unexpected or undesired behaviors.
3. Task Validation and Termination Failures
This category involves premature termination of execution and a lack of sufficient mechanisms to ensure the accuracy, completeness, and reliability of interactions, decisions, and outcomes. Specific manifestations include:
- • FM-3.1: Premature Termination: Ending dialogue, interaction, or tasks before all necessary information exchanges or goals are achieved may lead to incomplete or incorrect results.
- • FM-3.2: Lack of or Incomplete Validation: Partial or complete omission of appropriate checks or confirmations of task results or system outputs may lead to errors or inconsistencies going unnoticed.
- • FM-3.3: Incorrect Validation: Failure to adequately validate key information or decisions during iterations may lead to errors or vulnerabilities in the system.
The classification in the figure below divides failure modes into three main stages: pre-execution, execution, and post-execution, each of which may produce specific failure modes. The figure also shows the frequency of occurrence for each failure mode and category, helping us better understand the distribution of these failure modes in actual systems.
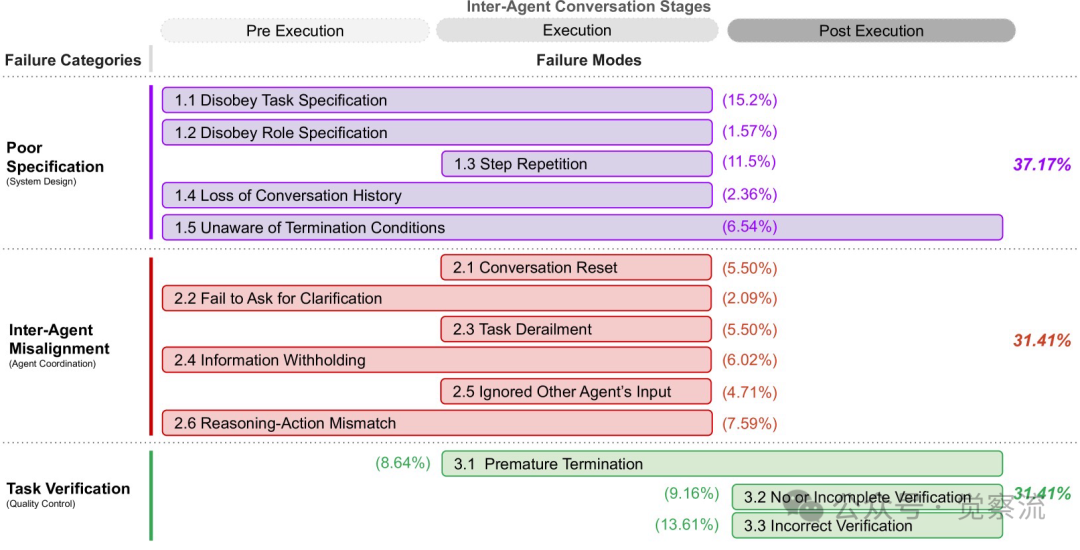
Case Studies
To gain a deeper understanding of the reasons behind the failures of multi-agent LLM systems, researchers conducted in-depth analyses of several representative systems and attempted to improve their performance through interventions. Below, we will explore two case studies: AG2 and ChatDev.
AG2 Case Analysis
AG2 is an open-source programming framework for building agents and managing their interactions. In the study, AG2 was used to solve mathematical problems, specifically tested on the GSM-Plus dataset. The original AG2 system performed poorly in task completion, with an accuracy rate of only 84.75%. Researchers implemented two main interventions to address this issue: improving prompts and redesigning the agent topology.
In terms of prompt improvement, researchers provided agents with clearer task descriptions and validation steps. The new prompts required agents to perform self-validation during the task-solving process and provide detailed validation processes in the final step. For example, when solving mathematical problems, the prompts required agents not only to provide answers but also to validate each step of the reasoning process and record the validation results in a designated validation section. This improvement made agents more focused on the accuracy of results during task execution, thereby reducing failures caused by reasoning errors.
In the redesign of the agent topology, researchers introduced three specialized roles: Problem Solver, Coder, and Verifier. The Problem Solver is responsible for solving mathematical problems using a chain-of-thought approach without relying on tools; the Coder is responsible for writing and executing Python code to arrive at the final answer; and the Verifier is responsible for reviewing the discussion process and critically evaluating the solution, with only the Verifier allowed to terminate the dialogue. This collaborative model not only improved the efficiency of task execution but also ensured the reliability of results by adding a verification step.
After these interventions, the performance of the AG2 system significantly improved. With the improved prompts, the accuracy rate increased to 89.75%; and after adopting the new topology, the accuracy rate further increased to 88.83%. These results indicate that optimizing prompts and the organizational structure of agents can improve the performance of multi-agent LLM systems to some extent.
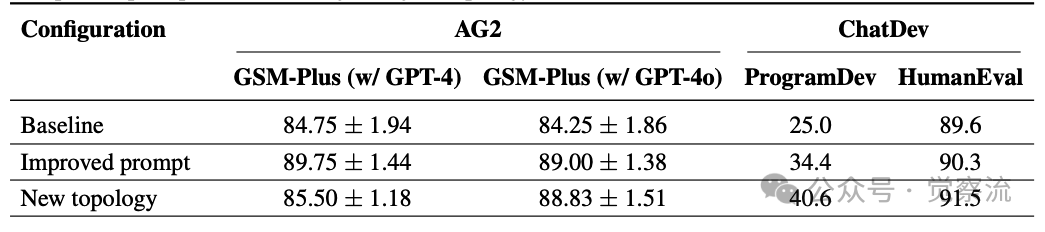
From the table above, it can be seen that after improving prompts and redesigning the agent topology, AG2’s performance has significantly improved.
ChatDev Case Analysis
ChatDev is a general framework that simulates a multi-agent software company, where different agents take on different roles in the software development process, such as CEO, CTO, programmers, and reviewers. In the study, the ChatDev system performed poorly in task completion, with an accuracy rate of only 25%. To improve its performance, researchers implemented two different interventions.
Researchers optimized role-specific prompts to reinforce the hierarchy and adherence to responsibilities of roles. For example, during the requirements analysis phase of ChatDev, the CPO agent sometimes overstepped its authority to define the product vision and make final decisions. To address this issue, the prompts were redesigned to clearly specify the responsibilities and decision-making authority of each role. Only superior agents could finalize the dialogue, thus avoiding failures caused by role overreach.
Researchers made fundamental changes to the framework’s topology. The original ChatDev system used a directed acyclic graph (DAG) structure, where tasks would go through multiple stages before completion. Researchers changed it to a cyclic graph structure, where tasks would only terminate after the CTO agent confirmed that all reviews had been properly addressed, and a maximum iteration count was set to prevent infinite loops. This improvement made the task execution process more flexible and enhanced system performance through iterative refinement and more comprehensive quality assurance.
After these interventions, the performance of the ChatDev system also improved. Although the specific improvement varied by task, these interventions showed positive effects across multiple benchmarks. For example, in the ProgramDev benchmark, the task completion rate increased from 25.0% to 40.6%; in the HumanEval benchmark, the accuracy rate increased from 89.6% to 91.5%. These results indicate that optimizing prompts and the organizational structure of agents can improve the performance of multi-agent LLM systems to some extent.
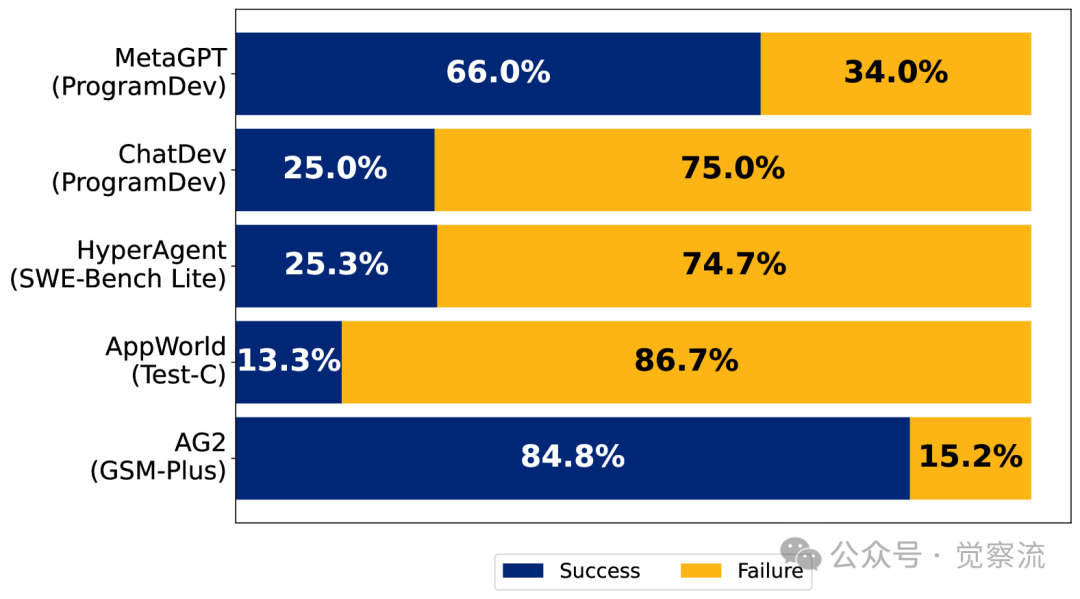
Researchers also conducted statistical analyses of the failure rates of different frameworks. From the figure below, it can be seen that different systems exhibit significant differences in performance across different failure categories, which helps us understand the unique challenges each system faces in design and implementation.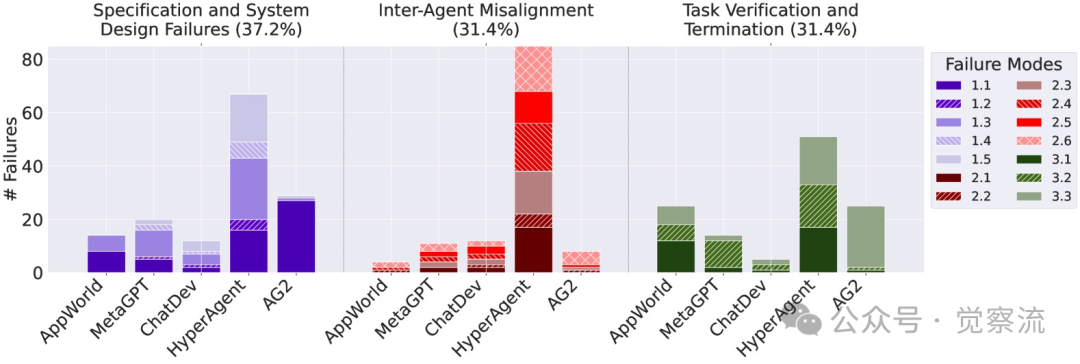
Discussion of Solutions
In response to the issues present in multi-agent LLM systems, researchers proposed a series of solutions, which can be divided into tactical and structural levels.
Tactical Level Solutions
Tactical solutions mainly focus on optimizing the role definitions of agents, prompt design, and interaction patterns. For example, by improving the prompts for agents, task requirements and agent responsibilities can be defined more clearly, thereby reducing failures caused by unclear task specifications. In the ChatDev system, researchers optimized the prompts to clearly specify the roles and tasks of each agent while adding validation steps that require agents to perform self-checks and mutual validation after task completion. This improvement not only increased the accuracy of tasks but also enhanced the system’s ability to detect errors.
Additionally, optimizing the interaction patterns of agents is also an important measure at the tactical level. For example, in the AG2 system, researchers introduced a new agent topology, dividing agents into different roles such as Problem Solvers, Coders, and Verifiers, each with clear responsibilities and interaction processes. This collaborative model not only improved the efficiency of task execution but also ensured the reliability of results by adding verification steps.
Structural Level Solutions
Structural solutions focus more on the design and optimization of the overall system architecture. For example, developing more robust validation mechanisms is an important means to improve system reliability. Researchers suggest introducing independent verification agents in multi-agent systems responsible for comprehensive checks and validations of task results. This validation mechanism should not only check the correctness of final results but also validate key steps and intermediate results during the task execution process, allowing for timely detection and correction of errors.
Improving communication protocols is another important structural-level solution. By establishing standardized communication protocols, information exchange between agents will be more efficient and accurate. For example, researchers proposed a multi-agent communication model based on graph attention mechanisms, which can dynamically adjust the communication weights between agents based on task requirements, thereby improving collaboration efficiency and task completion quality.
Quantifying uncertainty and enhancing memory management are also important components of structural-level solutions. By introducing probabilistic models to quantify the uncertainty between agents, the system can better handle uncertainties and risks in complex tasks. At the same time, enhancing agents’ memory management capabilities allows them to better track task context and historical information, helping to reduce failures caused by loss of dialogue history.
Conclusion
The failures of multi-agent LLM systems are not coincidental but stem from various complex issues in system design, agent collaboration, and task execution processes. By deeply studying these failure modes, we can provide valuable guidance for future system design and optimization. Future improvement directions can focus on developing more robust validation mechanisms, improving communication protocols, quantifying uncertainty, and enhancing memory and state management. These improvements will help build more reliable and efficient multi-agent LLM systems.
What are your thoughts after reading this article? If you have other ideas, feel free to leave a comment, and let’s discuss. Or join the “Awareness Flow” community group to learn and communicate with others. To join, send a private message with “Join Group” or “Add Group“.
Related Reading
◆ STEVE: Making AI Smarter in Controlling Graphical Interfaces
◆ 🔥AutoAgent: Making AI Agent Development Accessible
◆ 🔥The Choice of AI Intelligence: The Collision and Integration of API Agents and GUI Agents
◆ Exploring MovieAgent: Multi-Agent CoT Planning for Movie Generation
◆ 🔥Agentic Workflows: Making Workflows Smarter and More Flexible
◆ 🔥Comparative Analysis of Open Source Agent Communication Protocols: MCP, ANP, Agora, agents.json, LMOS, AITP (A Long Article)
◆ 🔥Practical MCP Server Sharing, Unlocking Infinite Possibilities for Agents with Claude AI
◆ 2025 Financial Industry AI Tools Overview: Ten Transformative Forces Coming
◆ OpenAI Releases New Tools: Making AI Agent Construction Easier
◆ TwinMarket: Simulating Market Behavior with AI Agents, Unveiling the Mysteries of Financial Markets
◆ 🔥The Future of AI Agents: Investment Trends in Silicon Valley, Insights from Manus, and Open Source Explorations like OWL
◆ 🔥From Manus to OpenManus: How AI Products Win the Future?
◆ 🔥If You Can’t Beat AI, Join It: Best Practices for Frontend Development with MGX Agent – Case Study
◆ 🔥MGX, Opening a New Era of AI Software Development, In-Depth Analysis of a Long Article
◆ A-MEM: Giving AI Agents Dynamic Memory Organization
◆ PlanGEN: Making AI Planning Smarter in Multi-Agent Frameworks
◆ MCTD: Unlocking the Super Engine of AI Planning
◆ Single-Agent Planning: The Optimal Decision Framework in Multi-Agent Systems
◆ CODESIM: New Ideas for Multi-Agent Code Generation and Problem Solving
◆ Breaking Tradition: A New Paradigm in Multi-Agent Architecture Exploration – Interpretation of the MaAS Framework
◆ AI Agent Infrastructure: Unlocking Potential and Managing Risks
◆ 🔥Unlocking the Construction Code of AI Agents: Analysis of Six Open Source Frameworks
◆ 🔥AFLOW: Optimizing AI with AI, Opening a New Chapter in Efficient Workflows
◆ 🔥2025: 13 Free AI Agent Course Resources
◆ Using the PydanticAI Framework to Quickly Build Multi-Agent Systems – AI Agent Collaboration Made Easy
◆ 🔥Eko: Driving Frontend Development with Natural Language, A New Experience in AI Agent Workflows!
◆ 🔥The Next Generation AI Agent’s “Tool Hand”: How MCP Enables AI to Operate Databases/Browsers/APIs Independently
◆ IntellAgent: An Evaluation Framework for Conversational AI
◆ The Self-Evolution Path of AI: Autonomous Iterative Optimization of Multi-Agent Systems
◆ 🔥From Theory to Reality: OpenAI’s Operator Demonstrates the Huge Potential of CCA (Computer Control Agents)
◆ AI Agent Practice: Achieving Persistence and Streaming with LangGraph
◆ 🔥Search-o1: Dynamic Retrieval + Document Refinement, Unlocking Knowledge Blind Spots for AI Reasoning
◆ 🔧DeepSeek Information Overload? – CHRONOS: AI Iteratively Self-Questioning, Accurately Constructing News Timelines
◆ 🔥Can AI Learn Self-Reflection? Agent-R Uses Monte Carlo Tree Search (MCTS) for Self-Training and Automatic Error Correction, Making AI Smarter
◆ Setting Boundaries for AI Agents: The Combination of Natural Language Permissions and Structured Permissions
◆ 🔥The Dilemma of AI Implementation: Function, Multi-Tool Agents, or Multi-Agent?
◆ Cline 3.3 New Version: The “Guardian” and “Efficiency Pioneer” of the Programming World
◆ Self-MoA: Simplifying the Traditional MoA with a Focus on a Single Model to Simplify LLM Integration
◆ 🔥New Breakthroughs in Multi-Agent System Optimization: The Mass Framework Leading New Ideas in Intelligent Collaboration
References
- • Why Do Multi-Agent LLM Systems Fail?https://arxiv.org/pdf/2503.13657
-
Note: This article was translated with AI assistance, and the content was organized/reviewed by humans before publication.
Welcome to click  and follow
and follow  to not miss out on exciting content.
to not miss out on exciting content.
I am Si Ling Qi🐝, an internet enthusiast who loves AI. Here, I share my observations and thoughts, hoping my explorations can inspire those who also love technology and life, bringing you inspiration and reflection.
I look forward to our unexpected encounters. Click below to follow
🙋♂️Join the group for communication1. Click on the community in the public account menu to scan the code to join the group.2. Reply with “Join Group” or “Add Group” to add the author’s WeChat to join the group.