Ensuring system scalability is one of the core goals of our architectural design work. There are many ways to achieve scalability, and the JDK itself has a built-in SPI (Service Provider Interface) mechanism to help developers dynamically load various implementation classes, as long as these implementation classes follow certain development specifications.
On the other hand, the JDK’s built-in SPI mechanism has certain shortcomings, which is why some frameworks on the market have enhanced the SPI mechanism in the JDK. A representative framework in this regard is Dubbo. In today’s lesson, we will compare these two SPI mechanisms and focus on explaining the implementation principles and advantages of the SPI mechanism in Dubbo. To better compare, let’s start with the SPI mechanism in the JDK.
Analysis of the SPI Mechanism in the JDK
If we use the SPI in the JDK, the specific development work will involve three steps.
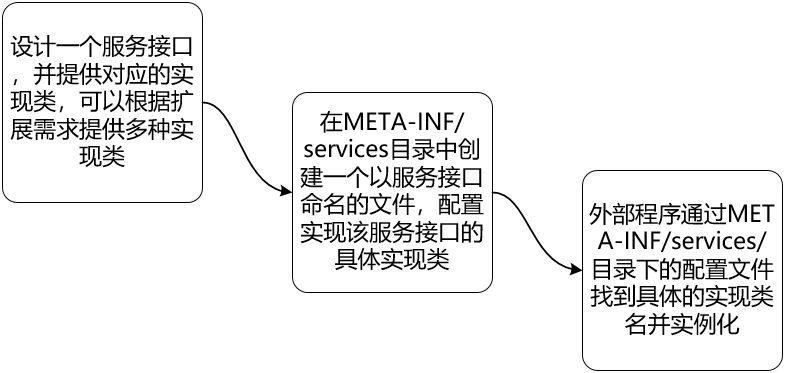
For developers of SPI, we need to design a service interface and then provide different implementation classes based on business scenarios, which is the first step.
The next second step is crucial; we need to create a configuration file named after the service interface and place this file in the META-INF/services directory of the code project. Please note that in this configuration file, we need to specify the full class name of the implementation class corresponding to the service interface. Through this step, we can obtain a jar package containing the SPI class and configuration.
Finally, the user of the SPI can load this jar package and find this configuration file within it, and instantiate these classes based on the full class name of the configured implementation class.
The last two steps in the figure above are actually configuration work to comply with the implementation mechanism of SPI in the JDK.
To achieve dynamic loading of SPI implementation classes, the JDK specifically provides a ServiceLoader utility class, which is used as follows:
public static void main(String[] args) {
ServiceLoader<LogProvider> loader = ServiceLoader.load(LogProvider.class);
for (LogProvider provider : loader) {
System.out.println(provider.getClass());
provider.info("testInfo");
}
}
Here we have a LogProvider interface, and by using the load method of ServiceLoader, we load the implementation classes configured for this interface into memory, making it easy to use the functionalities provided by these SPI implementation classes.
Next, let’s analyze the implementation principles of this ServiceLoader utility class.
ServiceLoader itself implements the Iterable interface in the JDK, so in the above code example, what we get through the ServiceLoader.load method is an iterator, and the underlying implementation uses the ServiceLoader.LazyIterator class.
From the name, LazyIterator is an iterator with a lazy loading mechanism, and it has two core methods: hasNextService and nextService. Let’s first look at the hasNextService method:
// Configuration file path
static final String PREFIX = "META-INF/services/";
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
// By using the PREFIX prefix with the service interface name, we can find the target SPI configuration file
String fullName = PREFIX + service.getName();
// Load the configuration file
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
// Traverse the SPI configuration file and parse the configuration content
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// Parse the configuration file
pending = parse(service, configs.nextElement());
}
// Update nextName field
nextName = pending.next();
return true;
}
As we can see, the core function of the hasNextService method is to find and parse the configuration file. The nextService method, which we will expand on, is responsible for instantiating the configured classes, with the core implementation as follows:
private S nextService() {
String cn = nextName;
nextName = null;
// Load the class specified by the nextName field
Class<?> c = Class.forName(cn, false, loader);
// Check type
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
// Create an object of the implementation class
S p = service.cast(c.newInstance());
// Cache the created object
providers.put(cn, p);
return p;
}
Here, the target instance is created through the newInstance method, and the created instance object is cached in the providers collection to improve access efficiency.
Analysis of the SPI Mechanism in Dubbo
To achieve the framework’s own scalability, Dubbo also adopts a design philosophy similar to the SPI in the JDK but provides a new implementation method and adds some extended functionalities.
The annotations related to the SPI mechanism in Dubbo mainly include @SPI, @Adaptive, and @Activate, among which the @SPI annotation provides functionality similar to that of the SPI in the JDK.
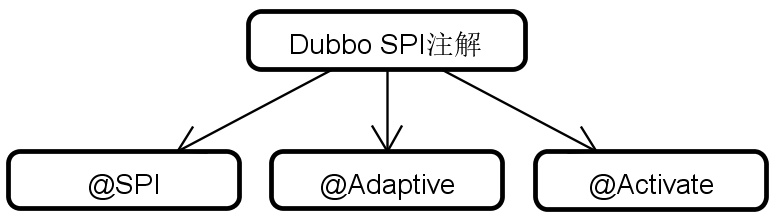
The application scenarios of these three annotations are different. The @SPI annotation provides the most basic SPI mechanism for Dubbo, while the @Adaptive and @Activate annotations are built on top of this annotation, so we will focus on the @SPI annotation. If this annotation is added to an interface, Dubbo will look for the implementation of the corresponding extension point during runtime.
In Dubbo, the application scenarios for the @SPI annotation can be seen everywhere. For example, the Protocol interface is defined as follows:
@SPI("dubbo")
public interface Protocol
As we can see, the @SPI(“dubbo”) annotation is used on this interface.
Please note that in the @SPI annotation, a default extension point name can be specified, such as “dubbo” here, which indicates that among all implementations of the Protocol interface, DubboProtocol is its default implementation.
With the definition of SPI, let’s take a look at how SPI configuration information is stored in Dubbo. We already know that the JDK only stores SPI configurations in the META-INF/services/ directory, while Dubbo provides three similar directories:
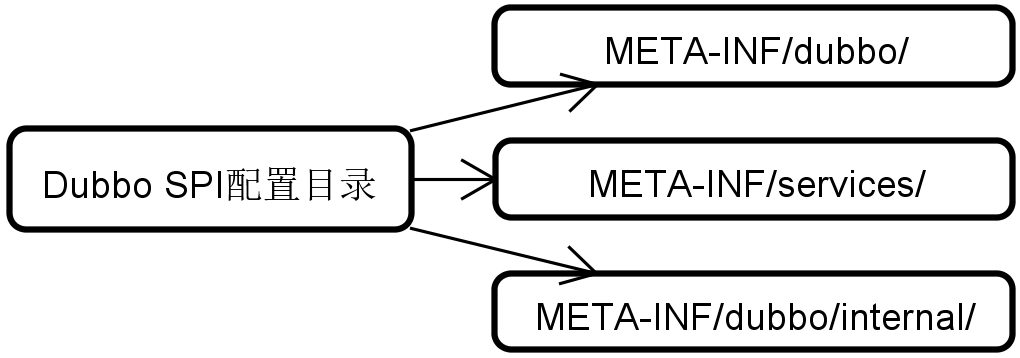
As an example, we will continue to discuss the Protocol interface mentioned above.
For the Protocol interface, Dubbo provides multiple implementation classes such as gRPCProtocol and DubboProtocol, and completes the loading process for a specific implementation scheme through the SPI mechanism. Let’s look at the code projects that provide these implementation classes, dubbo-rpc-grpc and dubbo-rpc-dubbo, and we will find that in the META-INF/dubbo/internal/ directory, there is a com.apache.dubbo.rpc.Protocol configuration file in both. The code structure of the dubbo-rpc-grpc project is shown in the figure below:
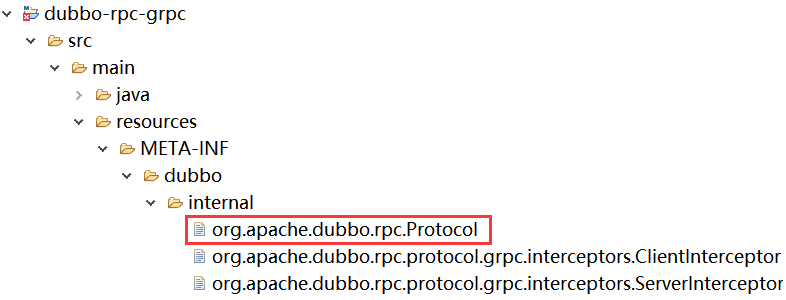
Similarly, the code structure of the dubbo-rpc-dubbo project is shown in the figure below:
If we open the com.apache.dubbo.rpc.Protocol configuration files in these two projects, we can find that they point to the classes org.apache.dubbo.rpc.protocol.grpc.GrpcProtocol and org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol, respectively.
// dubbo-rpc-grpc project
grpc=org.apache.dubbo.rpc.protocol.grpc.GrpcProtocol
// dubbo-rpc-dubbo project:
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol
When Dubbo references a specific code project, it can find the implementation of the extension point corresponding to the Dubbo interface through the configuration items in this project.
At the same time, from the above configuration items, we can also see that the definition method used in Dubbo is different from that in the JDK. Dubbo uses a key value (such as gRPC and Dubbo above) to specify the name of the configuration item, rather than using the full class path.
After introducing the @SPI annotation, let’s take a look at the ExtensionLoader class in Dubbo, which plays the same role as the ServiceLoader utility class in the JDK. ExtensionLoader is the core class for loading extension points. If we want to obtain the DubboProtocol implementation class, we can do so as follows:
DubboProtocol dubboProtocol = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(DubboProtocol.NAME);
Let’s take a look at the details of the getExtension method, which is as follows:
public T getExtension(String name) {
...
// Get the target object from the cache
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
// Put the target object into the cache
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// Create the target object
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
Here, a caching mechanism is also used. This method first checks whether the extension point instance already exists in the cache; if not, it creates it through the createExtension method. Following the createExtension method, we finally see the familiar SPI mechanism, as follows:
private Map<String, Class<?>> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
// Determine the cache name
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// Load class instances from three directories
loadFile(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadFile(extensionClasses, DUBBO_DIRECTORY);
loadFile(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
Here, we call the loadFile method three times to load extension points from the META-INF/dubbo/, META-INF/services/, and META-INF/dubbo/internal/ directories. In the loadFile method, Dubbo directly loads these SPI extension classes using Class.forName and caches them.
At this point, we find that to improve the loading speed of instance classes, both Dubbo and the JDK use a caching mechanism, which is a common point for them. However, we can also outline the differences between the SPI mechanism in Dubbo and that in the JDK, with two core points being configuration file location and conditions for obtaining implementation classes.
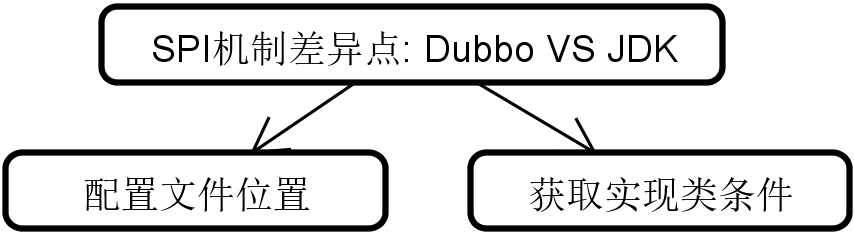
- From the perspective of the configuration file location for loading SPI instances, Dubbo supports more loading paths. The JDK can only load a fixed META-INF/services, while Dubbo has three paths.
- Regarding the conditions for obtaining implementation classes, Dubbo uses a key value corresponding to the name to locate specific implementation classes, while ServiceLoader internally uses an iterator, and when obtaining the implementation classes of the target interface, it can only load and instantiate all classes in the configuration file through traversal, which is obviously less efficient.
In simple terms, Dubbo did not directly adopt the JDK SPI mechanism but instead implemented its own set primarily to overcome this inefficiency and provide more flexibility.
Conclusion
From the definition of Dubbo configuration items, we find that Dubbo adopts a different implementation mechanism from the JDK. Although Dubbo also uses the SPI mechanism and dynamically loads implementation classes from jar packages, its implementation method is different from that based on ServiceLoader in the JDK. Thus, we have analyzed the differences in the design and implementation of the SPI mechanism between the JDK and Dubbo in detail and clarified the internal implementation principles and advantages of Dubbo.