In recent years, with the popularization of new technologies such as distributed system architecture, microservices concepts, and PaaS service components in the financial industry, traditional monolithic business system architectures based on mainframes and storage are rapidly evolving towards distributed system architectures based on cloud foundations (referred to as new system architecture). The new system architecture supports retail banking with tens of millions of monthly active users and high-concurrency, high-traffic business scenarios such as 24/7 online payments, while also introducing a series of new problems and challenges regarding production operation stability.

Ping An Bank Financial Technology Department
Technical Director of Cloud Data Operations Center: Chen Wenchun
New Challenges to Production Operation Stability from Cloud-Based Distributed Microservices Architecture
Challenge One: Distributed systems and microservices are important characteristics of the new system architecture. Compared to traditional mainframe systems, which can generally complete business functions and scenarios within a monolithic system, the new system architecture adopts a distributed microservices application pool design concept. The application pool only completes relatively singular atomic functions, and multiple application pools need to call each other to support business scenarios, forming a call chain. In some complex business scenarios, the call chain can exceed ten steps and involve external partner systems outside the data center. This design poses a significant challenge to system operation stability, as failures in application pools or external partner institutions can spread to multiple application pools upstream and downstream of the business scenario call chain. Additionally, due to the functional sharing principle of microservices design, the impact of failures can further extend to other business scenarios, creating what is known as an “explosion radius.”
Challenge Two: Another important characteristic of the new system architecture is its reliance on PaaS basic services provided by the cloud foundation, such as service registration centers, soft load balancing, external call proxies, entry gateways, messaging systems, caching services, and database services. While PaaS basic services provide common capabilities, they also introduce new failure factors. Furthermore, the public nature of PaaS basic services makes them susceptible to the failures of calling parties, turning them into nodes and amplifiers for the spread of failure impacts.
Challenge Three: During the transformation of the new system architecture, the production system operation and maintenance (O&M) team’s knowledge domain has expanded from relatively centralized mainframe systems to more technical areas. Ensuring production operation quality requires not only focusing on the business system itself but also synchronously monitoring the underlying PaaS services that support the business system, and even IaaS services. The transformation of the team and the enhancement of emergency response capabilities are crucial for the successful introduction of the new system architecture.
Chaos engineering can be traced back to the Chaos Monkey system created by the Netflix technology team, which actively injects faults into the production environment to verify the fault tolerance of production systems, thereby enhancing system operation stability. In simple terms, chaos engineering is similar to a “vaccine”: it strengthens the body’s ability to resist diseases by continuously injecting small amounts of harmful viruses. Compared to traditional IT system robustness testing theories, chaos engineering can be seen as an evolution, development, and enhancement of robustness testing theories under the new system architecture.
Initial Practice of Chaos Engineering in Ping An Bank’s New Core Credit Card Project
Several years ago, Ping An Bank launched a core system reconstruction project for credit cards, completely transforming the mainframe architecture system into a distributed architecture system based on self-developed financial-grade PaaS foundations (hereinafter referred to as the new core system). The new core system introduced a series of PaaS basic services, including microservices application pools, registration centers, user sharding request routing, message queues, task scheduling, and distributed databases. The operational stability and O&M assurance capabilities after the system went live were one of the project’s biggest risk points. Therefore, the O&M team proactively introduced chaos engineering concepts during the project planning phase, building a chaos drill platform based on the open-source Chaos Blade component, and executed five rounds of drill verification during the parallel verification phase before the system officially went live. The parallel verification phase before going live used the production data center managed by O&M, deploying the system according to the architecture of the official launch, and using observable systems in the production environment to verify the new system through recording and replaying production traffic.
In the project, chaos engineering was mainly divided into two phases. The first two rounds were the first phase, focusing on the robustness and fault tolerance of the new core system and PaaS components. The key processes are as follows.
Case Design: Analyze the architecture of the new core system and PaaS service components, combined with the production data center situation and historical fault database, to design fault injection points and fault injection cases. Fault cases are divided into multiple levels, including hardware failures, network jitter, file read/write, DNS service anomalies at the IaaS layer, as well as short-term quality fluctuations of upper-layer PaaS services, automatic failover, database connection pool congestion, and slow database service scenarios.
Case Execution, i.e., Fault Injection: Continuously inject faults into the system multiple times through automated tools or manual triggers to simulate the uncertainties and complexities of the real world. Some fault scenarios use combinations of various IaaS layer and PaaS layer fault points for injection.
Observable System Construction: Establish a complete monitoring and alerting system to collect and analyze system operation data in real-time, allowing for real-time observation of the operational status of the new core system and PaaS components after fault injection.
Drill Result Evaluation: Analyze the actual drill results and the gaps from the expected disaster recovery design using data from the observable system, focusing on observing the fault tolerance recovery capability and explosion radius after fault injection. Furthermore, after completing a batch of fault injections, analyze the system’s weak points, supplement the fault case database, and conduct the next test. Execute multiple tests to gauge the current system design’s fault tolerance capability boundaries and key weak points.
Feedback and Optimization: Based on the drill results, provide feedback and optimization improvement suggestions for the system architecture design, including fixing system disaster recovery defects and optimizing architecture design. For example, improve the data loading method of the user-sharded service request routing component to enhance service recovery efficiency after service node failures. Additionally, during the drill process, optimize the alert logic and fault levels of the monitoring system, and establish corresponding emergency plans for key weak points in the system.
After two rounds of drills, evaluations, feedback, and optimizations, the robustness and fault tolerance of the new core system and PaaS service components have significantly improved, with the vast majority of fault cases being automatically tolerated by the system, resulting only in short-term service quality fluctuations. Meanwhile, the observable system has matured, and emergency plans have been established for fault scenarios requiring manual intervention. Thus, chaos engineering entered the second phase, shifting the focus from the system to the human aspect, namely the emergency response capabilities of the O&M team.
In the second phase, the chaos engineering project team introduced a red-blue confrontation model, randomly dividing O&M engineers into two groups: the blue team and the red team. The blue team is responsible for experimental design and randomly selects the frequency, location, and combinations of fault injections; the red team, without prior notice, is responsible for alert responses, fault localization, and service recovery. During the drills, O&M engineers alternately assume blue or red team roles, assessing each other and simulating the production emergency process, entering a state of production emergency. After three rounds of drills in the second phase, the emergency response capabilities of the O&M team have significantly improved.
Reflections on the Initial Practice of Chaos Engineering
In the new core credit card project, there were differing opinions on the value of chaos engineering, especially regarding whether it was necessary to conduct chaos engineering during the parallel verification phase before going live, given that the robustness testing of the new core system and PaaS components had already been completed. Ultimately, the series of problem reports, optimization suggestions, observable capabilities, emergency plans, and the construction of emergency response capabilities by the O&M team produced by chaos engineering proved its value. Chaos engineering also won the championship in Ping An Bank’s annual technology innovation competition. The main reasons for its success are as follows.
First, the complexity of distributed system architecture based on cloud-native PaaS services has significantly increased, making it difficult to achieve production-like deployment standards in testing environments, necessitating simplified deployments. However, it is precisely this simplified deployment that leads to significant differences in the new core system’s abnormal response performance between testing and production environments. The observable system in the testing environment is also relatively rudimentary, making it difficult to effectively observe even when the system behaves abnormally.
Second, testing environments typically lack continuous and real production traffic. Under low testing loads, the system’s abnormal tolerance performance is significantly better than under real production loads. For example, in the case of computing node failure recovery, if startup protection is not properly implemented, application processes may continuously fail to start under the sustained impact of production traffic, unable to recover from faults on their own. However, this weakness is difficult to detect in a testing environment.
Third, the testing team’s understanding of fault scenarios in the production data center is usually weaker than that of the O&M team, leading to deviations in test case design and actual execution, making it difficult to simulate real production faults.
Fourth, chaos engineering not only focuses on the robustness and fault tolerance of systems but also emphasizes the observable system, emergency processes, and the rapid response capabilities of emergency teams.
In fact, after achieving success with chaos engineering on the new core credit card system, the fault injection platform has also been empowered to the testing environment, enriching the robustness testing cases and revising and improving the robustness testing specifications for important information systems, requiring periodic robustness testing and having the O&M team review the test reports, achieving some results and progress. However, overall, the output effects still do not meet the expectations for stable production operations.
Chaos Engineering in the Cloud-Native Transformation Phase
Currently, Ping An Bank is advancing a major information technology strategy for cloud-native transformation, and the construction of cloud foundation capabilities has also brought new opportunities for chaos engineering practices. Important information systems undergoing cloud-native transformation have also posed new requirements for chaos engineering. As an important sub-project within the cloud-native project, Ping An Bank’s O&M team has developed a three-step chaos engineering promotion plan (as shown in Figure 1).

Figure 1: Ping An Bank’s “Three-Step” Chaos Engineering Promotion Plan
As previously discussed, the core value of chaos engineering largely depends on a verification environment that closely resembles production standards and operational states. Therefore, how to construct this environment is the key to the entire planning. Considering resource investment and cloud foundation capabilities, Ping An Bank has adopted a simulation environment to support verification capabilities. The simulation environment is deployed in the production data center, managed and built by the O&M team, with technical standards referencing the production environment, isolation measures to prevent data contamination, and comparable observable capabilities to production. The cloud foundation capabilities empower the rapid construction of application systems in the simulation environment and the replication and playback of production traffic. The construction of the simulation environment provides solid support for the promotion of chaos engineering. In the internet industry, leading companies have also conducted chaos engineering in production environments. However, considering the high standards and strict requirements for production system stability and data security in the financial industry, the O&M team at Ping An Bank has adopted a relatively cautious simulation environment strategy, conducting pilot tests only under small-scale controlled conditions in the production environment.
The second key point of chaos engineering planning is the construction of application profiling capabilities for production systems. By using real data from the production environment, such as CMDB and dynamic topologies of application access, to construct the correlation and dependencies of a business system on IaaS layers, PaaS layers, related systems, and external partners, application profiles are formed, which can then be matched with the chaos engineering case library to automatically build chaos engineering verification plans for the relevant systems or business scenarios (as shown in Figure 2).
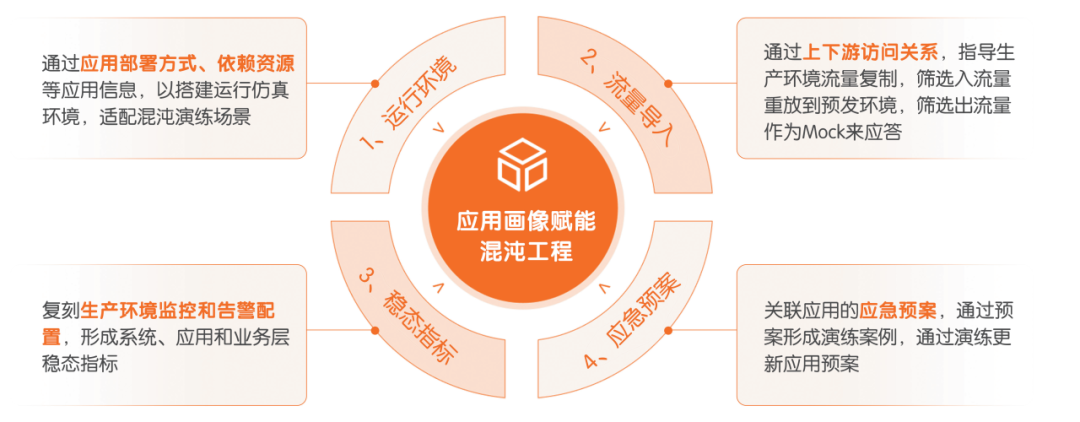
Figure 2: Application Profiling Empowering Chaos Engineering
In the future, Ping An Bank will rely on the cloud foundation technology capabilities provided by cloud-native transformation to continuously promote chaos engineering from the aspects of organizational form and institutional construction, ensuring that there are norms, organizations, and regular operations, continuously accumulating fault databases and conducting red-blue confrontation drills. This will enhance production operation quality from both the system fault tolerance capability and the team emergency capability, ensuring the steady and long-term implementation of the cloud-native transformation strategy.
(This article was published in the March 2024 issue of “Financial Electronics”)









New Media Center
Director / Kuang Yuan
Editors / Yao Liangyu Fu Tiantian Zhang Jun Tai Siqi
