IT system construction has evolved through standalone, centralized, and distributed architectures, and the complexity of system operation and maintenance drills and fault simulation testing has continuously increased. In complex distributed systems, both infrastructure and application platforms can experience unpredictable failures. Without knowing the root cause of a failure, we cannot prevent its occurrence. A more appropriate approach is to focus on simulating and rehearsing scenarios that trigger these risks before they happen, identifying and understanding the patterns and impacts of these failures, and then reinforcing and preventing them in a targeted manner to avoid serious consequences. Chaos engineering testing, based on chaos engineering technology, systematically simulates potential failures (or combinations of failures) that may occur in real scenarios, enabling the detection, verification, and analysis of the robustness and boundaries of the tested distributed application environment. Especially against the backdrop of the current trend of full-stack and domain technology autonomy and controllability, selecting combinations of complex failure scenarios has become an urgent issue that needs to be addressed.

China Electronics Corporation Gold Trust Research Institute Architecture Engineering Laboratory
Director Li Haibin
Exploration of Chaos Engineering Drill Scenarios
To systematically simulate potential failures that may occur in real scenarios and address the pain points of selecting complex failure combinations in the context of full-stack and domain technology innovation, the chaos engineering platform product can explore the following targeted areas in terms of technical capabilities, practical methodologies, and fault design.
1. In terms of technical capabilities. The chaos engineering platform should possess fault simulation capabilities across IaaS, PaaS, and SaaS system levels and further complete the integration and construction of the service support layer. For example, by introducing modules for full-process pressure testing management, visual monitoring capabilities, and automated chaos testing, the product’s functionality can be enriched. It should support architecture selection, full-link pressure testing, chaos engineering testing, and operational red-blue confrontation drills as four key business scenarios. Additionally, it should implement automated chaos engineering technologies to provide industry clients with a more complete intelligent platform.
2. In terms of chaos engineering practical methodologies. Mature procedural systems should guide the implementation process of chaos engineering, covering the division of labor and responsibilities among multiple professional departments such as testing, development, architecture, requirements, and operations. Throughout the implementation of chaos engineering testing, China Electronics Corporation Gold Trust has summarized a seven-step method for chaos implementation, including goal determination, steady-state indicator formulation, fault design, process orchestration, experiment execution, result analysis, and repair verification. This seven-step method runs through the entire process, ensuring high efficiency and order during implementation. The most critical step in the seven-step method is the “fault design” phase, which determines which fault cases we will test, the order of priority, and the steps of the testing method.
3. In terms of fault design. A complete framework is needed to guide scenario excavation and fault design. Based on years of practical experience, China Electronics Corporation Gold Trust has developed a fault design guide, introducing the FMEA concept to guide the evaluation of risk priorities for specific systems and scenarios. By combining chaos engineering standard use cases and evaluation systems from the financial sector, the implementation of chaos engineering can start without beginning from scratch, significantly lowering the implementation threshold and allowing for the customized design of fault scenarios for specific systems while discovering more system risk hazards with fewer fault scenarios.
Typical Case
Taking the new mobile banking project of a bank in South China as an example, we specifically analyze how to implement chaos engineering experiments targeting the distributed core business system of the bank—how to set goals, design faults, execute effectively, monitor indicators, and evaluate effects.
1. Project Overview.The personal mobile banking system of a bank in South China was planned and constructed in 2012, based on a “traditional monolithic architecture.” The mobile banking system supports basic functions such as account management, loans, investment, and customer service capabilities. Facing the growth of customer volume, rapidly changing diversified customer demands, and security issues related to innovation, the bank decided to launch the construction of a new generation mobile banking system in 2023. The new system is based on a full-stack innovative financial transaction cloud foundation and is deployed in a K8s container cloud environment. The mobile banking system is an important customer-facing system, which requires higher stability. Therefore, before going live, chaos engineering is used to ensure and enhance the stability capabilities of the mobile banking system by validating and improving the system’s resilience through high availability testing during the testing phase, verifying the rationality of container orchestration, and ensuring a smooth launch of the new mobile banking system.
2. Implementation Plan.The system testing mainly adopts a two-step approach.
(1) Platform Construction, where the main task is to establish a systematic process for chaos testing to accumulate experience for system launch. A chaos engineering testing system is built to simulate various faults and write fault testing cases for scenario adaptation. The chaos engineering platform constructed in this project covers fault injection across infrastructure, platform, and application layers while achieving visual display of the testing process and results. The platform deployment architecture is shown in the figure.
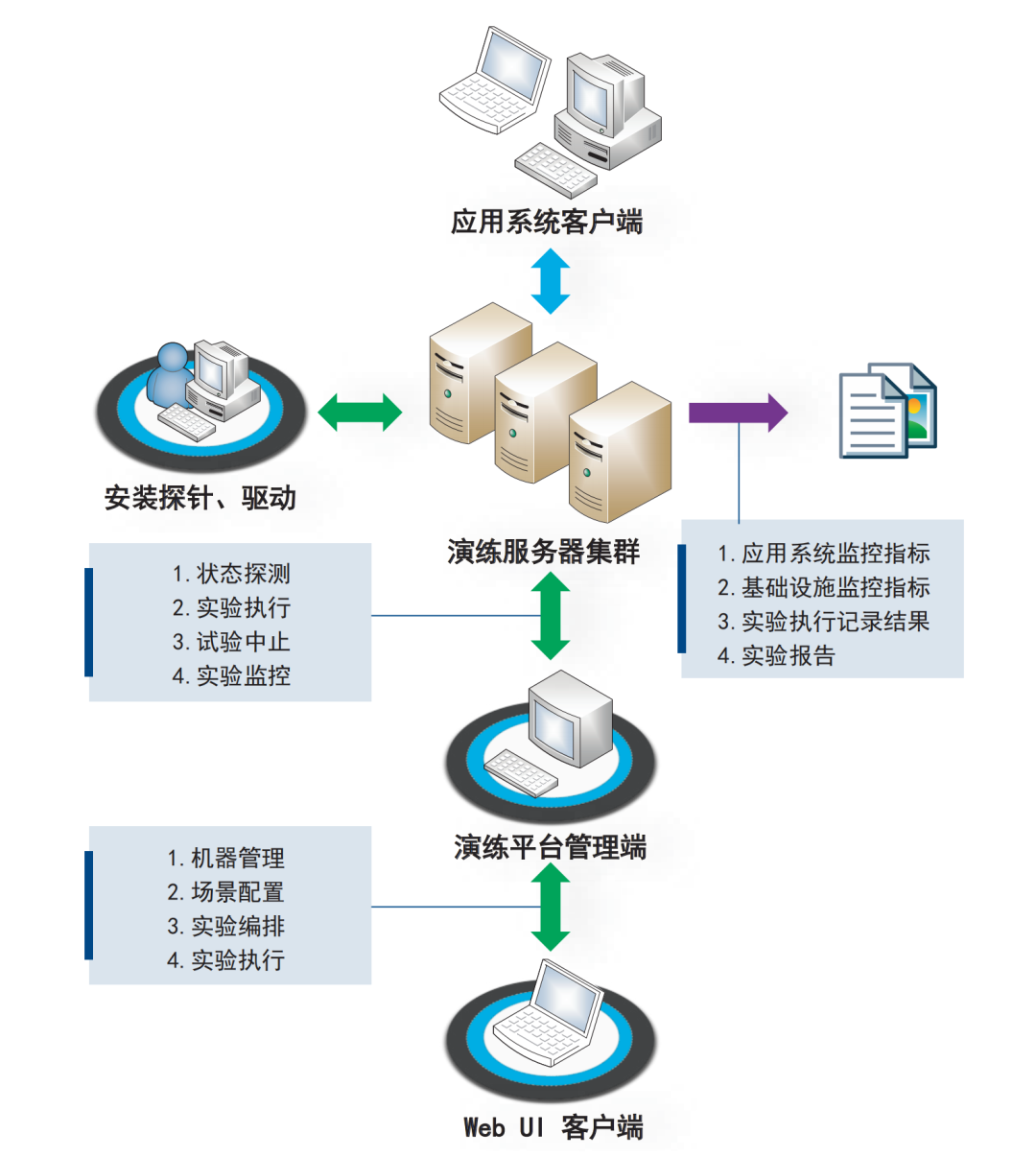
Figure Platform Deployment Architecture
The platform mainly consists of a basic management module and functional modules. The basic management module includes environment management, system management, event management, etc., covering machine management, application management, deployment unit management, K8s cluster management, user management, permission management, role management, menu management, system resource experimental events, and application experimental event management sub-modules. The functional modules include testing management, drill management, etc. The testing management module supports the management and orchestration of testing plans, supports pressure testing scripts, regular experimental scenarios, experimental task execution queues, pressure machine resources, monitoring and tracking, viewing experimental report information, statistical analysis of testing scenario information, concurrent experimental monitoring, observability and full-process pressure testing management, automated fault design, and experimental case generation, as well as automated experimental report generation.
(2) Fault Simulation, where the main task is to simulate various faults to expose hidden dangers and defects. Simulated hardware failures/software failures/network failures/human errors/exceptions/attacks, etc., observe how the system handles situations when CPU/memory/network failures occur.
During the actual project advancement, through demand research, 16 high-frequency trading scenarios were selected for pressure injection, simulating trading data using the pressure initiation capability of the chaos engineering platform. Business indicators such as system response time, TPS, success rate, and system metrics such as CPU, memory, network, and IO were collected and graphically displayed through the platform’s integrated monitoring system, ultimately forming a phased testing report that presents the system profile.
In total, over 150 cases were designed and written, covering fault scenarios such as service start/stop, system crashes, network card outages, application shutdowns, service termination, process hangs, JVM exceptions, Druid database connection pool saturation, and cluster switching after simulating data center failures.
All of the above cases were executed by the chaos engineering platform, effectively validating multiple system high availability capabilities in a container environment.
3. Application Effectiveness.In a self-controllable software and hardware operating environment, the chaos engineering platform successfully completed comprehensive availability testing for the new mobile banking system deployed on the K8s container cloud platform, enhancing system stability and improving system quality, which has practical benefits and significant importance. This testing validated the high availability of clusters, the effectiveness of load balancing, fault transfer efficiency, effective service registration & discovery, service self-recovery, timeout effectiveness, strong and weak dependency effectiveness, database cluster effectiveness, and high availability of batch services.
Additionally, during the execution of chaos testing, a series of issues related to K8s containers were discovered, covering PaaS components and SaaS applications. Based on the identified issues, project launch regulations that meet high availability requirements were formulated, providing guidance on the management components of K8s containers, business application health check methods, and configuration parameters.
As of now, over 150 experimental scenarios have been executed, with a total of over 500 experiments conducted, 12 detailed analysis reports on chaos testing results compiled, totaling over 1000 pages, and one summary report on chaos testing compiled, identifying 58 system issues and providing corresponding optimization suggestions or solutions.
4. Innovative Experiences.Based on specific capabilities of high availability testing (such as load balancing effectiveness, strong and weak dependency effectiveness), the original atomic chaos engineering fault scenarios were effectively combined according to testing scenario requirements. The chaos engineering platform was used to complete testing work on multiple dimensions of high availability capability items.
Achieved full-process management of testing defect management, supporting tracking, status modification of testing defects, and management and summarization of testing defects.
Automation capabilities were introduced into the testing work, embedding the system architecture into the platform library, and based on the high availability expert library template functionality, achieving automated fault design and experimental case generation, and automatically generating experimental reports after the experimental execution is completed. The report dimensions include: testing cases, testing experiments, business indicator observations, system resource metric observations, experimental result analyses, and key data basis for testing defects. This effectively reduces repetitive manual work and significantly improves the implementation efficiency of chaos engineering.
(This article was published in the March 2024 issue of “Financial Electrification”)

New Media Center
Director / Kuang Yuan
Editors / Yao Liangyu Fu Tiantian Zhang Jun Tai Siqi
