We welcome fintech professionals to actively submit articles!
Submission Email: [email protected]
—— Financial Digitalization

Written by / Software Development Center of Zhongyuan Bank Li Zhou
Background and Objectives
Currently, the digital economy is developing rapidly, and customers’ demand for online and scenario-based financial services is continuously increasing. Financial institutions in the banking industry are accelerating their digital transformation. With the continuous innovation of digital business and the rapid development of technologies such as cloud-native and distributed systems, the transformation of banking system architecture from traditional centralized architecture to cloud-native distributed architecture has become a common consensus. The transformation of the technical architecture has led to a geometric increase in architectural complexity, with failures occurring from the basic service layer to the application system layer, posing new challenges for ensuring system operational stability.
Zhongyuan Bank fully launched its digital transformation strategy in 2018, planning and designing an IT architecture system of “strong backend, large middle platform, and agile frontend,” vigorously promoting the transformation of application systems to a distributed microservices architecture. As of September 2022, Zhongyuan Bank has completed the microservices architecture transformation for dozens of systems, reaching over a thousand microservice instance nodes, with system transaction volume and complexity continuously rising. The dependencies of middleware components are becoming increasingly complex, necessitating the establishment of a secure and effective stability assurance system covering the entire software engineering lifecycle, including development, testing, and operations. By building stability assurance mechanisms at various stages and links of software engineering, the goal is to continuously improve system stability and reliability.
Construction Ideas
After thorough research on industry practices for stability construction, chaos engineering has gradually become the mainstream solution for stability assurance, with related construction methods, technical engineering, and application practices rapidly developing. Chaos engineering itself is a discipline and a technical means to enhance the resilience of technical architecture; by actively injecting faults, it tests the system’s behavior under various faults, identifies and fixes fault issues, avoids production operation problems, and establishes the system’s ability and confidence to withstand production operation risks.
Based on fully learning from the chaos engineering construction experiences in the industry, Zhongyuan Bank formed a chaos engineering team in 2021, relying on the chaos engineering platform, with chaos experiments as the core, to promote the application of chaos engineering throughout the bank through a development path of “technology selection, application pilot, scenario expansion, and continuous improvement.” During the practice, the team continuously explores application scenarios, improves platform functions, accumulates chaos experiment assets, cultivates a corporate chaos culture, and gradually builds a stability assurance system centered on chaos engineering.
Technology Selection
“To do a good job, one must first sharpen their tools.” The chaos engineering team at Zhongyuan Bank conducted thorough research and trials of mainstream open-source fault injection tools in the industry, such as ChaosBlade, ChaosMesh, and ChaosMonkey. Considering the actual construction needs of the bank, they made a comprehensive decision to choose ChaosBlade as the fault injection tool for chaos engineering experiments. The comparison of related tools is shown in Figure 1.
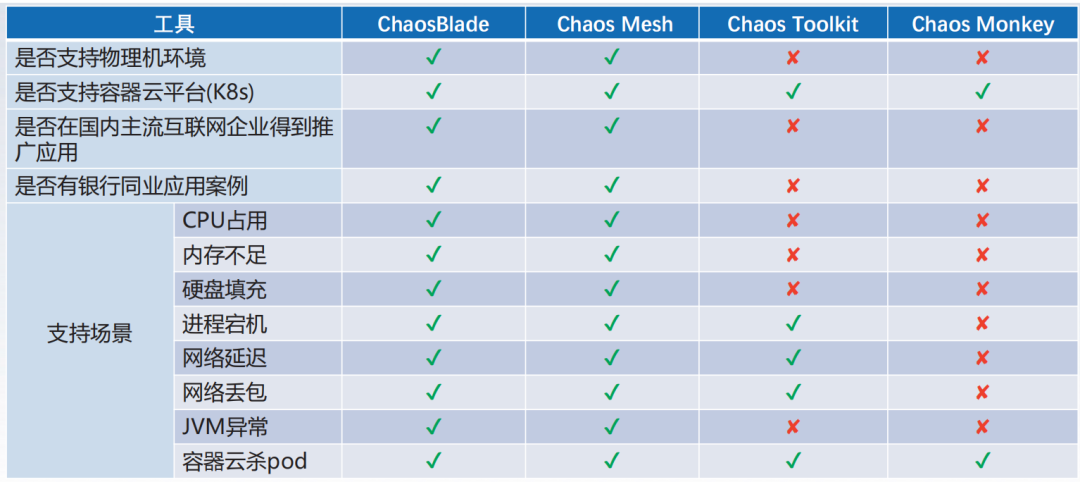
Figure 1 Comparison of Open-source Chaos Tools
Application Pilot
In the early stages of chaos engineering application practice, Zhongyuan Bank prioritized application project teams as execution units, using PaaS layer basic platform services as pilots to explore and accumulate six categories of fault scenarios and practical experiences (see Figure 2), forming a chaos experiment fault scenario library, thereby laying a technical foundation for subsequent chaos experiments in various business systems.
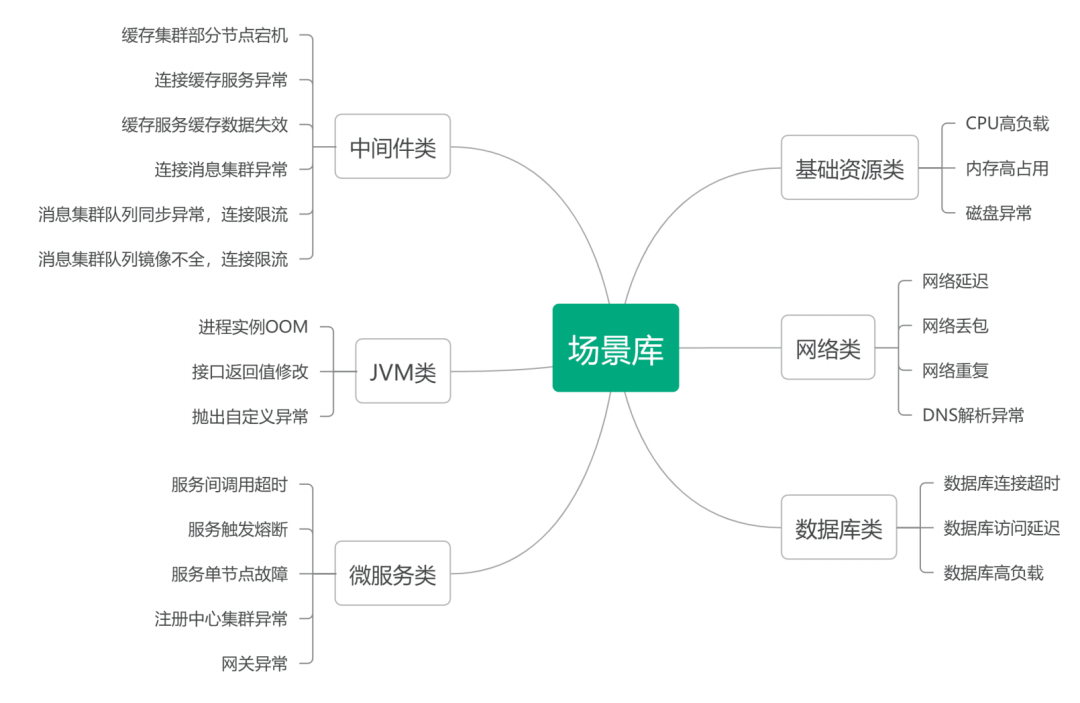
Figure 2 Chaos Experiment Fault Scenarios for Basic Components of Zhongyuan Bank
1. Pilot Scope
The PaaS layer basic platform services mainly include microservice platforms, Service Mesh platforms, middleware platforms, and other basic services. These services serve as the technical foundation for various business systems, and when failures occur, the impact range is significant. In conventional fault anomaly testing, only basic abnormal scenarios such as process interruption and container crashes can be simulated, which cannot meet the stability testing needs of distributed complex systems, such as CPU high load, memory high load, network failures, Java process OOM, and other fault scenarios. By utilizing the fault injection capabilities provided by the chaos engineering platform, the fault testing range can be expanded, fault testing scenarios improved, fault impact ranges clarified, system architecture risk hidden dangers discovered, and the basic service architecture and monitoring system further improved, thereby effectively enhancing the stability and reliability of infrastructure services.
2. Implementation Steps
The typical steps of chaos engineering experiments mainly include system selection, steady state establishment, scenario determination, fault injection, observation recording, result analysis, and feedback verification. The chaos engineering team at Zhongyuan Bank referred to the five advanced principles of chaos engineering and divided the implementation process of chaos experiments into four main stages during the pilot project.
(1) Preparation Stage. This stage mainly includes preparing experimental scenarios, confirming system steady state indicators, and preparing the environment. Through thorough communication with personnel related to the target system, a comprehensive review of the system architecture, transaction links, etc., is conducted. Based on historical production issues of the target system, fault risk hypotheses are proposed for weak points in the system architecture, experimental scenarios are determined, and steady state indicators that need to be monitored (such as basic resource usage rate, transaction success rate, transaction TPS, etc.) are clarified, ultimately forming an experimental plan.
(2) Conventional Experiment Stage. A control group and an experimental group are set up, using the monitoring indicator data of the control group as a baseline. By randomly or selectively injecting atomic faults such as basic resources or network into the target service, relevant steady state indicators are observed and recorded, filtering out experimental scenarios that do not meet expected results.
(3) Targeted Experiment Stage. For scenarios that do not meet expected results in the conventional experiment stage, as well as those identified in the preparation stage with potential fault risks, targeted experiments are conducted. Relevant steady state indicators are observed and recorded, and the verification of corresponding fault emergency response plans is carried out.
(4) Summary and Review Stage. Based on the records of chaos experiment results, an experimental report is produced, system weak points are analyzed, and continuous tracking and optimization are performed.
Scenario Expansion
Based on the initial chaos engineering application pilot practice, Zhongyuan Bank is further exploring and expanding chaos engineering application scenarios from different perspectives in development, testing, and operations, fully leveraging the value of the chaos engineering platform. Through high availability testing, improved testing methods, and chaos fault drills, issues such as uncertainty in system high availability for development teams, incomplete testing methods for testing teams, and singular fault drill scenarios for operations teams are addressed, continuously deepening chaos engineering application practices (see Figure 3).
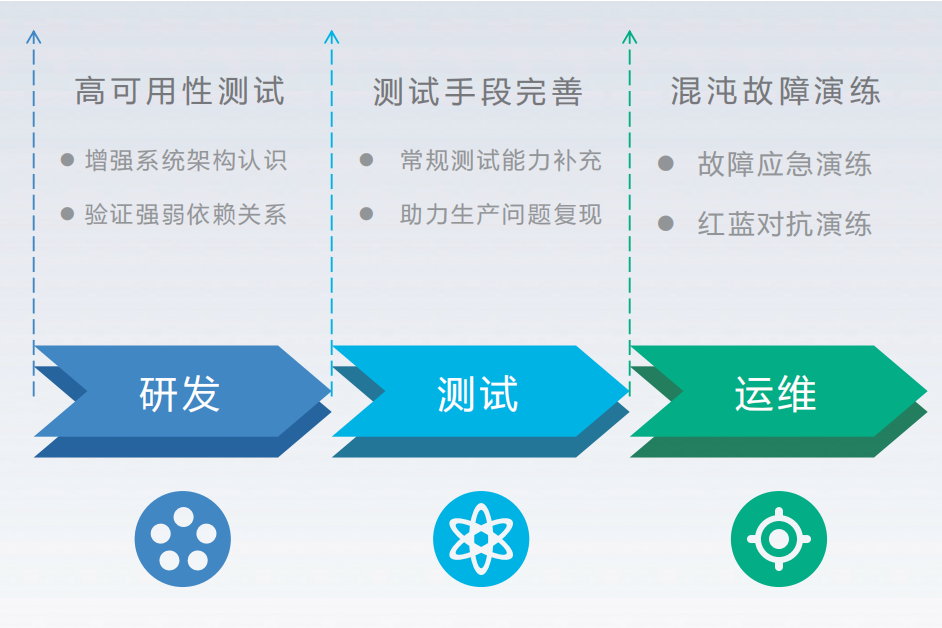
Figure 3 Chaos Engineering Application Practice at Zhongyuan Bank
By exploring the construction of the chaos engineering technical system at Zhongyuan Bank, the continuous optimization of system stability has been effectively promoted, further advocating the chaos engineering culture. Based on the open-source ChaosBlade tool, the chaos engineering team at Zhongyuan Bank has built a chaos engineering technical platform and optimized multiple functions such as containerized environment adaptation, scenario library improvement, and operating system version compatibility, effectively supporting the development of chaos engineering practice applications.
1. High Availability Testing
A cross-functional chaos engineering special team composed of development, operations, and testing personnel has been formed. Based on the standardized process of chaos experiments summarized from application pilot practices, core business scenario transaction links are sorted out based on system importance, historical production event occurrences, and system complexity. Through large-scale chaos experiments in business systems, chaos scenarios with business attributes (e.g., payment, query, etc.) are continuously accumulated, laying a technical foundation for the standardization and automation of high availability testing, and providing chaos asset guarantees for subsequent routine chaos engineering experiments in various systems.
2. Improvement of Testing Methods
On one hand, application systems often encounter exceptions such as interface response timeouts and thread pool saturation during performance and functional testing, which require verification testing. These types of faults are often complicated to configure and may even require code-level modifications, impacting the stability of application versions. Chaos engineering can serve as a supplementary means to traditional testing, quickly meeting corresponding testing needs through the fault injection capabilities of the chaos engineering platform, achieving cost reduction and efficiency improvement.
On the other hand, chaos engineering also has application potential in reproducing and analyzing production issues. For example, as business grew, the message middleware of our bank experienced a decline in service availability for a period, making it difficult to reproduce and locate the problem. After thorough communication with the project team, a series of chaos experiment scenarios were jointly developed. By combining and simulating network packet loss, network delay, and other fault scenarios, the production issue was reproduced, the platform architecture was optimized, and similar issues were effectively avoided in the future.
3. Chaos Fault Drills
Chaos fault drills are mainly divided into two parts: fault emergency drills and red-blue confrontation drills.
Fault emergency drills start from known faults, initiated by the operations management team, to examine the architectural stability of the target system, enhancing monitoring capabilities and personnel emergency response capabilities. Before the drill begins, the production environment architecture needs to be proportionally replicated in the testing environment, and project development personnel are involved to jointly determine the drill time, drill environment, drill plan, and operational step control table. During the drill, the process is recorded in detail. After fault injection, monitoring alarm platform information is observed, and operations are strictly conducted according to the emergency response plan to verify its effectiveness. After the drill, a review summary is conducted, monitoring indicators are checked for gaps, and targeted optimizations and improvements to the emergency response plan are made.
Red-blue confrontation drills start from unknown faults, implementing them during a specific time window. The team is divided into red and blue groups, with testing personnel forming the blue army responsible for developing the chaos drill plan and executing fault injections on the target system. System developers and operations personnel form the red army, responsible for discovering faults, emergency responses, and fault elimination. This comprehensive verification assesses the system’s fault tolerance, monitoring capabilities, personnel response capabilities, and recovery capabilities under different fault scenarios. The aforementioned confrontation drill mechanism can drive developers to continuously improve system stability and proactively conduct chaos engineering experiments. Through these routine confrontation drills, the team’s ability and confidence to withstand production operation risks are gradually enhanced.
Future Plans
Next, the chaos engineering team at Zhongyuan Bank plans to build on the chaos technology assets accumulated in the early stages, deeply carry out practices from three aspects: stability assurance, product construction, and personnel culture, comprehensively accelerating the implementation of routine chaos engineering practices, striving to improve practice quality and effectiveness, and continuously enhancing system stability and business continuity.
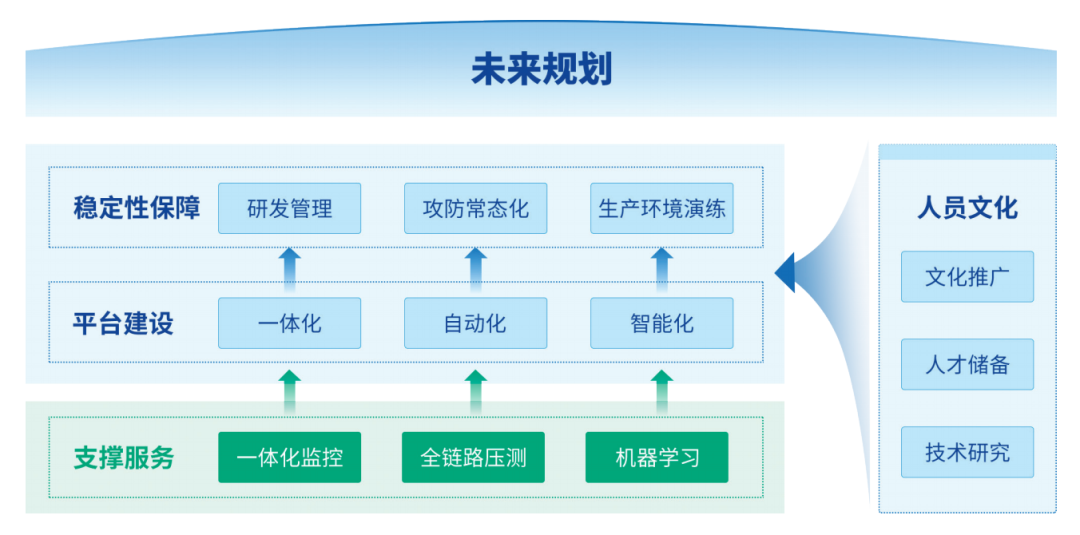
Figure 4 Construction Plan for Chaos Engineering at Zhongyuan Bank
In terms of stability assurance, relying on the DevOps development management platform, stability assurance mechanisms will be integrated into various stages of the software development cycle. Stability architecture reviews will be added during the design phase, chaos engineering experiments will be introduced during the testing phase, and chaos engineering experiment access control processes will be implemented for major system changes. At the same time, the routine red-blue offensive and defensive drill mechanism based on the chaos engineering platform will continue to be promoted. With the accumulation of chaos engineering experiment experience, the controllability of the experiment’s “explosion radius” will be enhanced, and timely exploration of chaos fault drills in the production environment will be conducted.
In terms of platform construction, continuous deepening of platform iterative construction will be pursued, aiming for integration, automation, and intelligence. An integrated monitoring platform and a full-link pressure testing platform will be established to achieve closed-loop full-process management operations for chaos experiments. The fault scenario library will be continuously improved, and the management of plans and reports will be fully digitized, accumulating chaos experiment scenarios, enhancing the platform’s automated experiment capabilities, and improving chaos experiment efficiency. Attempts will be made to organically combine with big data and machine learning technologies to explore the intelligent implementation of chaos engineering experiments, further tapping into the application potential of chaos engineering.
In terms of personnel culture, a chaos engineering talent reserve pool will be established, and continuous deepening of chaos engineering technical research will be pursued. The chaos engineering culture will be promoted through training, sharing, and communication methods, enhancing the understanding and acceptance of chaos engineering among technical personnel, forming a positive feedback mechanism that promotes culture through advocacy and vice versa.
Looking to the future, the technology team at Zhongyuan Bank will adhere to the development philosophy of “caring service, creating value, excellent technology, and intelligent future,” continuously enhancing business service capabilities and empowering business transformation and development. The bank will deepen the construction of cloud-based infrastructure and the transformation to distributed architecture, continuously promote the application practices of chaos engineering, enhance the level of system stability assurance, and solidify the foundation for digital transformation development, ensuring high-quality development for Zhongyuan Bank’s business.
(Column Editor: Zhang Lixia)
Selected Previous Articles:
(Click to view exciting content)
● Practical | Exploration and Thoughts on Privacy Computing at Bank of Communications
● Practical | Construction Practice of Integrated Data Service Architecture at Small and Medium-sized City Commercial Banks
● Practical | Integrated Data Lake Supports Ping An Property & Casualty’s Digital Transformation
● Practical | Deepening “Lake and Warehouse Integration” to Solidify Data Application Foundation
● Practical | Based on Technological Innovation, Coexistence Practice of Lake and Warehouse Integration









New Media Center: Director / Kuang Yuan Editor / Fu Tiantian Zhang Jun Tai Siqi
