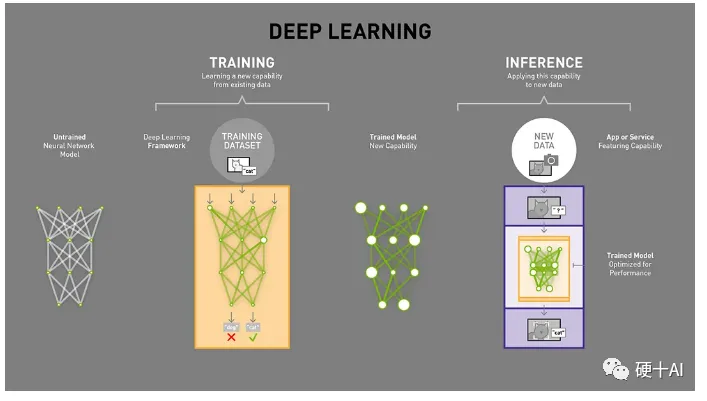
The Xiangteng NPU chip is an AI chip designed for inference.When applying artificial intelligence, we encounter two concepts: Training and Inference, which are two stages in the implementation of AI. Let’s first understand these two issues.
- What is the difference between training and inference?
- What key points should we focus on to distinguish between AI training and inference chips/products?
1. What is the difference between training and inference?
- The training process (also known as the learning process) refers to the process of training a complex neural network model using large datasets, determining the values of weights and biases in the network through extensive data training, enabling it to adapt to specific functions. During training, the neural network weights need to be adjusted to minimize the loss function, and training is executed through backpropagation to update the weights in each layer. The training process requires high computational performance, massive amounts of data, and the trained network has a certain level of generality.
-
The inference process (also known as the judgment process) refers to using the trained model to infer conclusions from new data. Inference is the process of prediction and deduction, utilizing the neural network model with parameters determined during training to perform calculations, classifying the new input data in a one-time manner, and outputting the predicted results.
We can compare this to our own learning process, where we use the knowledge we have acquired to make judgments. The learning process (i.e., the training process) is as follows: when we start learning a new subject in school, to master a large amount of knowledge, we must read extensively, listen attentively to the teacher’s explanations, and do a lot of exercises after class to consolidate our understanding of the knowledge. We also verify our learning results through exams. Only when we pass the exam can we consider the entire learning process complete. In each exam, some students score high while others score low, which reflects the differences in learning outcomes. Of course, if you unfortunately fail the exam, you must continue to relearn and improve your understanding of the knowledge until you eventually pass. The judgment process (i.e., the inference process) is as follows: we apply the knowledge we have learned to make judgments. For example, if you graduate from medical school and begin your work in healing, your judgment of a patient’s condition is your “inference” work. If you diagnose 100 patients and accurately identify the cause in 99 cases, everyone praises you as a good doctor, indicating that you have successfully applied your knowledge and made accurate judgments.
In summary, the training and inference processes in artificial intelligence are very similar to the learning and judgment processes in the human brain. Typically, it takes a long time to learn (i.e., train), while making judgments (i.e., inference) can be done in an instant.
2. What key points should we focus on to distinguish between AI training and inference chips/products? Depending on the tasks they undertake, AI chips or products can be divided into two categories: training AI chips and inference AI chips, with the main differences as follows.(1) Different deployment locations Most training chips are located in the cloud, deployed in data centers, utilizing massive data and complex neural networks for model training. These chips are quite complex. Currently, besides chip companies like NVIDIA, AMD, and Intel, internet companies like Google also have cloud training chips, and domestic companies like Huawei, Cambricon, and Muxi are also developing cloud training chips. Many inference chips are also placed in the cloud, with many servers in data centers configured with inference PCIE cards, and a large number of inference chips are used on the edge (various devices outside data centers), such as autonomous vehicles, robots, smartphones, drones, or IoT devices, which all use trained models for inference. There are more companies deploying cloud inference chips and edge inference chips, with a wider variety of products and higher levels of customization.The Xiangteng NPU chip is a typical AI chip designed for edge inference.(2) Different performance requirements
- Different accuracy/precision requirements
We evaluate the performance of an AI system based on metrics such as accuracy/precision. For example, if it can predict 85 out of 100 samples, the accuracy rate is 85%. AI algorithms are based on probability theory and statistics, and it is impossible to achieve 100% prediction accuracy. Moreover, achieving higher accuracy requires greater effort and cost. The data precision we often mention also directly affects system accuracy. We can compare data precision to the pixel count in a photo; the more pixels, the higher the resolution. Similarly, higher precision means a more accurate representation of things. Increasing precision also comes at a cost, requiring the system to provide more memory and take longer processing time. For instance, data shows that using int4 precision can achieve a 59% speedup compared to int8. In practical applications, higher accuracy is not always better, nor is higher supported data precision always better. Different application scenarios have different requirements for performance metrics. For example, in image recognition applications, such as tracking customers in a retail store as they pass through an aisle, an error margin of 5% to 10% is acceptable; however, in applications like medical diagnosis or automotive vision, the accuracy requirements are much higher, and low accuracy renders them unusable. In summary, different applications have different tolerances for accuracy and precision, requiring us to make trade-offs. Returning to inference and training products, there are significant differences in selection. For example, in edge inference products, since the accuracy requirement is not high, we may only need to support int8 or even lower precision. However, for training products, such as those used in high-performance computing (HPC) scenarios, they must be capable of achieving high accuracy, and the range of supported data precision needs to be richer, such as needing to support FP32 and FP64 precision data.
- Different computational requirements
Training requires intensive computation. After calculating results through the neural network, if an error is found or the expected outcome is not achieved, this error will be backpropagated through the network layers (refer to Machine Learning Function (3) – “Gradient Descent” Shortcuts, “BP Algorithm” Efficiency), and the network needs to attempt new predictions. In each attempt, it must adjust a large number of parameters while considering other attributes. After making another prediction, it must be verified again, going through this back-and-forth process until it achieves the “optimal” weight configuration, reaching the expected correct answer. Nowadays, the complexity of neural networks is increasing, with the number of parameters in a network exceeding millions. Therefore, each adjustment requires a significant amount of computation. Research conducted at Stanford University and experience at Google and Baidu have shown that “training a Chinese speech recognition model at Baidu requires not only 4TB of training data but also 20 exaflops (20 billion billion floating-point operations) of computing power throughout the training cycle,” indicating that training is a monster that consumes massive computing power. However, with continuous model optimization, training efficiency is also improving. Inference utilizes the trained model to infer various conclusions from new data. It performs calculations using the neural network model, obtaining correct conclusions from the input new data in a one-time manner. It does not require the iterative parameter adjustments needed in training, thus requiring significantly less computing power.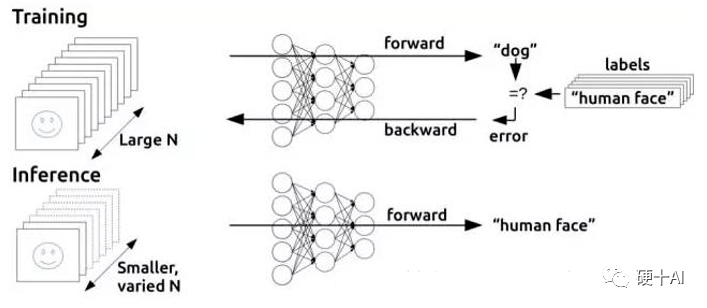
- Different storage requirements
During training, backpropagation adjustments will apply to the intermediate results of feedforward network calculations, requiring large video memory. The design and usage of storage for training chips are complex. The trained model requires a large amount of data, which must be loaded into video memory, necessitating sufficient video memory bandwidth and low latency. Additionally, in neural network training, we use gradient descent algorithms, and in video memory, we need to load not only model parameters but also save the intermediate states of gradient information. Therefore, training requires significantly more video memory than inference, and sufficient video memory is essential for operation.
In summary, the deployment locations of training and inference chips/products differ, as do the performance accuracy and precision requirements, computational capabilities, and storage size requirements. Besides these key indicator differences, chips used in training scenarios require high precision and high throughput, resulting in high power consumption (even reaching 300W), and these chips are also costly; chips used for cloud inference focus more on balancing computing power and latency, and are very sensitive to power costs. For example, NVIDIA’s products do not develop dedicated inference cards for each generation; instead, they use lower-spec versions of training cards for inference. However, edge application inference chips must be tailored to the application scenario, achieving low power consumption and low cost..
3. How do we learn about training and inference in artificial intelligence? To understand artificial intelligence, it is essential to master knowledge related to both training and inference. If you only learn how to build networks and adjust parameters in “training,” you will not understand how “inference” plays a role in practical applications; you will lack real-world relevance. Similarly, if you have only performed “inference” operations, you will not understand the preparatory work required to achieve inference judgments, which involves extensive calculations to train a high-performance neural network. Hard Ten is actively promoting the Xiangteng NPU chip’s open-source hardware development board, with the main chip HKN201 being an AI inference chip designed for strong real-time, high-performance, and high-concurrency application requirements. It can be applied in scenarios such as edge computing in parks, industrial inspection and control, and intelligent recognition and control in robotics. For detailed information, refer to Hard Ten Classroom, scan the QR code to enterhttps://www.hw100k.com/coursedetail?id=271
For detailed information, refer to Hard Ten Classroom, scan the QR code to enterhttps://www.hw100k.com/coursedetail?id=271
Contact information for chip consultation and procurement

