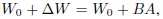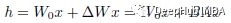Source: DeepHub IMBA
This article is approximately 1000 words and is recommended to be read in 5 minutes.
Low-Rank Adaptation significantly reduces the number of trainable parameters for downstream tasks.
For large models, it becomes impractical to fine-tune all model parameters. For example, GPT-3 has 175 billion parameters, making both fine-tuning and model deployment impossible. Therefore, Microsoft proposed Low-Rank Adaptation (LoRA), which freezes the pre-trained model weights and injects a trainable low-rank decomposition matrix into each layer of the Transformer architecture, significantly reducing the number of trainable parameters for downstream tasks.
LoRA
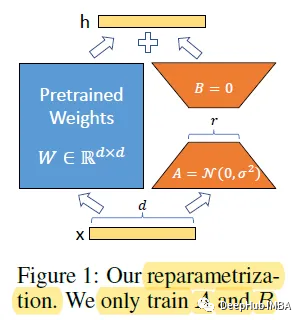
For the pre-trained weight matrix W0, we can constrain its updates by using a low-rank decomposition representation:
During training, W0 is frozen and does not accept gradient updates, while A and B contain trainable parameters. When h=W0x, the modified forward propagation becomes:
Random Gaussian initialization is used for A, while zero initialization is used for B, therefore ΔW=BA is zero at the start of training (this is important to note).
One advantage of this method is that when deployed in production environments, it only requires the computation and storage of W=W0+BA, and inference can be executed as usual. Compared to other methods, there is no additional latency since no extra layers need to be added.
In the Transformer architecture, there are four weight matrices (Wq, Wk, Wv, Wo) in the self-attention module, and two weight matrices in the MLP module. LoRA only adjusts the attention weights for downstream tasks and freezes the MLP module. Therefore, for large Transformers, using LoRA can reduce VRAM usage by up to 2/3. For example, on GPT-3 175B, using LoRA can decrease VRAM consumption during training from 1.2TB to 350GB.
Results Display
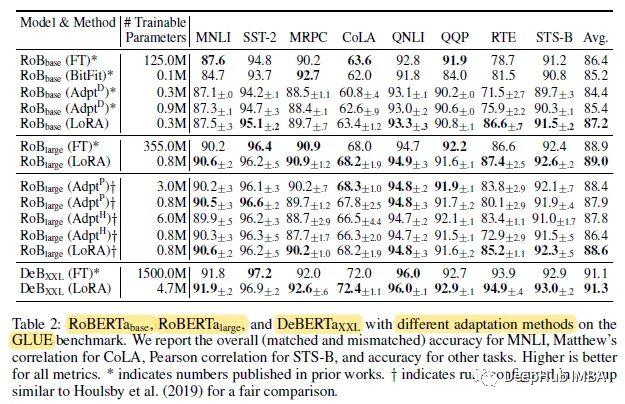
Evaluations were conducted using pre-trained RoBERTa base (125M), RoBERTa large (355M), and DeBERTa XXL (1.5B) from the HuggingFace Transformers library. They were fine-tuned using different fine-tuning methods.
In most cases, using LoRA achieved the best performance on GLUE.
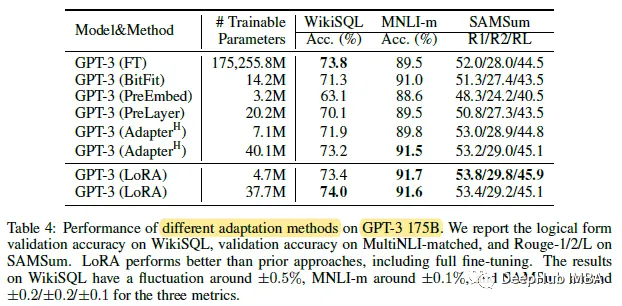
Comparison of the number of trainable parameters for various adaptive methods on GPT-3 175B for WikiSQL and MNLI matching.
It can be seen that using GPT-3, LoRA matches or exceeds the fine-tuning baselines for all three datasets.
Stable Diffusion
LoRA was first applied to large language models, but it may be more widely known for its application in Stable Diffusion:
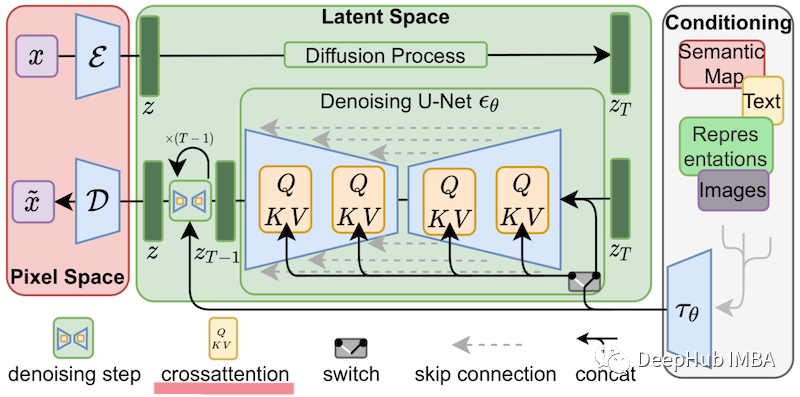
In the case of fine-tuning Stable Diffusion, LoRA can be applied to the cross-attention layers that connect image representations with the prompts that describe them. The details in the image below are not important; just know that the yellow blocks are responsible for constructing the relationship between image and text representations.
Thus, the custom LoRA models trained in this way will be very small.
My personal experiment: Full fine-tuning of Stable Diffusion requires at least 24GB of GPU memory. However, using LoRA, single-process training with a batch size of 2 can be completed on a single 12GB GPU (10GB without xformer, 6GB with xformer).
Therefore, LoRA is also a very effective fine-tuning method in the field of image generation. If you want to learn more, here is the link to the paper:
https://openreview.net/forum?id=nZeVKeeFYf9
Editor: Wenjing