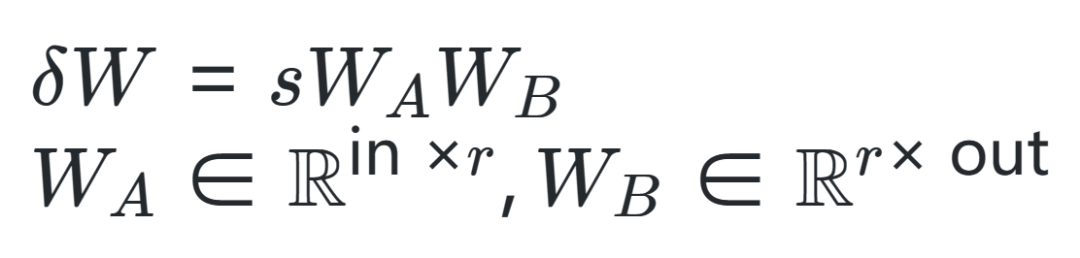ReLoRA: Efficient Large Model Training Through Low-Rank Updates
This article focuses on reducing the training costs of large Transformer language models. The author introduces a low-rank update-based method called ReLoRA. A core principle in the development of deep learning over the past decade has been to “stack more layers,” and the author aims to explore whether stacking can similarly enhance training efficiency for low-rank adaptation. Experimental results show that ReLoRA is more effective in improving the training of large networks.
Paper link:https://arxiv.org/abs/2307.05695Code repository:https://github.com/guitaricet/peft_pretraining
For some time now, researchers in the large language models (LLMs) community have begun to focus on how to reduce the enormous computational power required for training, fine-tuning, and inference of LLMs, which is crucial for advancing LLMs in more vertical domains. Currently, there are many pioneering works in this direction, such as the RWKV model, which innovates by replacing the computationally intensive Transformer architecture with a new architecture based on the RNN paradigm. There are also methods that focus on the fine-tuning phase of the model, such as adding smaller Adapter modules to the original LLMs for fine-tuning. Additionally, Microsoft proposed the Low-Rank Adaptation (LoRA) method, which assumes that the amount of weight updates during task adaptation can be estimated using low-rank matrices, thereby optimizing the newly added lightweight adaptation modules while keeping the original pre-trained weights unchanged. LoRA has become an essential fine-tuning skill for large model engineers, but the author of this article is not satisfied with the current fine-tuning performance that LoRA can achieve and further proposes a stackable low-rank fine-tuning method called ReLoRA.
This article comes from a research team at the University of Massachusetts Lowell. When the author team applied ReLoRA to a Transformer with up to 350M parameters, it demonstrated performance comparable to conventional neural network training. Furthermore, the authors observed that the fine-tuning efficiency of ReLoRA increases with the scale of model parameters, making it a potential new method for training ultra-large-scale (typically over 1B parameters) LLMs in the future.
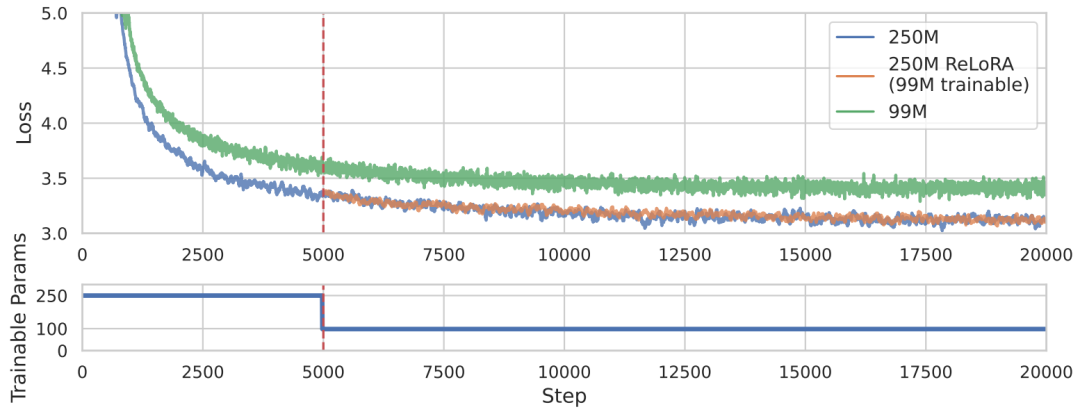
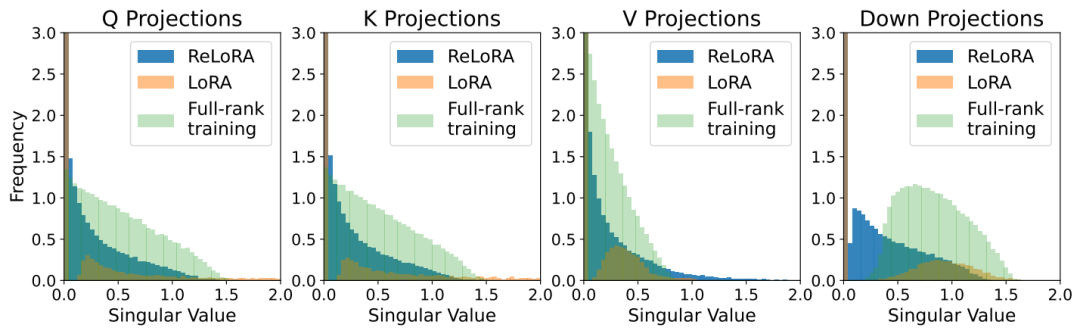
1. IntroductionAlthough various foundational models are continuously being released by academia and industry, it is undeniable that fully pre-training an LLM with elementary reasoning capabilities still requires enormous computational power. For example, the well-known LLaMA-6B model[1] requires hundreds of GPUs to complete training. Such a scale of computation has deterred most academic research teams. In this context, Parameter-Efficient Fine-Tuning (PEFT) has become a very promising research direction for LLMs. Specifically, PEFT methods can fine-tune billion-scale language or diffusion models on consumer-grade GPUs (such as RTX 3090 or 4090). Therefore, this article focuses on low-rank training techniques within PEFT, especially the LoRA method. The author reflects on a core principle in the development of deep learning over the past decade, which is to “stack more layers,” for example, the introduction of ResNet allows us to increase the depth of convolutional neural networks to over 100 layers, achieving very good results. Thus, this article explores whether stacking can similarly enhance the training efficiency of low-rank adaptation.This article proposes a low-rank update-based ReLoRA method to train and fine-tune high-rank networks, outperforming networks with the same number of trainable parameters, and even achieving performance similar to that of training full networks with over 100M parameters, as shown in the figure above. Specifically, the ReLoRA method includes (1) full-rank initialization, (2) LoRA training, (3) parameter restart, (4) jagged learning rate schedule, and (5) partial reset of optimizer parameters. The author chooses the currently popular autoregressive language model for experiments, ensuring that the GPU computation time for each experiment does not exceed 8 days.2. MethodologyThe author starts from the rank of the sum of two matrices. Generally speaking, the upper bound of the rank of the sum of matrices is tighter. For matrices, there exists a matrix such that the rank of the sum of the matrices is greater than or.The author aims to utilize this property to devise a flexible parameter-efficient training method, starting with the LoRA algorithm. LoRA can decompose the amount of model weight updates into a product of low-rank matrices, as shown in the following formula, where is a fixed scaling factor.
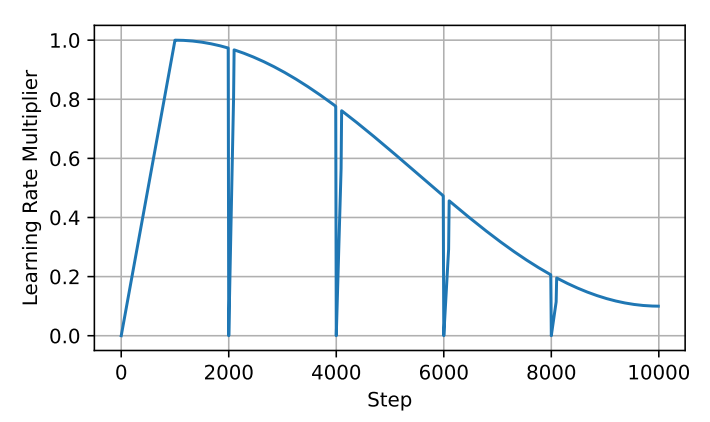
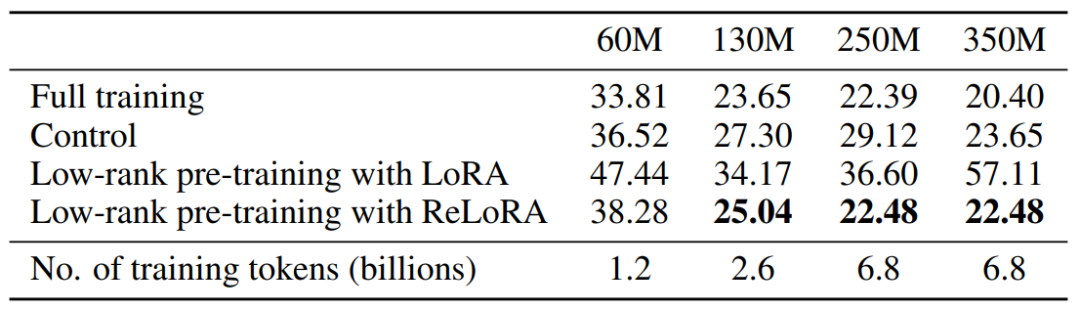
In practice, LoRA typically adds new learnable parameters and to achieve this, which can be merged back into the original parameters after training. Therefore, although the above equation allows us to achieve a total parameter update amount greater than the rank of any single matrix during the training phase, it is still limited by .The author thought of continuously stacking this process to break through the limitations and achieve better training results.This first requires restarting the LoRA process, which allows the accumulated weight updates from each iteration to be merged during the training phase, as shown in the following formula:However, restarting the completed LoRA process is not easy. This requires fine-tuning the optimizer; if adjustments are not properly made, it can lead to the model diverging from the previous optimization direction immediately after the restart. For example, the Adam optimizer is primarily guided by the first and second moments of accumulated gradients from previous steps. In practice, the gradient matrix smoothing parameters and are usually very high, leading to an upper bound of rank during restarts, and the corresponding gradient matrices and are full-rank. After merging parameters, the old gradients will be used to optimize towards the same subspace direction as.To address this issue, the author proposes the ReLoRA method. During merging and restarting, ReLoRA can partially reset the optimizer and set the learning rate to 0 during the subsequent warm-up process.Specifically, the author proposes a jagged learning rate scheduling algorithm, as shown in the figure below. Each time the ReLoRA parameters are reset, the learning rate is set to zero, and a rapid (50-100 steps) learning rate warm-up is performed to return it to the same level range as before the reset.ReLoRA achieves performance comparable to full-rank training by training only a small set of parameters through sequential stacking, while adhering to the foundational principles of the LoRA method, which is to keep the original network’s frozen weights and add new trainable parameters. At first glance, this approach may seem computationally inefficient, but it is important to understand that this method can significantly improve memory efficiency by reducing the size of gradients and optimizer states. For example, the memory consumed by the Adam optimizer state is typically twice that of the model weights. By drastically reducing the number of trainable parameters, ReLoRA can utilize larger batch sizes under the same memory conditions, maximizing hardware efficiency. The overall operational details of ReLoRA are shown in the figure below.3. Experimental ResultsTo clearly evaluate the performance of the ReLoRA method, the author applied it to Transformer models of various sizes (60M, 130M, 250M, and 350M) and conducted training and testing on the C4 dataset. To demonstrate the universality of the ReLoRA method, the author focused on basic language modeling tasks in the NLP field. The model architecture and training hyperparameters were kept consistent with the LLaMA model. Unlike LLaMA, the author replaced the original attention mechanism (using float32 for softmax computation) with Flash Attention[2] and used bfloat16 precision for calculations. This approach can increase training throughput by 50-100% without any training stability issues. Additionally, the model parameters trained using the ReLoRA method are significantly smaller compared to LLaMA, with the largest model having only 350M parameters, which can be completed in one day of training on 8 RTX 4090s.The figure below shows the performance comparison between this method and other methods. It can be seen that ReLoRA significantly outperforms the low-rank LoRA method, proving the effectiveness of our proposed modifications. Moreover, ReLoRA achieves performance comparable to full-rank training (Full training), and we can observe that as the network scale increases, the performance gap gradually narrows. Interestingly, the only baseline model that ReLoRA cannot surpass is the smallest model with only 60M parameters. This observation indicates that ReLoRA is more effective in improving the training of large networks, which aligns with the author’s initial goal of exploring improved training methods for large networks.Furthermore, to further assess whether ReLoRA can achieve higher rank updates in training through iterative low-rank updates compared to LoRA, the author plotted the singular value spectra of the differences between the warm-start weights and final weights of ReLoRA, LoRA, and full-rank training. The figure below illustrates the significant differences in singular values for ,,, and between LoRA and ReLoRA.It can be seen that ReLoRA achieves the smallest singular values across all four matrix parameters.4. ConclusionThis article focuses on reducing the training costs of large Transformer language models, selecting a very promising direction: low-rank training techniques. Starting from the most basic low-rank matrix decomposition (LoRA) method, the author utilizes multiple stacked low-rank update matrices to train high-rank networks. To achieve this, the author meticulously designs a series of operations, including parameter restarting, jagged learning rate scheduling, and optimizer parameter resetting, which collectively enhance the training efficiency of the ReLoRA algorithm, achieving performance comparable to full-rank training in some cases, especially in ultra-large-scale Transformer networks. The author provides extensive experimental evidence for the feasibility and operational effectiveness of the ReLoRA algorithm. Will ReLoRA also become an essential algorithm skill for large model engineers?References[1] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[2] T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Re. Flashattention: Fast and memory-efficient exact attention with IO-awareness. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors, Advances in Neural Information Processing Systems, 2022.
Author: seven_
Illustration by IconScout Store from IconScout
-The End-
Scan to view!
New this week!
“AI Technology Stream” Original Submission Plan
TechBeat is an AI learning community established by Jiangmen Venture Capital (www.techbeat.net). The community has launched over 480 talk videos and more than 2400 technical articles, covering areas such as CV/NLP/ML/Robotics; regularly hosting top conferences and other online communication activities, and occasionally organizing offline gatherings for technical professionals. We strive to become a high-quality, knowledge-based communication platform favored by AI talents, aiming to provide more professional services and experiences for AI talents, accelerating and accompanying their growth.
Submissions must be original articles and include author information.
We will select some articles that provide greater inspiration to users in the direction of deep technical analysis and scientific insights for original content rewards.
or add staff WeChat (chemn493) to submit and discuss submission details; you can also follow the “Jiangmen Venture Capital” public account and reply “submission” in the backend to receive submission instructions.
>>> Add the editor on WeChat!
About Us “Door”▼Jiangmen is a new venture capital institution focusing oncore technologies in digital intelligence, and is also abenchmark incubator in Beijing. The company is dedicated to connecting technology with business, discovering and nurturing globally influential technology innovation enterprises, and promoting innovation development and industrial upgrading.Established at the end of 2015, the founding team was built by the original team of Microsoft Ventures in China, which has selected and deeply incubated 126 innovative technology startups.If you are a startup in the technology field looking not only for investment but also for a series of ongoing, valuable post-investment services,welcome to send or recommend projects to us “Door”:[email protected]Click the top right corner to share this article with friendsClick the “Read Original” button to view the original article in the community⤵ One-click to send you to TechBeat’s happy planet